10. Introduccion a Redes Neuronales
Por que las redes neuronales cambian el juego
Los modelos clasicos (regresion, arboles, SVM) son potentes cuando las features ya estan bien definidas y las relaciones entre variables son relativamente simples. Pero ante imagenes, audio, texto o datos con interacciones de altisima dimension, esos modelos alcanzan su techo rapido.
Las redes neuronales artificiales resuelven esto aprendiendo representaciones jerarquicas directamente desde los datos crudos. Cada capa extrae patrones mas abstractos que la anterior: pixeles → bordes → formas → objetos. Esta capacidad de representacion es lo que las hace indispensables en vision por computadora, procesamiento de lenguaje natural, series de tiempo y casi cualquier problema de olimpiadas de IA de nivel avanzado.
En este tema construiras los fundamentos matematicos y computacionales desde la neurona individual hasta una red multicapa entrenada con backpropagation. El objetivo no es solo saber que son las redes, sino entender por que funcionan y como diagnosticarlas cuando fallan.
1. La neurona artificial
De la neurona biologica al modelo matematico
La neurona artificial es una abstraccion matematica inspirada, muy libremente, en la neurona biologica. Recibe multiples entradas, las pondera, las suma, aplica una funcion no lineal y produce una salida.
Anatomia de la neurona:
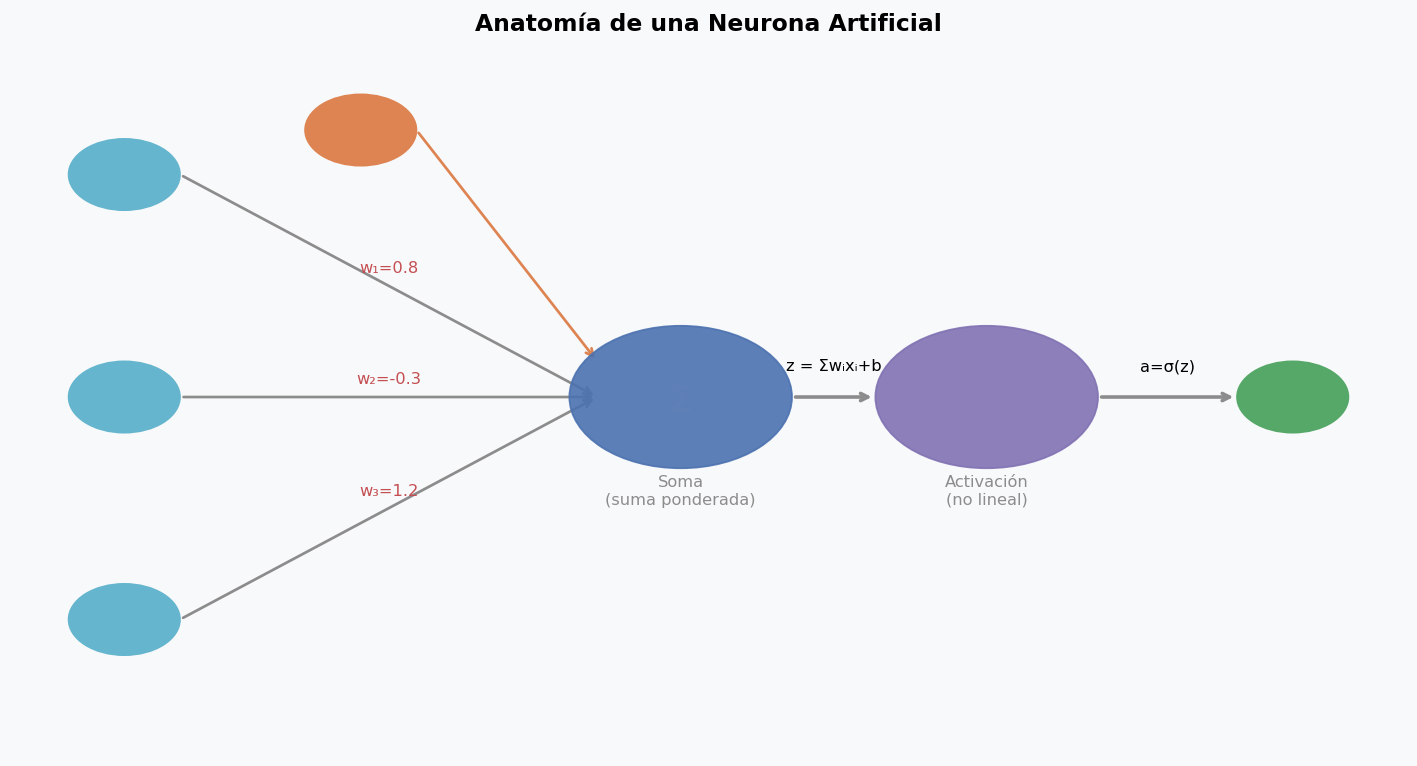
El calculo formal es:
Donde:
- x = vector de entradas
- w = pesos (lo que la red aprende)
- b = sesgo (bias), permite desplazar la activacion
- z = suma ponderada (preactivacion)
- σ = funcion de activacion (introduce no linealidad)
- a = activacion (salida de la neurona)
El Perceptron: el caso mas simple
El Perceptron de Rosenblatt (1958) es una neurona binaria que clasifica linealmente. Aprende actualizando pesos cuando comete un error:
import numpy as np
class Perceptron:
def __init__(self, lr=0.1, n_iter=100):
self.lr = lr
self.n_iter = n_iter
def fit(self, X, y):
# y debe ser {0, 1}
self.w = np.zeros(X.shape[1])
self.b = 0.0
self.errors_ = []
for _ in range(self.n_iter):
errors = 0
for xi, yi in zip(X, y):
pred = self.predict_single(xi)
update = self.lr * (yi - pred)
self.w += update * xi
self.b += update
errors += int(update != 0)
self.errors_.append(errors)
return self
def predict_single(self, x):
return int(np.dot(self.w, x) + self.b >= 0.5)
def predict(self, X):
return np.array([self.predict_single(xi) for xi in X])
# Ejemplo: AND logico
X = np.array([[0,0],[0,1],[1,0],[1,1]], dtype=float)
y = np.array([0, 0, 0, 1])
p = Perceptron(lr=0.1, n_iter=50)
p.fit(X, y)
print("Predicciones AND:", p.predict(X)) # [0 0 0 1]
print("Pesos:", p.w, "Bias:", p.b)
Limitacion critica: el Perceptron solo puede resolver problemas linealmente separables. XOR le es imposible. Esa limitacion motivo la invencion de las redes multicapa.
2. Funciones de activacion
La funcion de activacion es lo que le da poder expresivo a la red. Sin ella, apilar capas lineales es equivalente a tener una sola capa lineal: la composicion de funciones lineales es lineal.
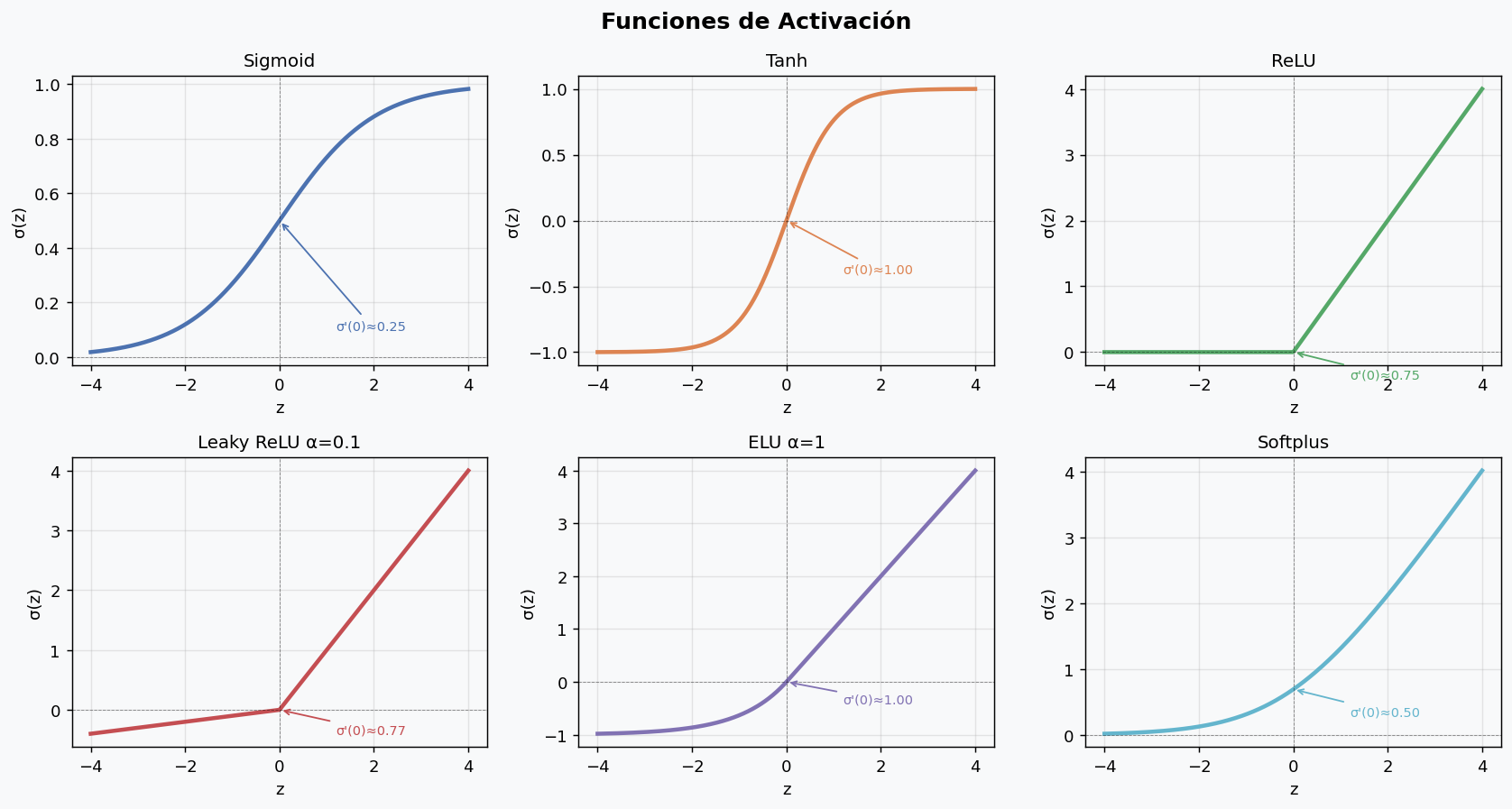
Comparativa de activaciones
| Funcion | Formula | Rango | Gradiente en 0 | Problema principal |
|---|---|---|---|---|
| Sigmoid | 1/(1+e⁻ᶻ) | (0,1) | 0.25 | Vanishing gradient |
| Tanh | (eᶻ-e⁻ᶻ)/(eᶻ+e⁻ᶻ) | (-1,1) | 1.0 | Vanishing gradient |
| ReLU | max(0,z) | [0,∞) | indefinido en 0 | Neuronas muertas |
| Leaky ReLU | max(αz,z) | (-∞,∞) | ~1 | Hiper α a elegir |
| ELU | z si z>0; α(eᶻ-1) si z≤0 | (-α,∞) | 1.0 | Costosa en comp. |
| Softplus | log(1+eᶻ) | (0,∞) | 0.5 | Saturacion lenta |
Cuando usar cada una
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-4, 4, 400)
def relu(x): return np.maximum(0, x)
def sigmoid(x): return 1 / (1 + np.exp(-x))
def tanh(x): return np.tanh(x)
def leaky(x, a=0.1): return np.where(x > 0, x, a*x)
def elu(x, a=1.0): return np.where(x > 0, x, a*(np.exp(x)-1))
# Derivadas (para entender el gradiente)
def d_relu(x): return (x > 0).astype(float)
def d_sigmoid(x): s = sigmoid(x); return s * (1 - s)
def d_tanh(x): return 1 - np.tanh(x)**2
# Reglas practicas:
# - Capas ocultas generales → ReLU o Leaky ReLU
# - Salida de regresion → lineal (sin activacion)
# - Salida de clasificacion → sigmoid (binaria) / softmax (multi-clase)
# - Capas recurrentes (LSTM) → tanh + sigmoid internas
# - Transformers → GELU o SwiGLU
El problema del vanishing gradient
Con Sigmoid y Tanh, el gradiente en regiones saturadas se vuelve cercano a cero. En redes profundas, ese gradiente se multiplica capa por capa durante el backpropagation, resultando en gradientes exponencialmente pequenos en las capas iniciales. Esas capas dejan de aprender.
ReLU resuelve parcialmente esto: su gradiente es 1 para entradas positivas, lo que facilita el flujo del gradiente. Sin embargo, si muchas neuronas reciben entradas negativas, sus gradientes son 0 permanentemente (neuronas muertas). Leaky ReLU y ELU mitigan esto.
3. Red multicapa: forward pass
Una red neuronal multicapa (MLP) apila capas de neuronas. Cada capa aplica una transformacion lineal seguida de una activacion no lineal.
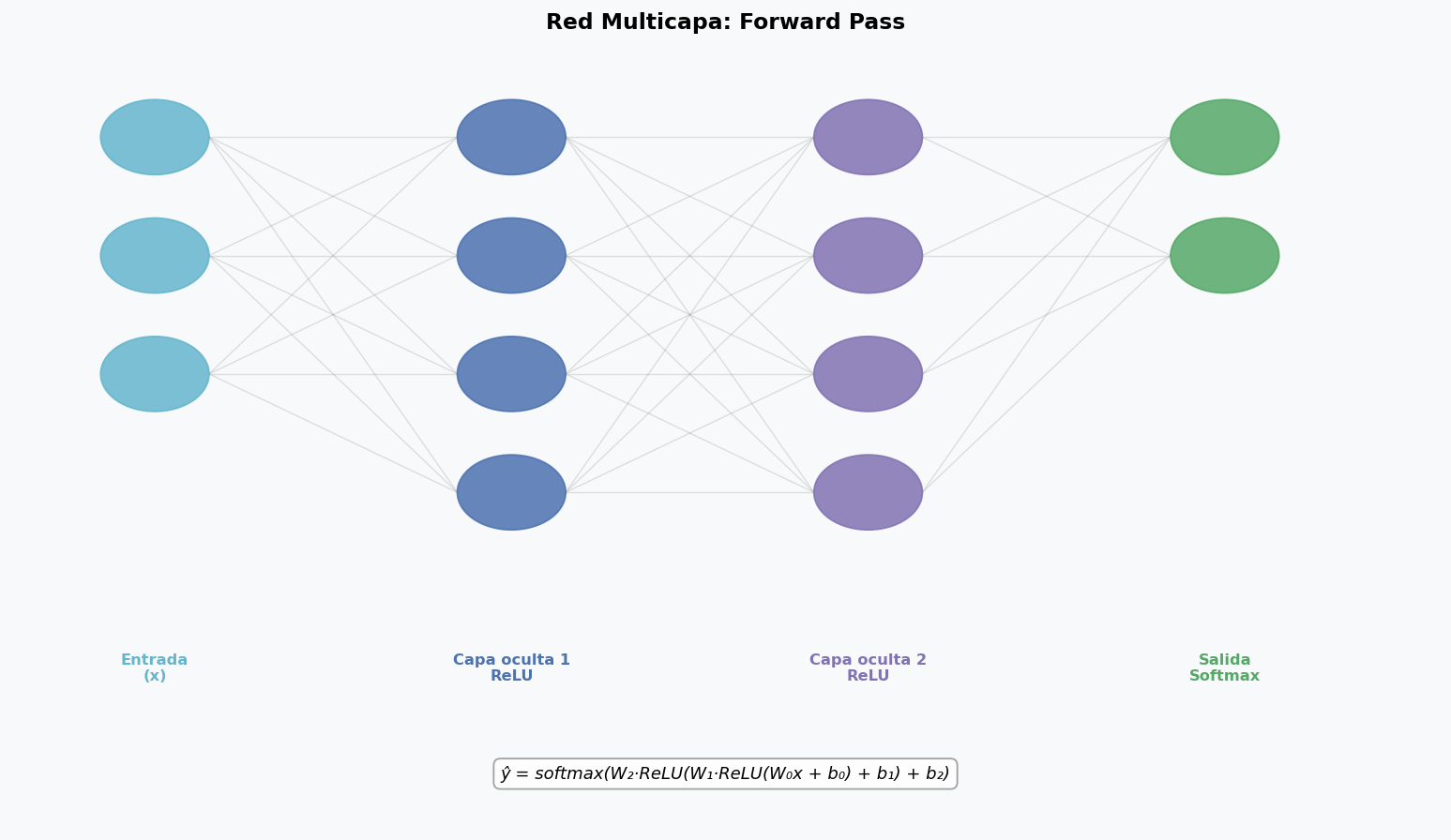
Notacion matricial
Para una red con L capas:
import numpy as np
class MLP:
"""MLP desde cero para entender el mecanismo interno."""
def __init__(self, layer_sizes, activation="relu"):
self.sizes = layer_sizes
self.activation = activation
self._init_params()
def _init_params(self):
# He initialization para ReLU, Xavier para tanh/sigmoid
self.params = {}
for l in range(1, len(self.sizes)):
fan_in = self.sizes[l-1]
fan_out = self.sizes[l]
if self.activation == "relu":
scale = np.sqrt(2.0 / fan_in) # He
else:
scale = np.sqrt(1.0 / fan_in) # Xavier simplificado
self.params[f"W{l}"] = np.random.randn(fan_out, fan_in) * scale
self.params[f"b{l}"] = np.zeros((fan_out, 1))
def _activate(self, z):
if self.activation == "relu": return np.maximum(0, z)
if self.activation == "tanh": return np.tanh(z)
if self.activation == "sigmoid":return 1/(1+np.exp(-z))
return z
def _d_activate(self, z):
if self.activation == "relu": return (z > 0).astype(float)
if self.activation == "tanh": return 1 - np.tanh(z)**2
s = 1/(1+np.exp(-z))
if self.activation == "sigmoid":return s * (1 - s)
return np.ones_like(z)
def forward(self, X):
"""Forward pass. Guarda activaciones para backprop."""
self.cache = {"A0": X.T} # X: (n_samples, n_features)
A = X.T
L = len(self.sizes) - 1
for l in range(1, L + 1):
W = self.params[f"W{l}"]
b = self.params[f"b{l}"]
Z = W @ A + b
self.cache[f"Z{l}"] = Z
# Ultima capa: activacion lineal (regresion) o softmax (clasificacion)
if l == L:
A = Z # para regresion; cambia por softmax si clasificacion
else:
A = self._activate(Z)
self.cache[f"A{l}"] = A
return A # shape (n_outputs, n_samples)
# Ejemplo de uso
net = MLP(layer_sizes=[4, 8, 8, 1], activation="relu")
X_demo = np.random.randn(100, 4)
output = net.forward(X_demo)
print(f"Input shape: {X_demo.shape}") # (100, 4)
print(f"Output shape: {output.T.shape}") # (100, 1)
Inicializacion de pesos: por que importa
Inicializar todos los pesos en cero hace que todas las neuronas de cada capa computen exactamente lo mismo durante el forward pass y reciban exactamente el mismo gradiente durante el backward pass. La red nunca “rompe la simetria” y las capas nunca aprenden features distintas.
La solucion es inicializar con valores aleatorios pequenos. Las dos estrategias mas usadas:
- Xavier/Glorot:
std = sqrt(1 / fan_in)osqrt(2 / (fan_in + fan_out)). Optimo para Tanh y Sigmoid. - He:
std = sqrt(2 / fan_in). Optimo para ReLU.
4. Backpropagation
Backpropagation es el algoritmo para calcular eficientemente los gradientes de la funcion de perdida respecto a todos los parametros de la red. Es una aplicacion de la regla de la cadena del calculo diferencial, aplicada de forma recursiva desde la capa de salida hacia la capa de entrada.
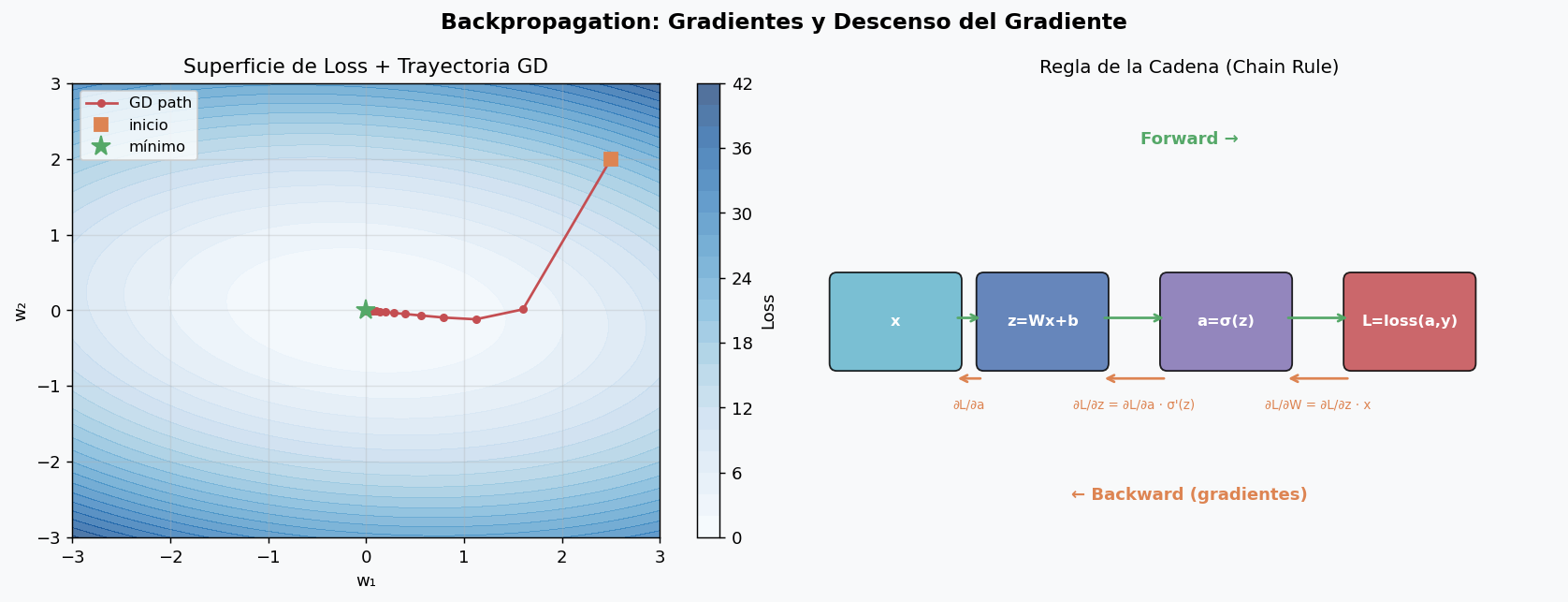
La regla de la cadena en accion
Para una red de L capas, el gradiente de la perdida respecto a los pesos de la capa l es:
Donde el “error local” de cada capa se propaga hacia atras:
def backward(self, Y, learning_rate=0.01):
"""Backpropagation para regresion (MSE loss)."""
m = Y.shape[0] # numero de muestras
L = len(self.sizes) - 1
grads = {}
# Gradiente en la capa de salida (MSE: dL/dA_L = 2*(A_L - Y)/m)
dA = (self.cache[f"A{L}"] - Y.T) * 2 / m
for l in reversed(range(1, L + 1)):
W = self.params[f"W{l}"]
Z = self.cache[f"Z{l}"]
A_prev = self.cache[f"A{l-1}"]
if l == L:
dZ = dA # capa de salida lineal
else:
dZ = dA * self._d_activate(Z) # aplicar derivada de activacion
grads[f"dW{l}"] = (dZ @ A_prev.T) / m
grads[f"db{l}"] = np.sum(dZ, axis=1, keepdims=True) / m
dA = W.T @ dZ # propagar al nivel anterior
# Actualizar parametros con SGD
for l in range(1, L + 1):
self.params[f"W{l}"] -= learning_rate * grads[f"dW{l}"]
self.params[f"b{l}"] -= learning_rate * grads[f"db{l}"]
return grads
# Agregar metodo al MLP
MLP.backward = backward
# Entrenamiento de prueba (regresion simple)
np.random.seed(42)
X_train = np.random.randn(200, 4)
y_train = X_train[:, 0] + 2*X_train[:, 1] - X_train[:, 2] + np.random.randn(200)*0.1
model = MLP([4, 16, 8, 1], activation="relu")
losses = []
for epoch in range(300):
out = model.forward(X_train)
loss = np.mean((out.T - y_train.reshape(-1,1))**2)
losses.append(loss)
model.backward(y_train.reshape(-1,1), learning_rate=0.01)
print(f"Loss inicial: {losses[0]:.4f} → Loss final: {losses[-1]:.4f}")
Descenso del gradiente y sus variantes
El gradiente apunta en la direccion de maximo ascenso de la perdida. Ir en la direccion opuesta (gradiente descendente) reduce la perdida:
w ← w - η · ∂L/∂w
| Variante | Descripcion | Ventaja | Desventaja |
|---|---|---|---|
| BGD (batch) | Gradiente sobre todo el dataset | Convergencia estable | Lento en datasets grandes |
| SGD (stochastic) | Gradiente por muestra | Rapido, ruido util | Oscilante |
| Mini-batch GD | Gradiente por lote (32-256) | Balance velocidad/estabilidad | Requiere elegir batch size |
| Adam | SGD + momentum + adaptacion por parametro | Robusto, ampliamente usado | Puede sobre-ajustar en algunos casos |
| AdamW | Adam + weight decay correcto | Mejor generalizacion | Hiper adicional λ |
5. Funciones de perdida
La funcion de perdida mide que tan lejos estan las predicciones de los valores reales. Elegir la correcta segun la tarea es fundamental.
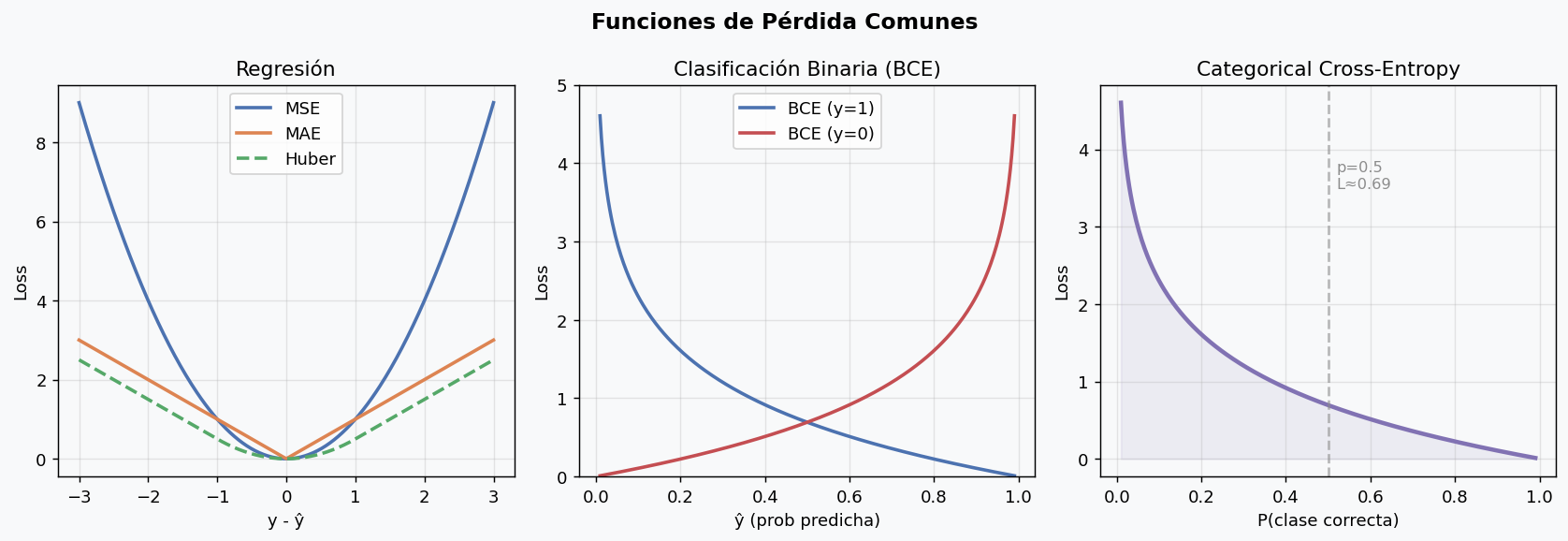
Perdidas para regresion
import numpy as np
def mse(y_true, y_pred):
"""Mean Squared Error — penaliza errores grandes cuadraticamente."""
return np.mean((y_true - y_pred)**2)
def rmse(y_true, y_pred):
"""Root MSE — misma unidad que y."""
return np.sqrt(mse(y_true, y_pred))
def mae(y_true, y_pred):
"""Mean Absolute Error — robusta a outliers."""
return np.mean(np.abs(y_true - y_pred))
def huber_loss(y_true, y_pred, delta=1.0):
"""Huber — MAE para errores grandes, MSE para errores pequenos.
Combina robustez a outliers con diferenciabilidad en 0."""
err = y_true - y_pred
return np.where(
np.abs(err) <= delta,
0.5 * err**2,
delta * (np.abs(err) - 0.5 * delta)
).mean()
# ¿Cuando usar cual?
# MSE → cuando grandes errores son costosos
# MAE → cuando hay outliers y todos los errores son igualmente malos
# Huber → compromiso entre MSE y MAE; util con datos ruidosos
Perdidas para clasificacion
def binary_cross_entropy(y_true, y_pred, eps=1e-7):
"""BCE para clasificacion binaria.
y_pred debe estar en (0,1) — salida de sigmoid.
"""
y_pred = np.clip(y_pred, eps, 1 - eps) # evitar log(0)
return -np.mean(y_true * np.log(y_pred) + (1 - y_true) * np.log(1 - y_pred))
def categorical_cross_entropy(y_true_onehot, y_pred_probs, eps=1e-7):
"""CCE para clasificacion multi-clase.
y_true_onehot: one-hot encoding
y_pred_probs: salida de softmax
"""
y_pred_probs = np.clip(y_pred_probs, eps, 1.0)
return -np.mean(np.sum(y_true_onehot * np.log(y_pred_probs), axis=1))
def softmax(z):
"""Funcion softmax numericamente estable."""
z_shifted = z - np.max(z, axis=1, keepdims=True)
exp_z = np.exp(z_shifted)
return exp_z / np.sum(exp_z, axis=1, keepdims=True)
# Ejemplo: 3 clases, 4 muestras
logits = np.array([[2.0, 1.0, 0.1],
[0.5, 2.5, 0.3],
[0.2, 0.1, 3.1],
[1.0, 1.0, 1.0]])
probs = softmax(logits)
y_true = np.array([[1,0,0],[0,1,0],[0,0,1],[0,1,0]])
print(f"CCE: {categorical_cross_entropy(y_true, probs):.4f}")
6. Arquitecturas y su efecto en la frontera de decision
Agregar capas y neuronas aumenta la capacidad del modelo para aprender funciones mas complejas. Pero mas capacidad no siempre es mejor.
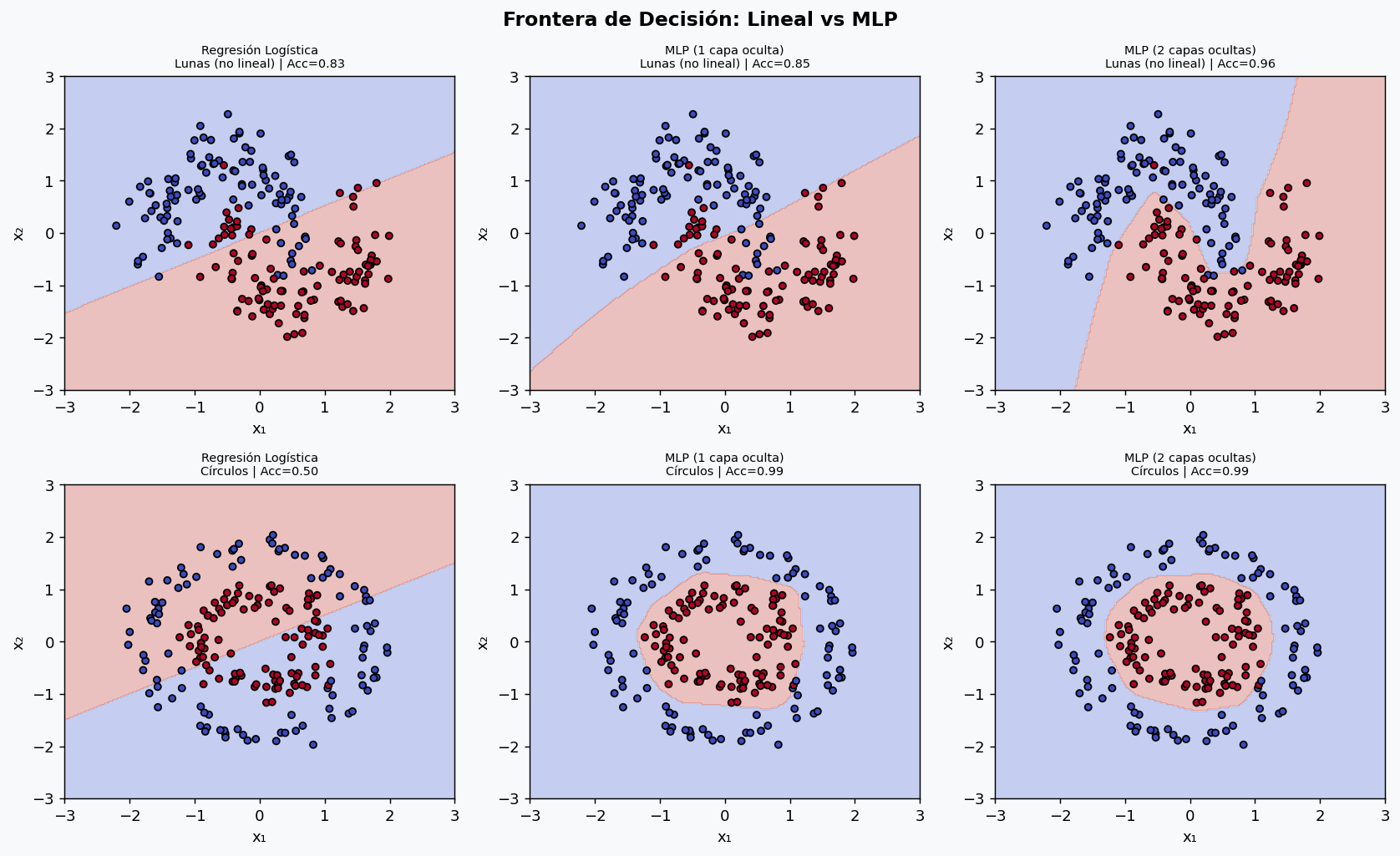
Los datasets “lunas” y “circulos” son no linealmente separables: la regresion logistica falla completamente. Un MLP con una sola capa oculta ya puede resolver el problema. Con dos capas aprende fronteras aun mas suaves.
Efecto de profundidad y ancho
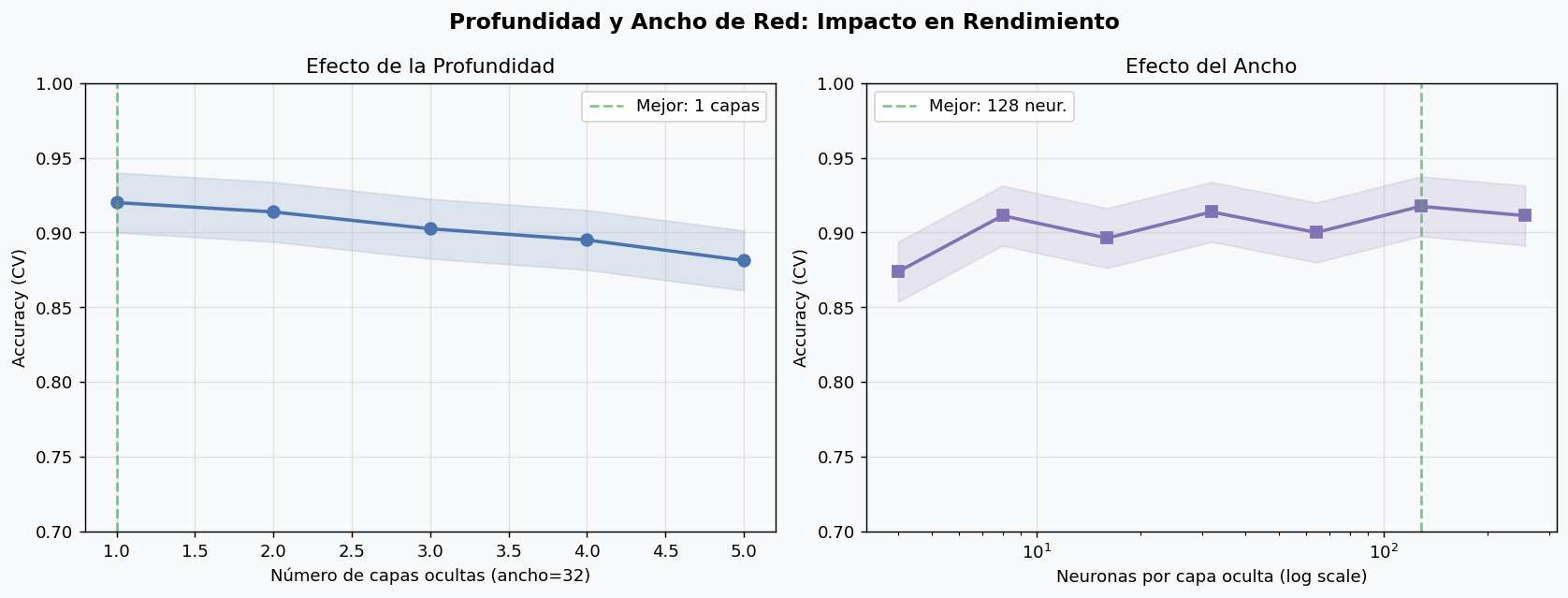
Observaciones clave:
- Aumentar profundidad mejora la accuracy hasta cierto punto, luego puede degradarla (gradient vanishing, overfitting)
- Aumentar ancho tiene retornos decrecientes: 128 neuronas no siempre gana a 64
- La arquitectura optima depende del dataset: empieza pequeno y escala si el modelo no puede sobreajustar
7. Curvas de entrenamiento: tu principal herramienta de diagnostico
Toda sesion de entrenamiento debe terminar con un analisis de las curvas de loss (y opcionalmente de accuracy/metrica principal).
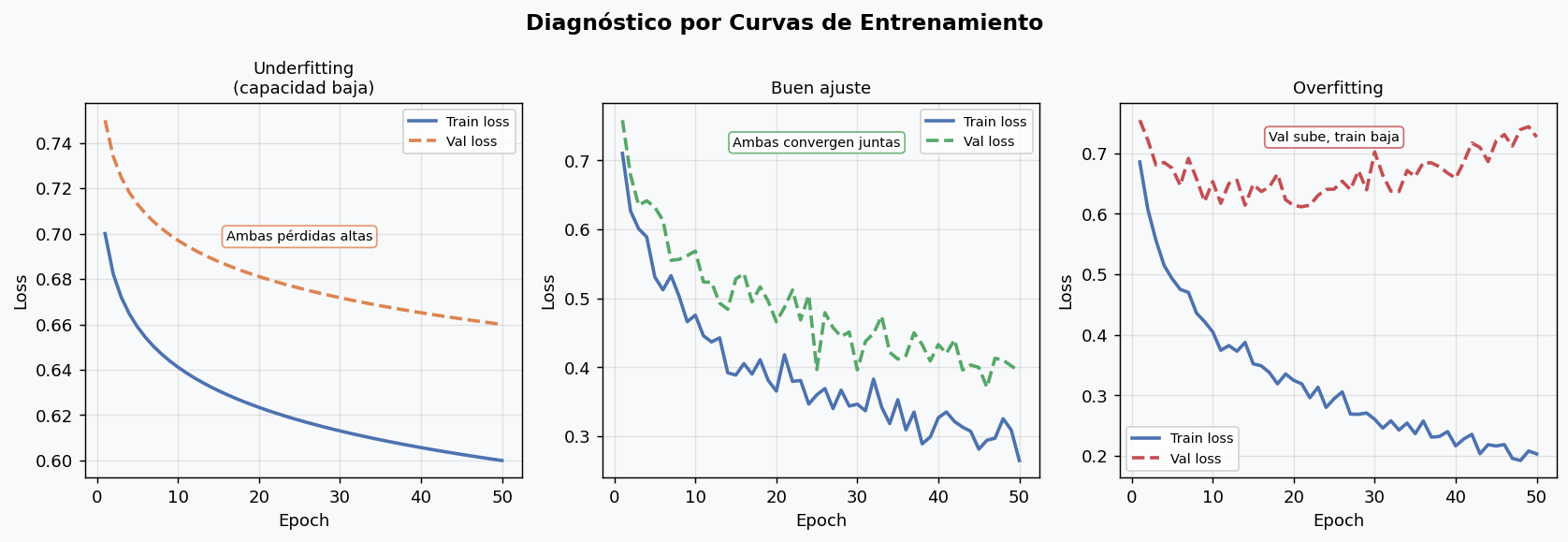
Los tres patrones que debes reconocer
Underfitting (capacidad insuficiente):
- Ambas curvas (train y val) convergen a un valor alto
- El modelo no puede aprender los patrones del problema
- Solucion: aumentar arquitectura, features mas ricas, menos regularizacion
Buen ajuste:
- Train y val bajan juntas y convergen en valores similares
- La brecha entre ambas es pequena
- Este es el objetivo
Overfitting:
- Train sigue bajando, val sube o se estanca
- El modelo memoriza el entrenamiento pero no generaliza
- Solucion: mas datos, dropout, weight decay, early stopping, arquitectura mas pequena
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
import numpy as np
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)
X_tr, X_val, y_tr, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# sklearn MLPClassifier guarda loss_curve_ automaticamente
mlp = MLPClassifier(
hidden_layer_sizes=(64, 32),
activation="relu",
solver="adam",
learning_rate_init=0.001,
max_iter=200,
random_state=42,
early_stopping=True, # detiene si val no mejora
validation_fraction=0.15,
n_iter_no_change=15,
verbose=False
)
mlp.fit(X_tr, y_tr)
print(f"Accuracy val: {mlp.score(X_val, y_val):.3f}")
print(f"Mejor epoch: {mlp.best_loss_:.4f}")
print(f"Iteraciones: {mlp.n_iter_}")
# mlp.loss_curve_ contiene la curva de entrenamiento
Indicadores de learning rate incorrecto
LR muy alto: loss oscila o diverge (NaN) en los primeros epochs
LR muy bajo: loss baja extremadamente lento, puede tardar 10x mas
LR adecuado: bajada suave y constante en los primeros epochs
8. Implementacion completa con scikit-learn
Antes de pasar a PyTorch/Keras, domina el MLP de scikit-learn para datos tabulares. Es mas rapido de iterar y suficiente para muchos problemas de olimpiadas.
from sklearn.neural_network import MLPClassifier, MLPRegressor
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import cross_val_score, GridSearchCV
from sklearn.datasets import load_digits
import numpy as np
# ── Clasificacion: digitos ────────────────────────────────────────────────
digits = load_digits()
X, y = digits.data, digits.target # 1797 muestras, 64 features (8x8 pixeles)
pipe = Pipeline([
("scaler", StandardScaler()),
("mlp", MLPClassifier(
hidden_layer_sizes=(128, 64),
activation="relu",
solver="adam",
learning_rate_init=0.001,
max_iter=300,
early_stopping=True,
random_state=42,
))
])
cv_scores = cross_val_score(pipe, X, y, cv=5, scoring="accuracy")
print(f"Accuracy: {cv_scores.mean():.3f} ± {cv_scores.std():.3f}")
# ── Busqueda de arquitectura optima ──────────────────────────────────────
param_grid = {
"mlp__hidden_layer_sizes": [(64,), (128,), (64,32), (128,64), (128,64,32)],
"mlp__activation": ["relu", "tanh"],
"mlp__learning_rate_init": [0.001, 0.005],
}
gs = GridSearchCV(pipe, param_grid, cv=3, scoring="accuracy",
n_jobs=-1, verbose=0)
gs.fit(X, y)
print(f"Mejor arquitectura: {gs.best_params_['mlp__hidden_layer_sizes']}")
print(f"Mejor activacion: {gs.best_params_['mlp__activation']}")
print(f"Mejor accuracy: {gs.best_score_:.3f}")
Regularizacion en MLPs
# L2 regularizacion (weight decay) via alpha
mlp_l2 = MLPClassifier(
hidden_layer_sizes=(128, 64),
activation="relu",
alpha=0.001, # L2 penalty — mas alto = mas regularizacion
max_iter=300,
random_state=42,
)
# Dropout no esta en sklearn.MLPClassifier directamente.
# Para dropout, usa PyTorch o Keras.
# Alternativa rapida: reducir arquitectura es el "dropout natural"
mlp_small = MLPClassifier(
hidden_layer_sizes=(32,), # arquitectura pequena = menos overfitting
max_iter=300,
random_state=42,
)
9. Mini-proyecto: clasificador de digitos escritos a mano
Construye un clasificador completo para el dataset MNIST (o los digitos de sklearn) siguiendo el flujo profesional.
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.preprocessing import StandardScaler
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import classification_report, confusion_matrix
import numpy as np
import matplotlib.pyplot as plt
# 1. Cargar y explorar datos
digits = load_digits()
X, y = digits.data, digits.target
print(f"Shape: {X.shape}") # (1797, 64)
print(f"Clases: {np.unique(y)}") # 0..9
print(f"Distribucion:\n{np.bincount(y)}")
# 2. Visualizar algunas muestras
fig, axes = plt.subplots(2, 5, figsize=(10, 4))
for ax, i in zip(axes.flat, range(10)):
idx = np.where(y == i)[0][0]
ax.imshow(X[idx].reshape(8,8), cmap="gray_r")
ax.set_title(f"Clase {i}"); ax.axis("off")
plt.tight_layout(); plt.show()
# 3. Split estratificado
X_tr, X_test, y_tr, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=42
)
# 4. Pipeline con normalizacion
scaler = StandardScaler()
X_tr_s = scaler.fit_transform(X_tr)
X_test_s = scaler.transform(X_test)
# 5. Baseline: MLP pequeno
mlp_base = MLPClassifier(
hidden_layer_sizes=(64,),
max_iter=300, random_state=42
)
mlp_base.fit(X_tr_s, y_tr)
print(f"Baseline acc: {mlp_base.score(X_test_s, y_test):.3f}")
# 6. Modelo mejorado
mlp_best = MLPClassifier(
hidden_layer_sizes=(256, 128, 64),
activation="relu",
solver="adam",
learning_rate_init=0.001,
alpha=0.0001,
max_iter=500,
early_stopping=True,
validation_fraction=0.1,
n_iter_no_change=20,
random_state=42,
)
mlp_best.fit(X_tr_s, y_tr)
y_pred = mlp_best.predict(X_test_s)
print(f"\nMejor modelo acc: {mlp_best.score(X_test_s, y_test):.3f}")
print("\nReporte detallado:")
print(classification_report(y_test, y_pred, target_names=[str(i) for i in range(10)]))
# 7. Analisis de errores — ver ejemplos mal clasificados
wrong = np.where(y_pred != y_test)[0]
fig, axes = plt.subplots(2, 5, figsize=(12, 5))
fig.suptitle(f"Errores ({len(wrong)} de {len(y_test)})")
for ax, idx in zip(axes.flat, wrong[:10]):
ax.imshow(X_test[idx].reshape(8,8), cmap="gray_r")
ax.set_title(f"Real:{y_test[idx]} Pred:{y_pred[idx]}", fontsize=9)
ax.axis("off")
plt.tight_layout(); plt.show()
10. Seccion avanzada: batch normalization, dropout y weight decay
Estas tres tecnicas son el “cinturon de seguridad” de los MLPs modernos.
Batch Normalization
Normaliza las activaciones de cada capa durante el entrenamiento. Reduce el desplazamiento covariante interno, permite usar learning rates mas altos y actua como regularizador suave.
# En PyTorch (adelanto del tema 11):
# nn.BatchNorm1d(features) — para datos tabulares/1D
# nn.BatchNorm2d(channels) — para imagenes
# Posicion recomendada: Linear → BatchNorm → ReLU → Dropout
Dropout
Durante el entrenamiento, “apaga” aleatoriamente neuronas con probabilidad p. Fuerza a la red a aprender representaciones redundantes y robustas. En inferencia, se desactiva y los pesos se escalan.
# Reglas practicas de dropout:
# - Capas grandes (>512 neuronas): p = 0.5
# - Capas medianas (128-512): p = 0.3
# - Capas pequenas (<128): p = 0.1 o sin dropout
# - Nunca en la capa de salida
# - sklearn MLPClassifier no soporta dropout → usa PyTorch/Keras
Weight Decay (L2 Regularizacion)
Penaliza pesos grandes en la funcion de perdida. La perdida penalizada es:
Esto limita el tamano de los pesos, forzando al modelo a distribuir la importancia entre muchas neuronas en lugar de depender de unas pocas muy grandes.
Errores comunes y como evitarlos
| Error | Sintoma | Solucion |
|---|---|---|
| No normalizar entradas | Loss explota o converge muy lento | Aplicar StandardScaler antes de entrenar |
| Inicializacion incorrecta | Loss no baja desde el inicio | Usar He para ReLU, Xavier para Tanh |
| LR demasiado alto | Loss oscila o se vuelve NaN | Reducir 10x; usar scheduler |
| LR demasiado bajo | Convergencia extremadamente lenta | Aumentar; usar Adam por defecto |
| Arquitectura grande sin regularizacion | Val loss sube mientras train baja | Agregar dropout, weight decay, early stopping |
| Olvidar modo eval en inferencia | Dropout activo en predicciones | model.eval() en PyTorch antes de predecir |
| Data leakage en normalizacion | Accuracy inflada | fit solo en train, transform en val/test |
| Metrica equivocada para clases desbalanceadas | Modelo parece bueno pero falla | Usar F1-macro, ROC-AUC, no solo accuracy |
Dashboard resumen
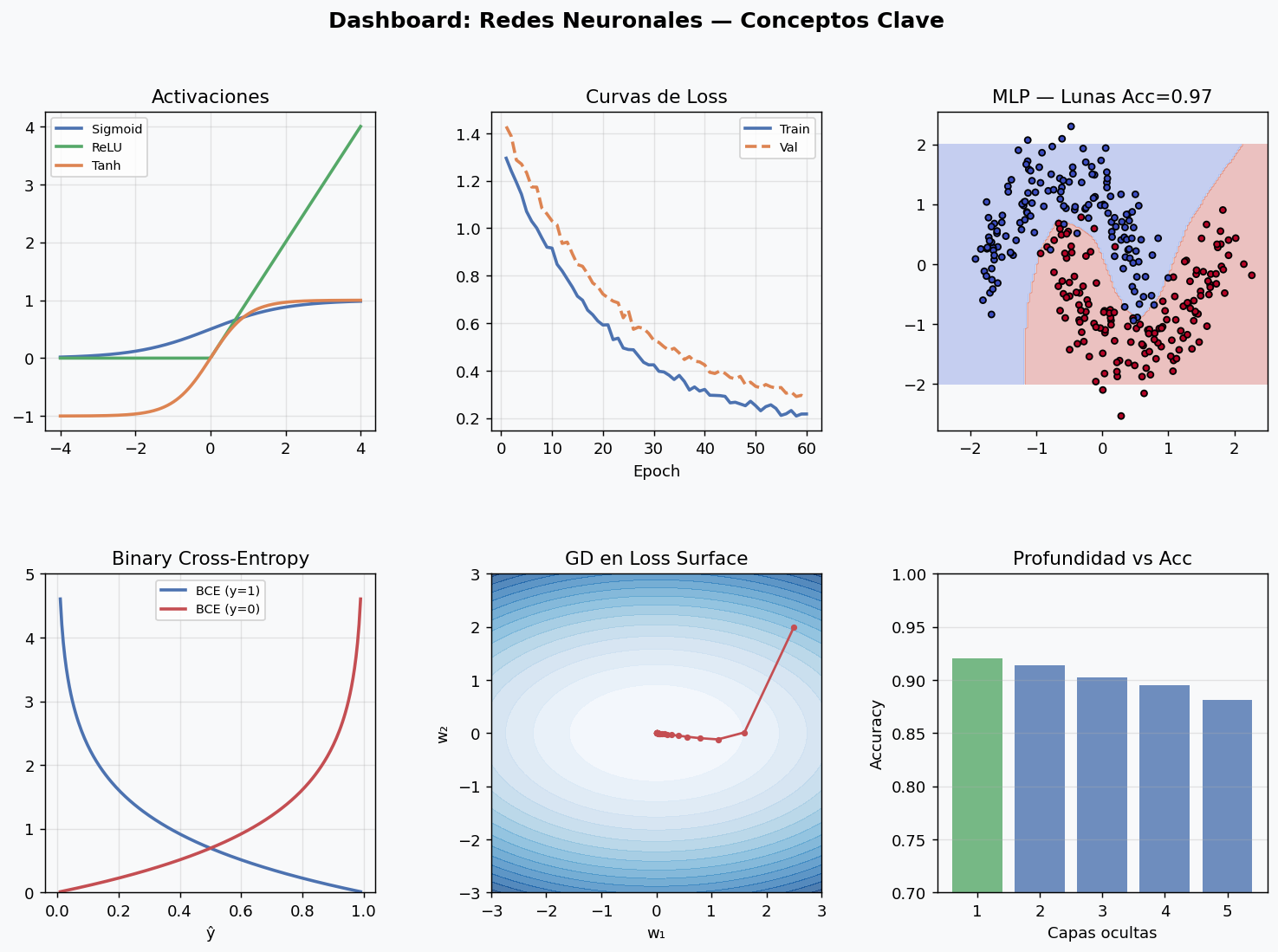
Recursos recomendados
- 3Blue1Brown — Neural Networks (YouTube): la mejor intuicion geometrica sobre backpropagation, sin ecuaciones al principio
- Deep Learning Specialization (Andrew Ng, Coursera): el curso mas completo y accesible; implementa todo desde cero en NumPy
- “Neural Networks and Deep Learning” (Michael Nielsen): libro online gratuito con implementaciones paso a paso
- Fast.ai Practical Deep Learning: enfoque top-down, resultados antes de teoria
- CS231n (Stanford): notas del curso, especialmente la seccion de backpropagation y redes convolucionales
Navegacion
← 9. Aprendizaje No Supervisado | 11. Fundamentos de PyTorch →