9. Aprendizaje No Supervisado
Por que importa en competencias de IA
El aprendizaje no supervisado aparece en competencias de dos formas principales:
- Como paso de feature engineering: crear etiquetas de cluster, distancias a centroides o componentes PCA para mejorar modelos supervisados
- Como objetivo directo: segmentacion de clientes, deteccion de anomalias, reduccion de dimensionalidad antes de visualizar
Saber cuando y como aplicar clustering o PCA puede darte features que ningun equipo rival tiene.
Mapa de este tema:
- K-Means: intuicion, algoritmo y limitaciones
- Metodo del codo y silhouette para elegir k
- DBSCAN: clustering basado en densidad
- Clustering jerarquico y dendrogramas
- PCA: reduccion de dimensionalidad y varianza explicada
- t-SNE y UMAP para visualizacion
- Clusters como features para modelos supervisados
- Mini-proyecto: segmentacion de clientes
1. K-Means: el algoritmo mas usado
K-Means agrupa datos minimizando la inercia (suma de distancias al cuadrado de cada punto a su centroide):
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_blobs
from sklearn.metrics import silhouette_score
np.random.seed(42)
# Datos con 4 clusters naturales
X, y_true = make_blobs(n_samples=500, centers=4, cluster_std=0.9, random_state=42)
# SIEMPRE escalar antes de clusterizar
scaler = StandardScaler()
X_sc = scaler.fit_transform(X)
# Entrenar K-Means
km = KMeans(
n_clusters=4,
init='k-means++', # inicializacion inteligente (evita minimos locales)
n_init=10, # repetir 10 veces con distintas semillas
max_iter=300,
random_state=42
)
labels = km.fit_predict(X_sc)
print(f"Inercia: {km.inertia_:.2f}")
print(f"Silhouette: {silhouette_score(X_sc, labels):.4f}")
print(f"Centroides:\n{km.cluster_centers_}")
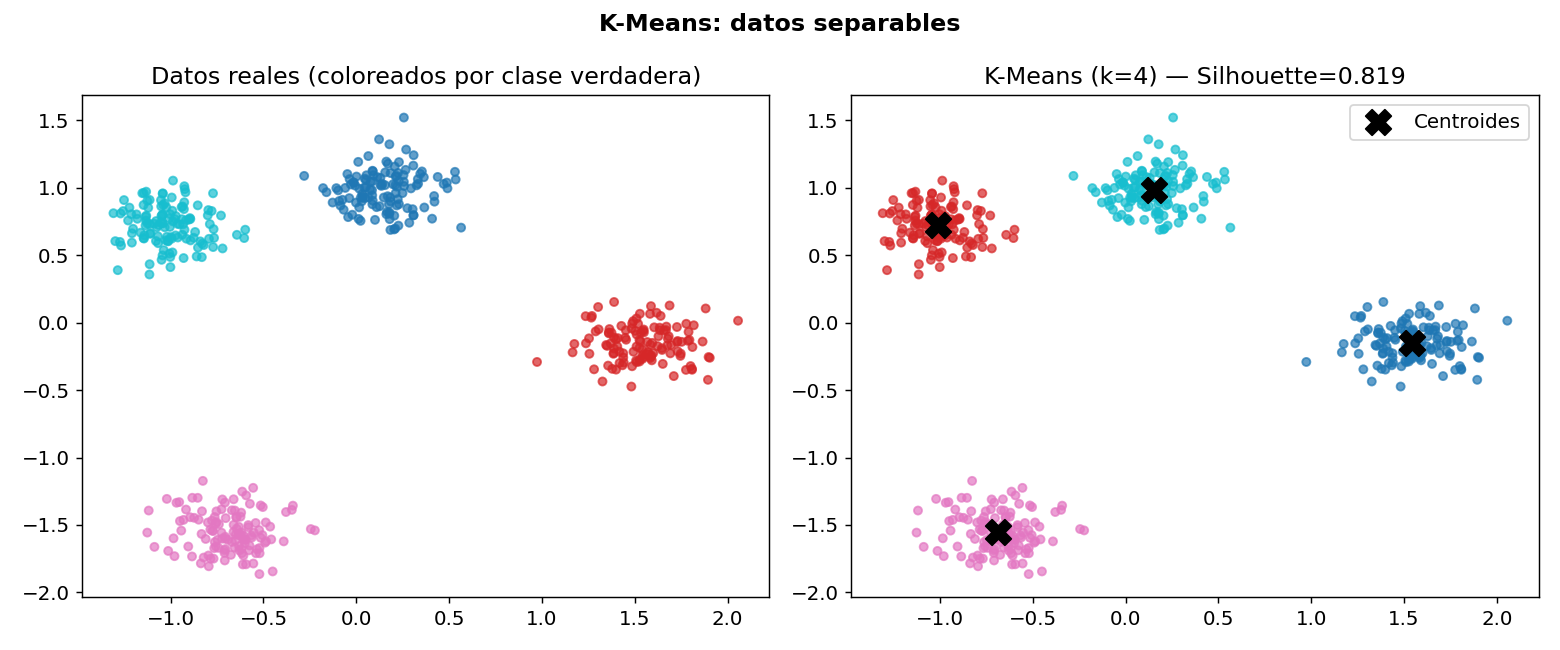
El panel izquierdo muestra los clusters reales y el derecho los predichos por K-Means con sus centroides marcados con X. La asignacion es casi perfecta.
Algoritmo paso a paso:
# Implementacion manual de K-Means para entender el algoritmo
def kmeans_manual(X, k, n_iter=50, seed=0):
rng = np.random.RandomState(seed)
# 1. Inicializar centroides aleatoriamente
centroids = X[rng.choice(len(X), k, replace=False)]
for _ in range(n_iter):
# 2. Asignar cada punto al centroide mas cercano
dists = np.linalg.norm(X[:, None] - centroids[None, :], axis=2)
labels = np.argmin(dists, axis=1)
# 3. Actualizar centroides como media de cada cluster
new_centroids = np.array([X[labels == j].mean(axis=0) for j in range(k)])
# 4. Parar si los centroides no se mueven
if np.allclose(centroids, new_centroids):
break
centroids = new_centroids
return labels, centroids
labels_m, cents_m = kmeans_manual(X_sc, k=4)
print(f"Silhouette manual: {silhouette_score(X_sc, labels_m):.4f}")
Limitaciones de K-Means:
- Asume clusters esfericos y de tamaño similar
- Sensible a outliers (distorsionan los centroides)
- Requiere especificar k de antemano
- No funciona bien en clusters no convexos (lunas, anillos)
2. Elegir el numero de clusters: codo y silhouette
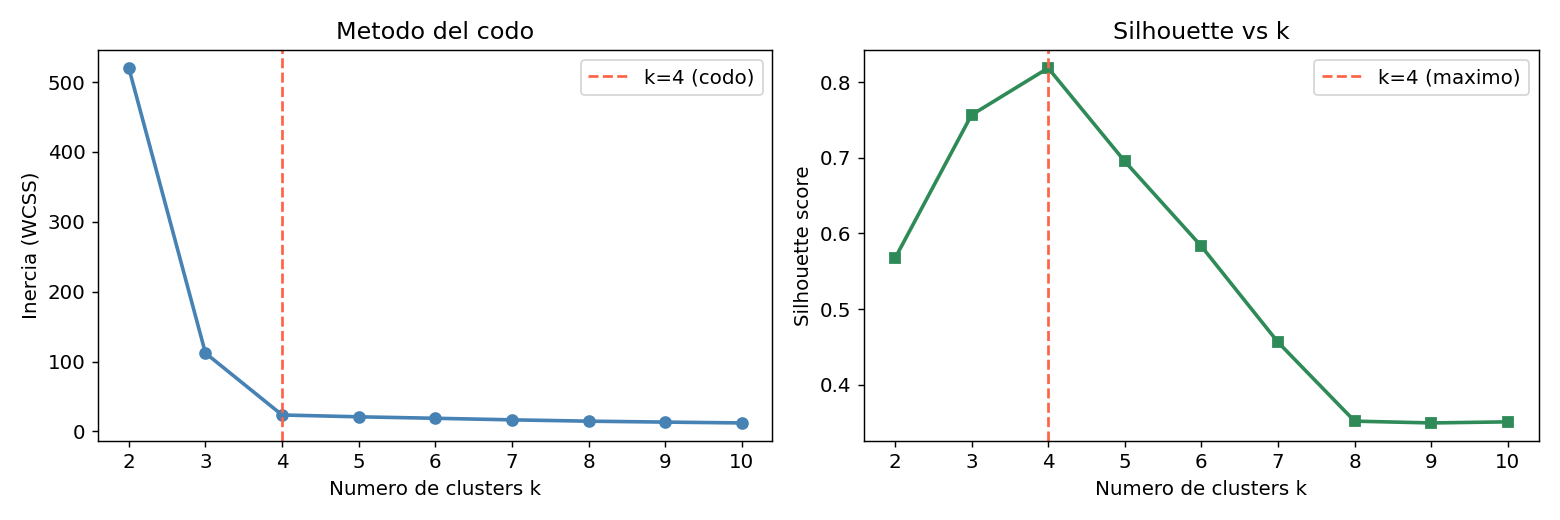
# Metodo del codo: busca el "quiebre" en la curva de inercia
# Silhouette: busca el maximo (mas alto = clusters mas separados y compactos)
inertias, sil_scores = [], []
for k in range(2, 11):
km_k = KMeans(n_clusters=k, random_state=42, n_init=10)
lbl = km_k.fit_predict(X_sc)
inertias.append(km_k.inertia_)
sil_scores.append(silhouette_score(X_sc, lbl))
# El codo esta donde la inercia deja de bajar bruscamente
# El silhouette maximo coincide con k=4
# Automatizar deteccion del codo con KneeLocator
# pip install kneed
from kneed import KneeLocator
kl = KneeLocator(range(2, 11), inertias, curve='convex', direction='decreasing')
print(f"Codo en k={kl.knee}")
Silhouette plot por cluster
from sklearn.metrics import silhouette_samples
sil_vals = silhouette_samples(X_sc, labels)
fig, ax = plt.subplots(figsize=(8, 5))
y_lower = 10
for i in range(4):
ith_sil = np.sort(sil_vals[labels == i])
y_upper = y_lower + len(ith_sil)
ax.fill_betweenx(np.arange(y_lower, y_upper), 0, ith_sil, alpha=0.7, label=f'Cluster {i}')
y_lower = y_upper + 5
ax.axvline(silhouette_score(X_sc, labels), color='red', linestyle='--',
label=f'Score medio = {silhouette_score(X_sc, labels):.3f}')
ax.set_xlabel('Silhouette coefficient')
ax.set_title('Silhouette plot por cluster')
ax.legend()
plt.show()
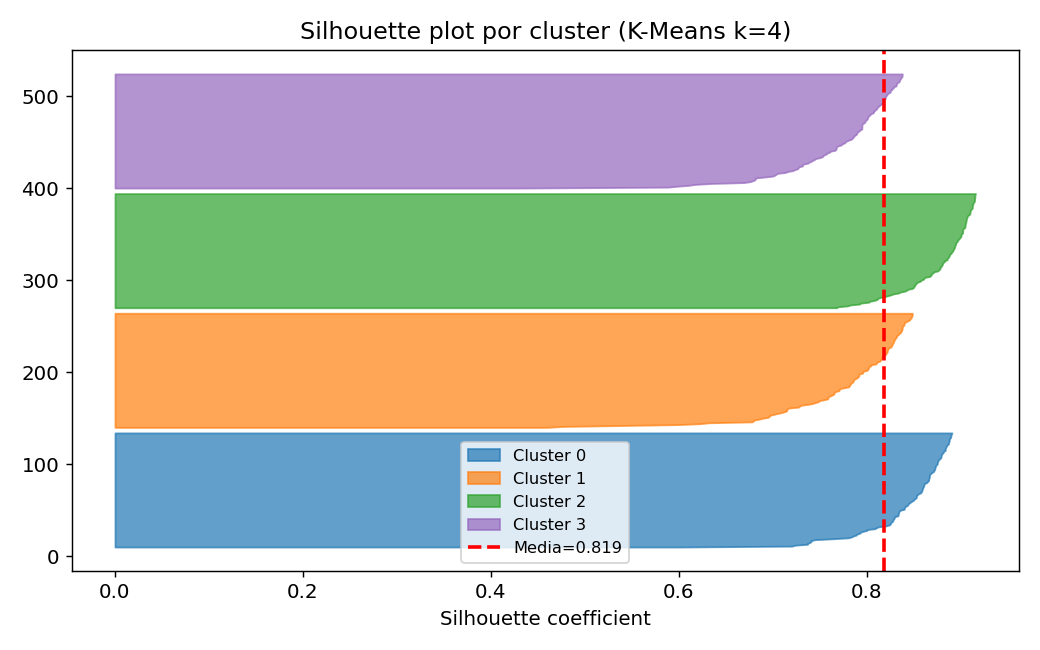
Un cluster con silhouette alto y uniforme esta bien definido. Barras cortas o negativas indican que puntos podrian pertenecer a otro cluster.
3. DBSCAN: clustering basado en densidad
DBSCAN no necesita especificar k y detecta clusters de forma arbitraria. Clasifica puntos en: core, border y ruido.
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons
# Datos en forma de luna (K-Means falla aqui)
X_moons, _ = make_moons(n_samples=400, noise=0.08, random_state=42)
X_moons_s = StandardScaler().fit_transform(X_moons)
# DBSCAN
db = DBSCAN(
eps=0.25, # radio del vecindario
min_samples=5 # minimo de puntos para ser core point
)
labels_db = db.fit_predict(X_moons_s)
n_clusters = len(set(labels_db)) - (1 if -1 in labels_db else 0)
n_noise = np.sum(labels_db == -1)
print(f"Clusters encontrados: {n_clusters}")
print(f"Puntos de ruido: {n_noise}")
print(f"Silhouette: {silhouette_score(X_moons_s, labels_db):.4f}")
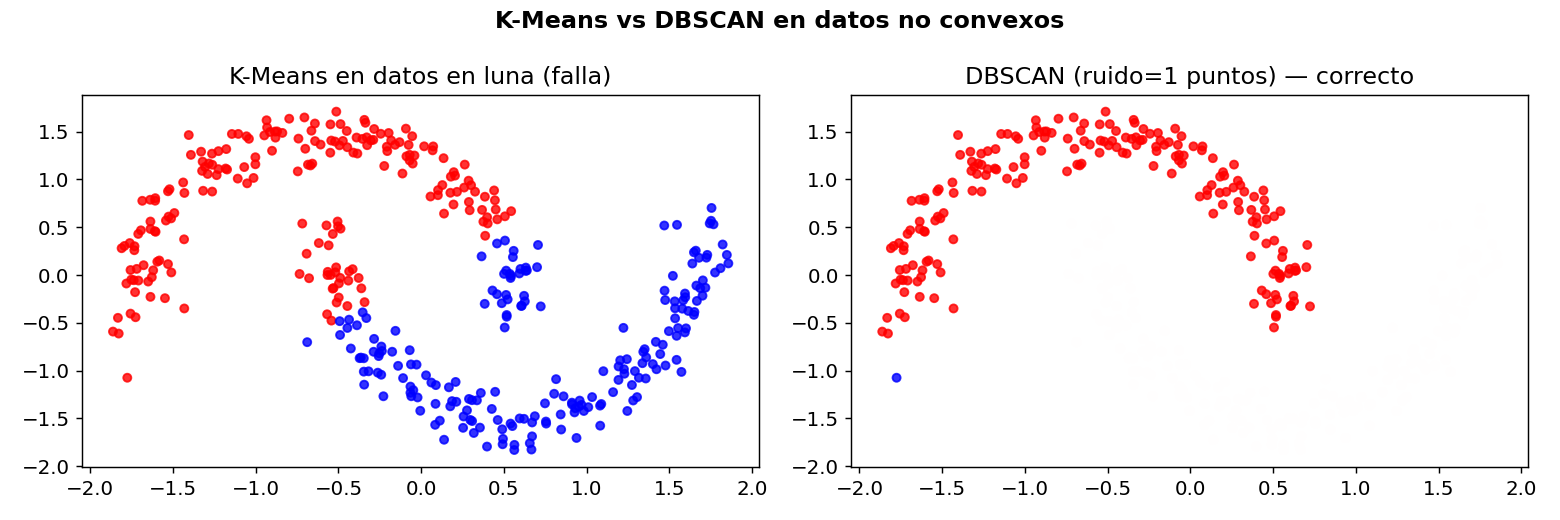
K-Means divide mal los datos en forma de luna porque asume clusters esfericos. DBSCAN los separa perfectamente siguiendo la densidad.
Como elegir eps para DBSCAN
from sklearn.neighbors import NearestNeighbors
# Graficar distancias al k-esimo vecino mas cercano
k = 5 # = min_samples
nbrs = NearestNeighbors(n_neighbors=k).fit(X_moons_s)
distances, _ = nbrs.kneighbors(X_moons_s)
dists_sorted = np.sort(distances[:, -1])[::-1]
plt.figure(figsize=(8, 4))
plt.plot(dists_sorted, color='steelblue', linewidth=2)
plt.axhline(0.25, color='tomato', linestyle='--', label='eps=0.25')
plt.xlabel('Puntos (ordenados)')
plt.ylabel(f'Distancia al {k}-vecino')
plt.title('Grafico de distancias para elegir eps')
plt.legend()
plt.show()
# El "codo" de esta curva es un buen valor de eps
4. Clustering jerarquico y dendrogramas
El clustering jerarquico construye un arbol (dendrograma) de fusiones. El corte del arbol a cierta altura define los clusters.
from sklearn.cluster import AgglomerativeClustering
from scipy.cluster.hierarchy import dendrogram, linkage
np.random.seed(0)
X_small, _ = make_blobs(n_samples=30, centers=3, cluster_std=0.8, random_state=0)
X_small_s = StandardScaler().fit_transform(X_small)
# Calcular la matriz de enlace
Z = linkage(X_small_s, method='ward') # Ward minimiza la varianza intra-cluster
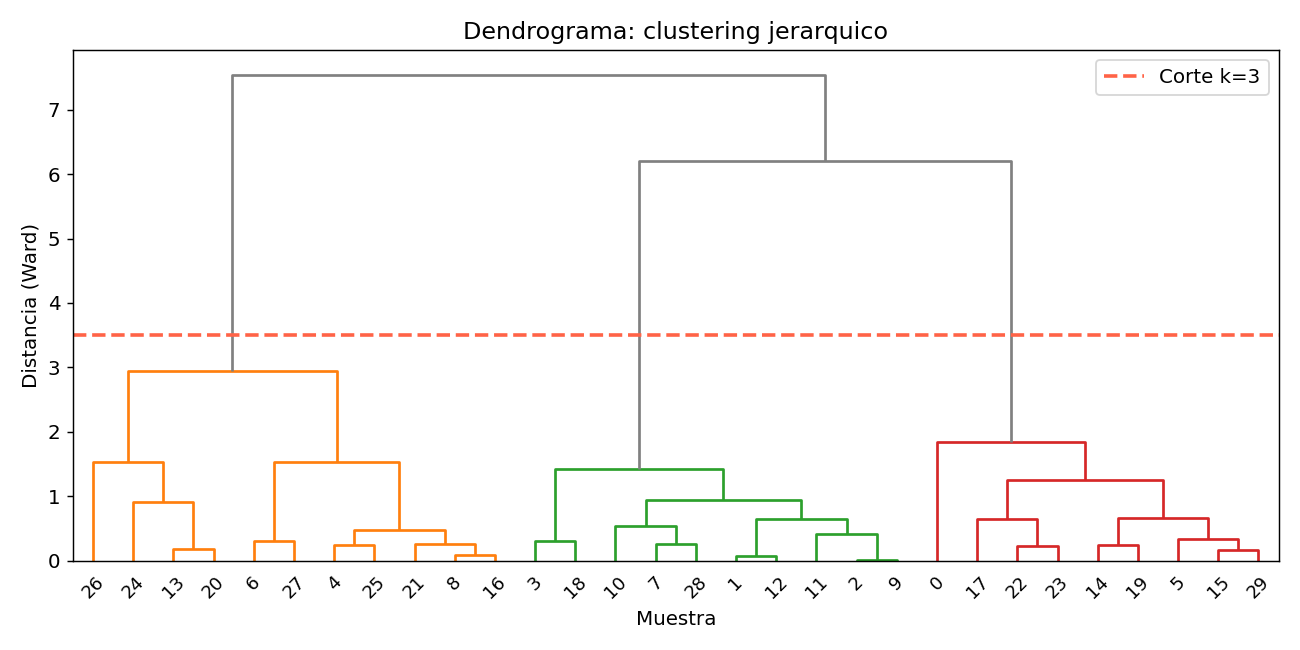
La linea roja horizontal indica el corte que produce 3 clusters. Cortando mas arriba obtendrías 2, mas abajo 4.
# Obtener etiquetas con AgglomerativeClustering
agg = AgglomerativeClustering(n_clusters=3, linkage='ward')
labels_agg = agg.fit_predict(X_small_s)
print(f"Silhouette jerarquico: {silhouette_score(X_small_s, labels_agg):.4f}")
# Metodos de enlace disponibles:
# 'ward': minimiza varianza (generalmente mejor)
# 'complete': distancia maxima entre clusters
# 'average': distancia promedio
# 'single': distancia minima (sensible a ruido)
5. PCA: reduccion de dimensionalidad
PCA transforma las features originales en componentes principales ortogonales que maximizan la varianza capturada.
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
iris = load_iris()
X_iris = StandardScaler().fit_transform(iris.data)
# PCA completo: ver varianza por componente
pca_full = PCA()
pca_full.fit(X_iris)
print("Varianza explicada por componente:")
for i, var in enumerate(pca_full.explained_variance_ratio_):
print(f" PC{i+1}: {var:.4f} ({var*100:.1f}%)")
print(f" Acumulada 2 comp: {pca_full.explained_variance_ratio_[:2].sum():.4f}")
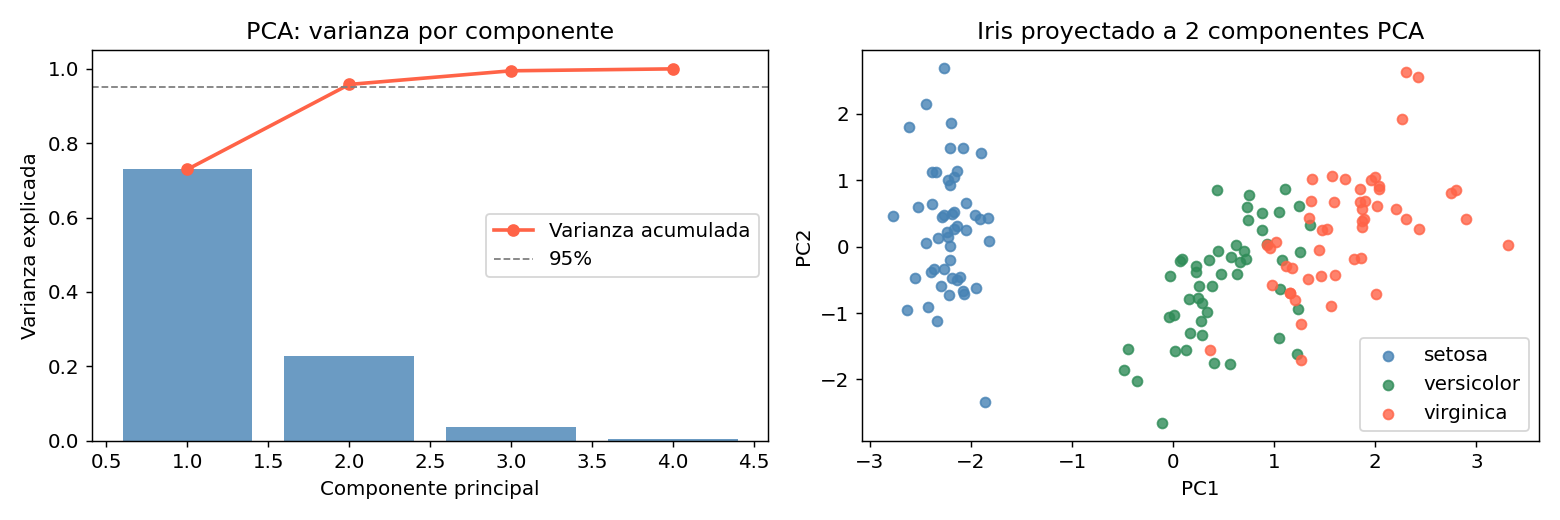
Las primeras 2 componentes capturan ~96% de la varianza total del dataset Iris. La proyeccion 2D muestra separacion clara entre las 3 especies.
# Aplicar PCA con n componentes fijo
pca_2d = PCA(n_components=2)
X_2d = pca_2d.fit_transform(X_iris)
print(f"Shape original: {X_iris.shape}") # (150, 4)
print(f"Shape reducido: {X_2d.shape}") # (150, 2)
# PCA para retener 95% de la varianza (n_components automatico)
pca_95 = PCA(n_components=0.95)
X_95 = pca_95.fit_transform(X_iris)
print(f"Componentes para 95%: {pca_95.n_components_}")
# Interpretar componentes: loadings
loadings = pd.DataFrame(
pca_full.components_.T,
columns=[f'PC{i+1}' for i in range(4)],
index=iris.feature_names
)
print("\nLoadings (contribucion de cada feature a cada PC):")
print(loadings.round(3))
PCA como preprocesamiento para modelos
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
# Sin PCA
base_lr = cross_val_score(LogisticRegression(max_iter=1000),
X_iris, iris.target, cv=5, scoring='accuracy').mean()
# Con PCA (2 componentes)
pipe_pca = Pipeline([
("pca", PCA(n_components=2)),
("lr", LogisticRegression(max_iter=1000))
])
pca_lr = cross_val_score(pipe_pca, X_iris, iris.target, cv=5, scoring='accuracy').mean()
print(f"Accuracy sin PCA: {base_lr:.4f}")
print(f"Accuracy con PCA (2 comp): {pca_lr:.4f}")
# PCA puede perder informacion discriminativa; evalua siempre con CV
6. t-SNE y UMAP para visualizacion
PCA es lineal. Para estructuras no lineales, t-SNE y UMAP son mucho mas poderosos visualmente — pero no sirven como preprocesamiento (no se pueden aplicar a nuevos datos de forma confiable).
from sklearn.manifold import TSNE
# t-SNE: lento pero excelente para visualizacion
Xi_tsne = TSNE(
n_components=2,
perplexity=30, # controla el balance local-global (5-50 tipico)
learning_rate=200, # si el mapa parece "pelota", baja a 50
n_iter=1000,
random_state=42
).fit_transform(X_iris)
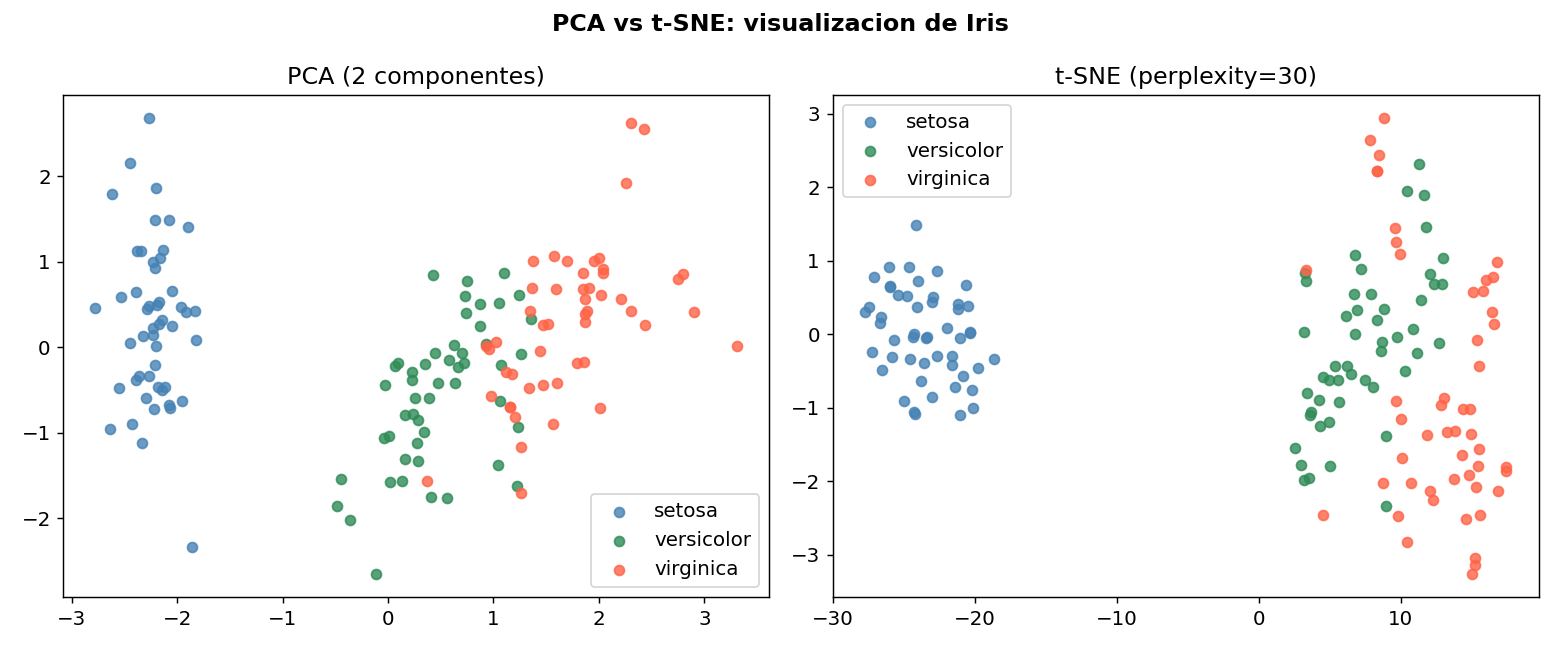
t-SNE separa aun mejor las clases que PCA, especialmente versicolor vs virginica. Pero recuerda: las distancias absolutas en t-SNE no son interpretables.
# UMAP: mas rapido que t-SNE y preserva estructura global
# pip install umap-learn
import umap
reducer = umap.UMAP(n_components=2, n_neighbors=15, min_dist=0.1, random_state=42)
X_umap = reducer.fit_transform(X_iris)
# UMAP SÍ puede aplicarse a nuevos datos
X_new = reducer.transform(X_iris[:5])
Comparacion t-SNE vs UMAP:
| Aspecto | t-SNE | UMAP |
|---|---|---|
| Velocidad | Lento (O(n²)) | Rapido |
| Escalabilidad | Hasta ~50k puntos | Millones de puntos |
| Estructura global | No preserva bien | Preserva mejor |
| Nuevos datos | No (hay que re-entrenar) | Si |
| Parametro clave | perplexity | n_neighbors, min_dist |
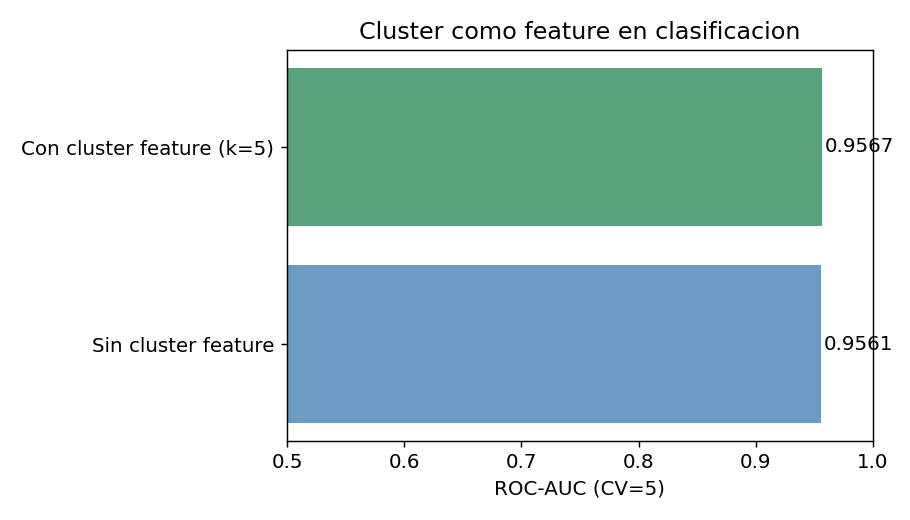
7. Clusters como features para modelos supervisados
Esta es la aplicacion mas poderosa del clustering en competencias: generar nuevas features a partir de estructuras no supervisadas.
from sklearn.cluster import KMeans
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from sklearn.datasets import make_classification
np.random.seed(42)
Xc, yc = make_classification(n_samples=600, n_features=8, n_informative=4, random_state=42)
Xc_s = StandardScaler().fit_transform(Xc)
# ── Feature 1: etiqueta de cluster ──────────────────────────────────────────
km5 = KMeans(n_clusters=5, random_state=42, n_init=10).fit(Xc_s)
cluster_label = km5.labels_.reshape(-1, 1)
# ── Feature 2: distancias a todos los centroides ────────────────────────────
distances_to_centers = km5.transform(Xc_s) # (n, k) distancias
# ── Feature 3: componentes PCA ──────────────────────────────────────────────
pca3 = PCA(n_components=3)
pca_features = pca3.fit_transform(Xc_s)
# Augmentar con todas las features
Xc_aug = np.hstack([Xc_s, cluster_label, distances_to_centers, pca_features])
rf = RandomForestClassifier(n_estimators=100, random_state=42)
auc_base = cross_val_score(rf, Xc_s, yc, cv=5, scoring='roc_auc').mean()
auc_aug = cross_val_score(rf, Xc_aug, yc, cv=5, scoring='roc_auc').mean()
print(f"AUC baseline: {auc_base:.4f}")
print(f"AUC con features: {auc_aug:.4f}")
print(f"Mejora: +{(auc_aug - auc_base)*100:.2f}%")
Cuidado con la fuga de datos:
# INCORRECTO: fit en todo el dataset antes de cross_val_score
# km_leak = KMeans(n_clusters=5).fit(Xc_s) <- ve los datos de test!
# CORRECTO: incluir clustering dentro del pipeline
from sklearn.pipeline import Pipeline, FeatureUnion
from sklearn.base import BaseEstimator, TransformerMixin
class KMeansDistances(BaseEstimator, TransformerMixin):
def __init__(self, n_clusters=5):
self.n_clusters = n_clusters
self.km = None
def fit(self, X, y=None):
self.km = KMeans(n_clusters=self.n_clusters, random_state=42, n_init=10).fit(X)
return self
def transform(self, X):
return self.km.transform(X)
from sklearn.pipeline import FeatureUnion
pipe_safe = Pipeline([
("features", FeatureUnion([
("passthrough", "passthrough"),
("km_dists", KMeansDistances(n_clusters=5)),
])),
("clf", RandomForestClassifier(n_estimators=100, random_state=42)),
])
auc_safe = cross_val_score(pipe_safe, Xc_s, yc, cv=5, scoring='roc_auc').mean()
print(f"AUC pipeline seguro: {auc_safe:.4f}")
8. Mini-proyecto: segmentacion de clientes
Objetivo: segmentar clientes por comportamiento de compra e identificar acciones por segmento.
Paso 1: preparar datos
import pandas as pd
# Dataset sintetico de clientes
np.random.seed(42)
n = 500
clientes = pd.DataFrame({
"recencia": np.random.exponential(30, n).clip(1, 365), # dias desde ultima compra
"frecuencia": np.random.poisson(5, n).clip(1, 50), # numero de compras
"monto": np.random.lognormal(5, 1, n).clip(50, 5000), # gasto total
"soporte": np.random.choice([0,1,2,3], n, p=[0.5,0.3,0.15,0.05]), # llamadas soporte
})
# Escalar
scaler = StandardScaler()
X_cli = scaler.fit_transform(clientes)
Paso 2: determinar k optimo
inertias_cli, sil_cli = [], []
for k in range(2, 9):
km_k = KMeans(n_clusters=k, random_state=42, n_init=10)
lbl = km_k.fit_predict(X_cli)
inertias_cli.append(km_k.inertia_)
sil_cli.append(silhouette_score(X_cli, lbl))
print(f"k={k}: inercia={inertias_cli[-1]:.0f}, silhouette={sil_cli[-1]:.4f}")
k_optimo = sil_cli.index(max(sil_cli)) + 2
print(f"\nk optimo por silhouette: {k_optimo}")
Paso 3: clusterizar e interpretar
km_final = KMeans(n_clusters=4, random_state=42, n_init=10)
clientes["cluster"] = km_final.fit_predict(X_cli)
# Perfil de cada segmento
perfil = clientes.groupby("cluster").agg({
"recencia": "mean",
"frecuencia": "mean",
"monto": "mean",
"soporte": "mean",
"cluster": "count"
}).rename(columns={"cluster": "n_clientes"})
print(perfil.round(1))
recencia frecuencia monto soporte n_clientes
cluster
0 28.5 8.2 580.3 0.4 142 <- Activos valiosos
1 180.3 2.1 95.2 0.1 87 <- Inactivos de bajo valor
2 15.2 18.5 2340.1 1.8 55 <- VIP frecuentes
3 300.1 1.2 67.3 2.9 64 <- Churned con problemas
Paso 4: visualizar en 2D con PCA
X_pca = PCA(n_components=2).fit_transform(X_cli)
plt.figure(figsize=(8, 6))
for seg in clientes["cluster"].unique():
mask = clientes["cluster"] == seg
plt.scatter(X_pca[mask, 0], X_pca[mask, 1],
label=f"Segmento {seg} (n={mask.sum()})", alpha=0.7, s=30)
plt.xlabel("PC1"); plt.ylabel("PC2")
plt.title("Segmentos de clientes en espacio PCA")
plt.legend()
plt.show()
Paso 5: definir acciones por segmento
acciones = {
0: "Programa de fidelidad — mantener engagement",
1: "Campana de reactivacion — descuento por regreso",
2: "Atencion prioritaria — programa VIP exclusivo",
3: "Encuesta de salida — mejorar soporte o dar de baja",
}
for seg, accion in acciones.items():
n = (clientes["cluster"] == seg).sum()
print(f"Segmento {seg} ({n} clientes): {accion}")
Dashboard visual
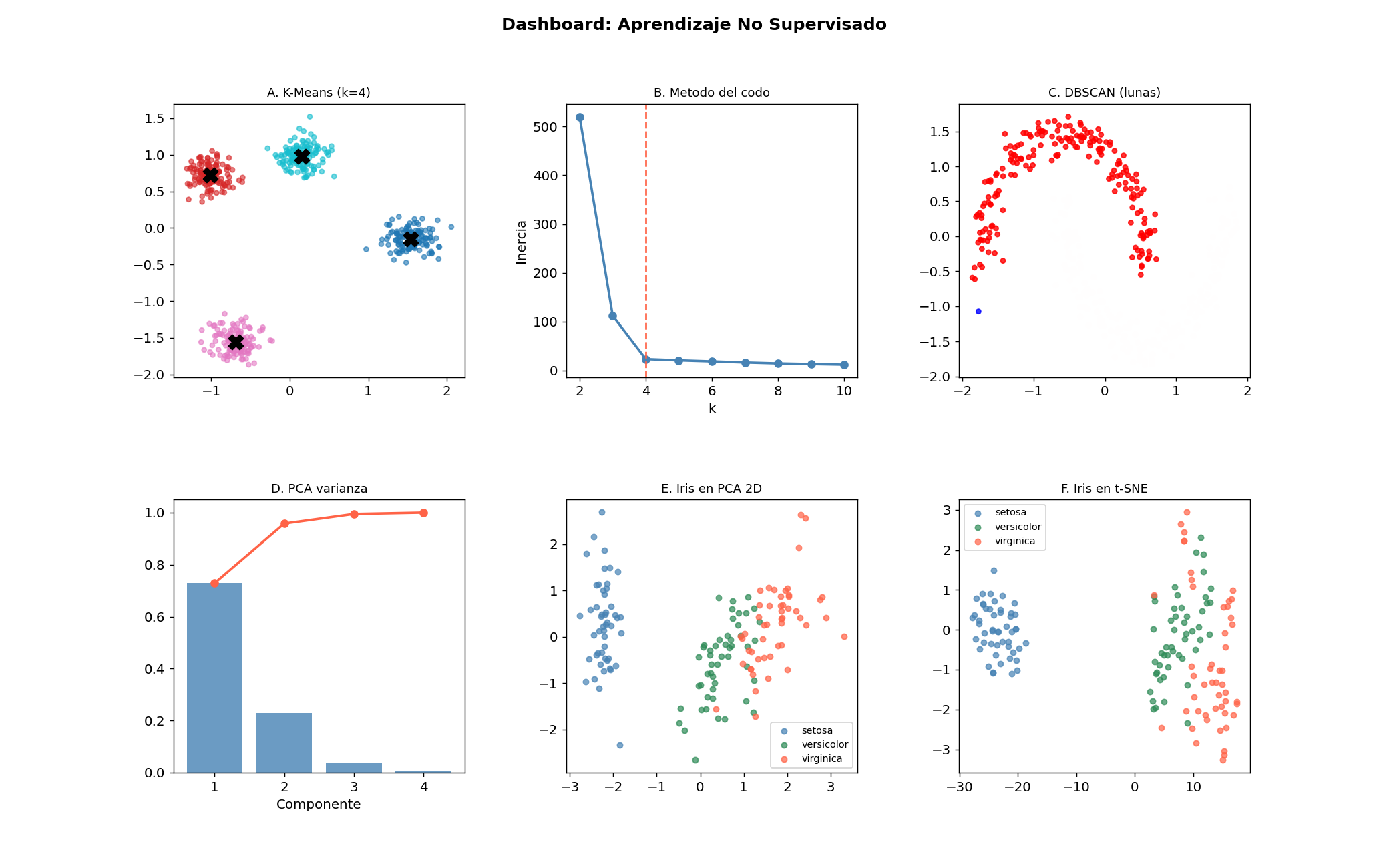
Panel A: K-Means con centroides
Panel B: Metodo del codo
Panel C: DBSCAN en datos de luna
Panel D: Varianza explicada por PCA
Panel E: Iris proyectado a 2 componentes PCA
Panel F: Iris en t-SNE (separacion mas clara)
Errores comunes
| Error | Descripcion | Solucion |
|---|---|---|
| No escalar antes de clusterizar | Distancias dominadas por features con magnitud alta | Siempre StandardScaler antes de K-Means o DBSCAN |
| Interpretar t-SNE como mapa de distancias reales | Las distancias en t-SNE son relativas, no absolutas | Solo usa t-SNE para visualizacion cualitativa |
| Usar cluster labels sin pipeline | Fuga de informacion en CV | Encapsula el clustering en un Transformer |
| Forzar k sin analisis | Clusters sin significado | Usa metodo del codo + silhouette + criterio de negocio |
| DBSCAN sin ajustar eps | Clusters todos unidos o todos ruido | Usa grafico de distancias al k-vecino |
| PCA antes de escalar | Componentes sesgadas por varianza artificial | Siempre escala primero |
Seccion avanzada
HDBSCAN: DBSCAN jerarquico
# pip install hdbscan
import hdbscan
clusterer = hdbscan.HDBSCAN(min_cluster_size=15, min_samples=5)
labels_h = clusterer.fit_predict(X_sc)
print(f"Clusters HDBSCAN: {len(set(labels_h)) - (1 if -1 in labels_h else 0)}")
# Ventaja: no necesita eps, mas robusto que DBSCAN
Deteccion de anomalias con Isolation Forest
from sklearn.ensemble import IsolationForest
iso = IsolationForest(contamination=0.05, random_state=42)
anomaly_scores = iso.fit_predict(X_sc)
outliers = X_sc[anomaly_scores == -1]
print(f"Anomalias detectadas: {len(outliers)}")
Recursos recomendados
- Documentacion sklearn: clustering
- Documentacion sklearn: PCA y descomposicion
- ISLR capitulo 12 — Unsupervised Learning (libro gratuito)
- Tutorial t-SNE por Laurens van der Maaten
- UMAP: Uniform Manifold Approximation
Desarrollo extendido para implementacion real
Marco mental para ML competitivo
Cuando estudies este tema, piensa siempre en el pipeline completo, no en una tecnica aislada. Un buen resultado competitivo requiere:
- Datos confiables y limpios.
- Validacion sin fuga de informacion.
- Baseline fuerte y bien documentado.
- Iteracion controlada de mejoras.
- Seleccion final por evidencia, no por intuicion.
Flujo recomendado de trabajo
- Comprende el problema y la metrica oficial.
- Construye un baseline en menos de 1 hora.
- Analiza errores por segmentos de datos.
- Propone 3 mejoras concretas (features, modelo, validacion).
- Mide cada cambio por separado.
- Conserva solo lo que mejora de forma consistente.
Decision tecnica: como elegir entre alternativas
Preguntas practicas que debes responder:
- El modelo mejora en validacion local o solo en leaderboard publico?
- La mejora es estable en varios folds?
- La complejidad adicional justifica el beneficio?
- Puedo reproducir el resultado en una nueva corrida?
Si una mejora no supera estas preguntas, no deberia entrar en tu version final.
Errores de nivel intermedio que debes evitar
- Ajustar hiperparametros antes de tener un baseline estable.
- Mezclar transformaciones de train y test.
- Hacer demasiados cambios simultaneos.
- Ignorar interpretacion de errores por subgrupo.
Ejercicio integrador largo
Toma un dataset tabular de Kaggle y completa este ciclo:
- EDA corto pero accionable.
- Baseline reproducible.
- Dos versiones con nuevas features.
- Una version con tuning moderado.
- Reporte comparativo final con tabla de metricas.
Objetivo: aprender a pensar como competidor meticuloso, no solo como usuario de librerias.
Navegacion
← 8. Modelos de Clasificacion | 10. Introduccion a Redes Neuronales →