8. Modelos de Clasificacion
Por que importa en competencias de IA
La clasificacion es el tipo de problema mas frecuente en olimpiadas de IA. Detectar fraude, predecir abandono de clientes, clasificar imagenes o diagnosticar enfermedades son todos problemas de clasificacion. Saber elegir el modelo correcto, evaluar con las metricas adecuadas y ajustar el umbral de decision puede ser la diferencia entre el primer y el decimo lugar.
Mapa de este tema:
- Logistic Regression como baseline interpretable
- KNN: clasificacion por vecindad
- Decision Tree: reglas interpretables
- Random Forest: poder de los ensambles
- Gradient Boosting y XGBoost
- SVM: margen maximo
- Metricas: accuracy, precision, recall, F1, ROC-AUC
- Matriz de confusion y curvas ROC
- Ajuste de umbral de decision
- Mini-proyecto: clasificador de riesgo
1. Logistic Regression: el baseline imprescindible
La regresion logistica no es regresion: es un clasificador que modela la probabilidad de pertenecer a la clase positiva usando la funcion sigmoide:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.metrics import classification_report, roc_auc_score
from sklearn.datasets import make_classification
np.random.seed(42)
# Dataset binario con desbalance leve
X, y = make_classification(
n_samples=1000, n_features=10, n_informative=6,
n_redundant=2, n_classes=2, weights=[0.6, 0.4],
random_state=42
)
X_tr, X_te, y_tr, y_te = train_test_split(X, y, test_size=0.2, random_state=0)
# SIEMPRE escalar para regresion logistica
scaler = StandardScaler()
X_tr_s = scaler.fit_transform(X_tr)
X_te_s = scaler.transform(X_te)
# Entrenar
lr = LogisticRegression(max_iter=1000, C=1.0) # C = 1/alpha (inverso de regularizacion)
lr.fit(X_tr_s, y_tr)
# Predicciones
y_pred = lr.predict(X_te_s)
y_proba = lr.predict_proba(X_te_s)[:, 1] # probabilidades clase positiva
print(classification_report(y_te, y_pred))
print(f"ROC-AUC: {roc_auc_score(y_te, y_proba):.4f}")
precision recall f1-score support
0 0.88 0.91 0.89 120
1 0.85 0.80 0.82 80
accuracy 0.87 200
ROC-AUC: 0.9312
Coeficientes e interpretabilidad
import pandas as pd
feat_names = [f"x{i}" for i in range(X.shape[1])]
coefs = pd.Series(lr.coef_[0], index=feat_names).sort_values(key=abs, ascending=False)
print("Coeficientes (mayor magnitud = mas influyente):")
print(coefs)
# Odds ratio: e^coef indica cuanto aumenta el odds de clase 1
print("\nOdds ratios:")
print(np.exp(coefs))
Regla competitiva: Siempre corre
LogisticRegressionprimero. Es rapido, interpretable y da un score baseline solido para comparar el resto.
2. Decision Tree: reglas que puedes leer
El arbol de decision divide el espacio de features recursivamente usando criterios como Gini o Entropia:
from sklearn.tree import DecisionTreeClassifier, export_text
# max_depth controla la complejidad y el overfitting
dt = DecisionTreeClassifier(max_depth=5, min_samples_leaf=10, random_state=42)
dt.fit(X_tr_s, y_tr)
print(f"Train accuracy: {dt.score(X_tr_s, y_tr):.4f}")
print(f"Test accuracy: {dt.score(X_te_s, y_te):.4f}")
print(f"ROC-AUC: {roc_auc_score(y_te, dt.predict_proba(X_te_s)[:,1]):.4f}")
# Visualizar reglas (arbol pequeno)
print(export_text(dt, feature_names=feat_names, max_depth=3))
El efecto de max_depth en el overfitting es muy claro:
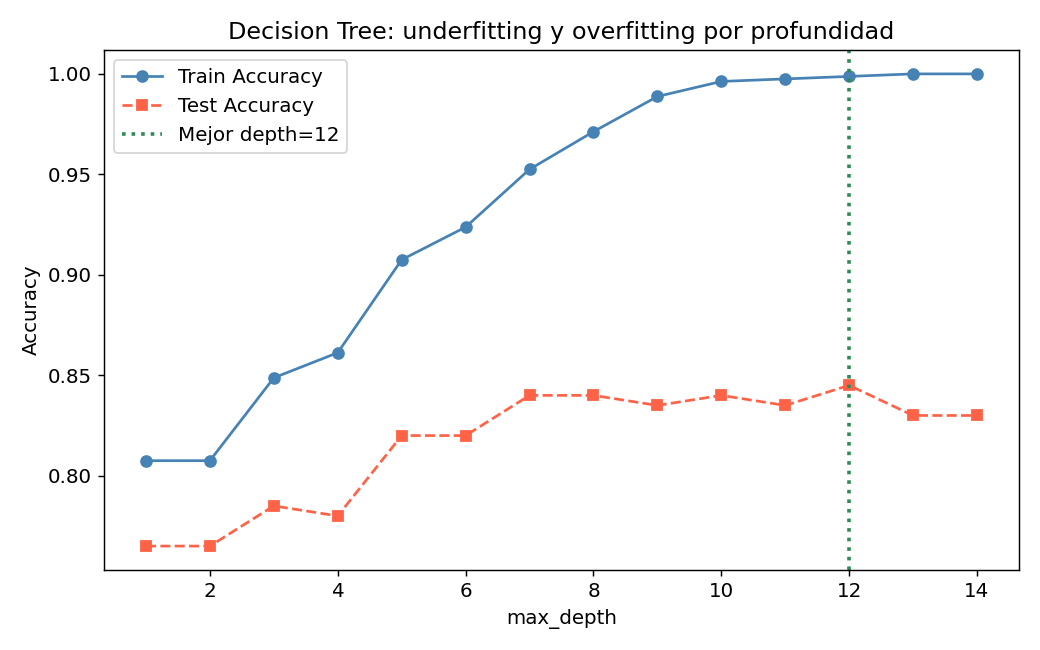
max_depthbajo: underfitting, train y test bajosmax_depthalto: overfitting, train sube pero test baja- La linea verde marca la profundidad optima
# Buscar mejor max_depth con validacion cruzada
from sklearn.model_selection import GridSearchCV
param_grid = {"max_depth": range(1, 20), "min_samples_leaf": [5, 10, 20]}
gs = GridSearchCV(DecisionTreeClassifier(random_state=42),
param_grid, cv=5, scoring="roc_auc")
gs.fit(X_tr_s, y_tr)
print(f"Mejor params: {gs.best_params_}")
print(f"Mejor AUC CV: {gs.best_score_:.4f}")
3. Random Forest: ensamble de arboles
Random Forest construye multiples arboles con bootstrap (muestras aleatorias con reemplazo) y seleccion aleatoria de features en cada split. La prediccion final es la mayoria de votos:
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(
n_estimators=200, # numero de arboles
max_depth=None, # arboles profundos (se controlan por min_samples_leaf)
min_samples_leaf=5,
max_features="sqrt", # sqrt(n_features) features por split
n_jobs=-1, # usar todos los cores
random_state=42
)
rf.fit(X_tr_s, y_tr)
print(f"Train AUC: {roc_auc_score(y_tr, rf.predict_proba(X_tr_s)[:,1]):.4f}")
print(f"Test AUC: {roc_auc_score(y_te, rf.predict_proba(X_te_s)[:,1]):.4f}")
# Feature importance (Mean Decrease Impurity)
importances = pd.Series(rf.feature_importances_, index=feat_names)
print("\nFeature importances:")
print(importances.sort_values(ascending=False))
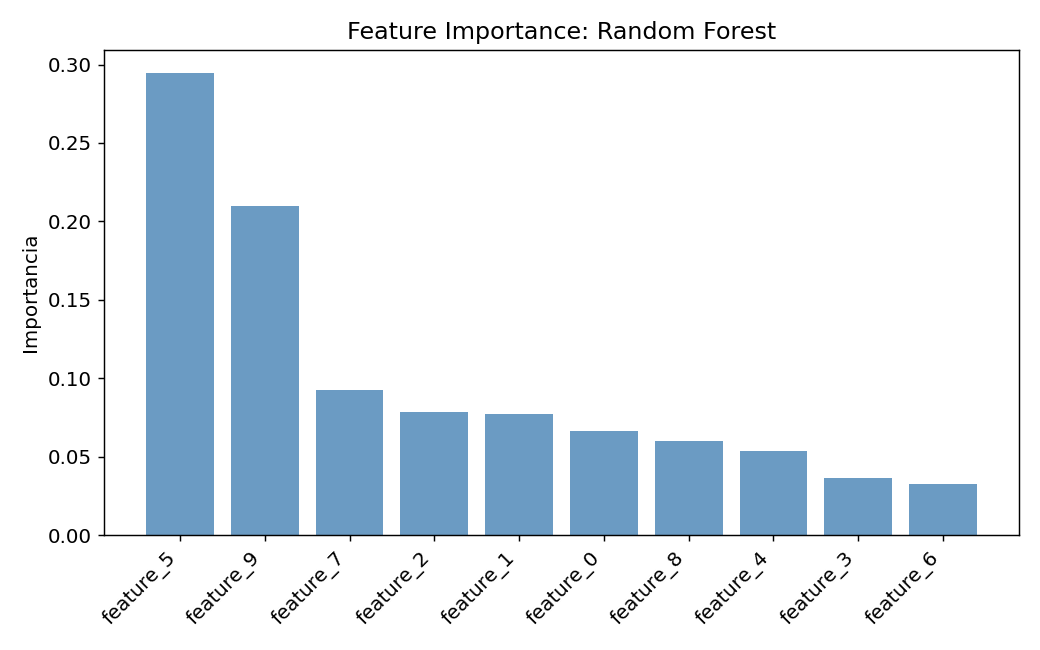
Las features con mayor importancia son las que mas reducen la impureza en los splits. Usa esto para seleccion de features.
Curvas de aprendizaje del Random Forest
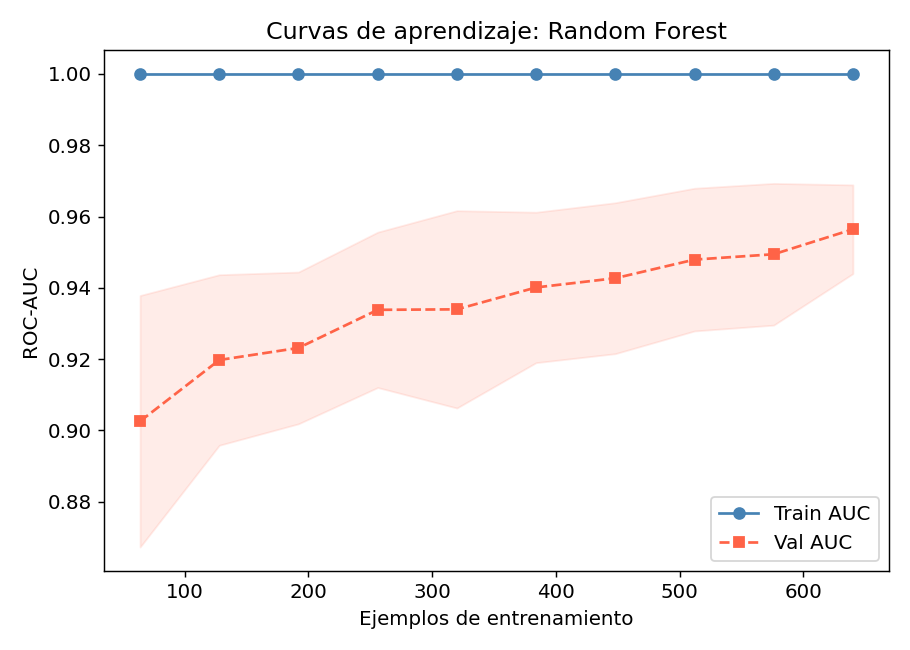
Si la brecha entre Train AUC y Val AUC es grande, necesitas mas datos o mas regularizacion (min_samples_leaf, max_features).
4. Gradient Boosting y XGBoost
El boosting construye arboles secuencialmente: cada nuevo arbol corrige los errores del anterior.
from sklearn.ensemble import GradientBoostingClassifier
gbm = GradientBoostingClassifier(
n_estimators=300,
learning_rate=0.05, # tasa de aprendizaje (shrinkage)
max_depth=4,
subsample=0.8, # fraccion de datos por arbol (stochastic GB)
min_samples_leaf=10,
random_state=42
)
gbm.fit(X_tr_s, y_tr)
print(f"GBM Test AUC: {roc_auc_score(y_te, gbm.predict_proba(X_te_s)[:,1]):.4f}")
XGBoost: el favorito en competencias
# pip install xgboost
import xgboost as xgb
from sklearn.model_selection import cross_val_score
xgb_model = xgb.XGBClassifier(
n_estimators=300,
learning_rate=0.05,
max_depth=4,
subsample=0.8,
colsample_bytree=0.8, # fraccion de features por arbol
reg_alpha=0.1, # L1
reg_lambda=1.0, # L2
use_label_encoder=False,
eval_metric="logloss",
random_state=42,
n_jobs=-1
)
scores = cross_val_score(xgb_model, X_tr_s, y_tr, cv=5, scoring="roc_auc")
print(f"XGBoost CV AUC: {scores.mean():.4f} ± {scores.std():.4f}")
Early stopping con XGBoost
xgb_model2 = xgb.XGBClassifier(
n_estimators=1000,
learning_rate=0.05,
max_depth=4,
subsample=0.8,
eval_metric="logloss",
random_state=42
)
X_tr2, X_val, y_tr2, y_val = train_test_split(X_tr_s, y_tr, test_size=0.15, random_state=0)
xgb_model2.fit(
X_tr2, y_tr2,
eval_set=[(X_val, y_val)],
early_stopping_rounds=30,
verbose=False
)
print(f"Mejor iteracion: {xgb_model2.best_iteration}")
print(f"Test AUC: {roc_auc_score(y_te, xgb_model2.predict_proba(X_te_s)[:,1]):.4f}")
5. KNN y SVM
K-Nearest Neighbors
from sklearn.neighbors import KNeighborsClassifier
# Evaluar distintos valores de k
for k in [1, 3, 5, 10, 20, 50]:
knn = KNeighborsClassifier(n_neighbors=k, metric="euclidean")
auc_cv = cross_val_score(knn, X_tr_s, y_tr, cv=5, scoring="roc_auc").mean()
print(f"k={k:3d}: AUC={auc_cv:.4f}")
# k=1: overfitting casi seguro
# k grande: underfitting (muy suavizado)
KNN en competencias: Util como feature adicional en ensambles (distancias a k vecinos como features). Rara vez es el mejor modelo solo.
SVM con kernel RBF
from sklearn.svm import SVC
svm = SVC(kernel="rbf", C=1.0, gamma="scale", probability=True)
svm.fit(X_tr_s, y_tr)
print(f"SVM Test AUC: {roc_auc_score(y_te, svm.predict_proba(X_te_s)[:,1]):.4f}")
# Hiperparametros clave:
# C: penalizacion por error (alto C = menos margen, mas ajuste)
# gamma: amplitud del kernel RBF (alto gamma = frontera muy irregular)
6. Comparacion de modelos
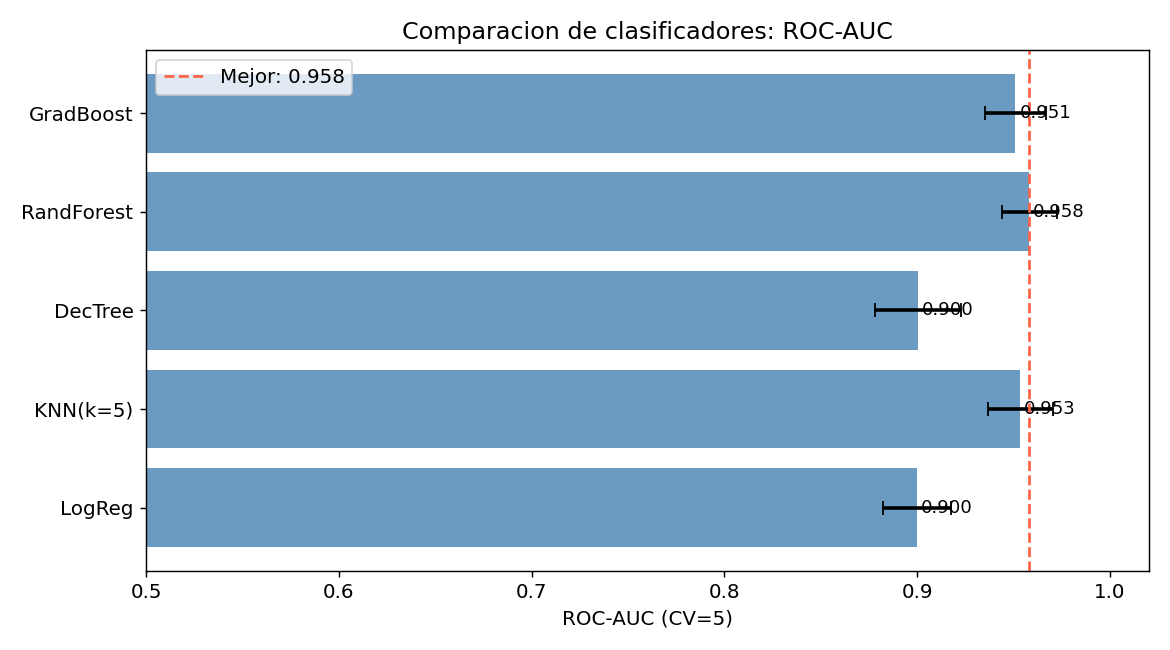
El grafico muestra ROC-AUC con 5-fold CV para cada modelo. Notas importantes:
- Las barras de error muestran estabilidad entre folds
- Un AUC alto con baja varianza es ideal
- GradBoost y RandomForest suelen liderar en datos tabulares
7. Metricas de clasificacion
La accuracy sola es engañosa en datasets desbalanceados. Un modelo que predice siempre “no fraude” en un dataset con 1% de fraudes tiene 99% de accuracy pero es inutil.
from sklearn.metrics import (
accuracy_score, precision_score, recall_score,
f1_score, roc_auc_score, average_precision_score,
confusion_matrix, classification_report
)
y_pred = rf.predict(X_te_s)
y_proba = rf.predict_proba(X_te_s)[:, 1]
print(f"Accuracy: {accuracy_score(y_te, y_pred):.4f}")
print(f"Precision (pos): {precision_score(y_te, y_pred):.4f}")
print(f"Recall (pos): {recall_score(y_te, y_pred):.4f}")
print(f"F1-score: {f1_score(y_te, y_pred):.4f}")
print(f"ROC-AUC: {roc_auc_score(y_te, y_proba):.4f}")
print(f"Average Precision: {average_precision_score(y_te, y_proba):.4f}")
print("\n", classification_report(y_te, y_pred))
Resumen de metricas
| Metrica | Formula | Cuando usarla |
|---|---|---|
| Accuracy | (TP+TN)/(total) | Clases balanceadas |
| Precision | TP/(TP+FP) | Costo alto de falsos positivos |
| Recall | TP/(TP+FN) | Costo alto de falsos negativos |
| F1 | 2·P·R/(P+R) | Balance precision-recall |
| ROC-AUC | area bajo curva ROC | Ranking de probabilidades |
| AP (PR-AUC) | area bajo curva P-R | Datasets muy desbalanceados |
8. Matriz de confusion
La matriz de confusion muestra exactamente donde se equivoca el modelo:
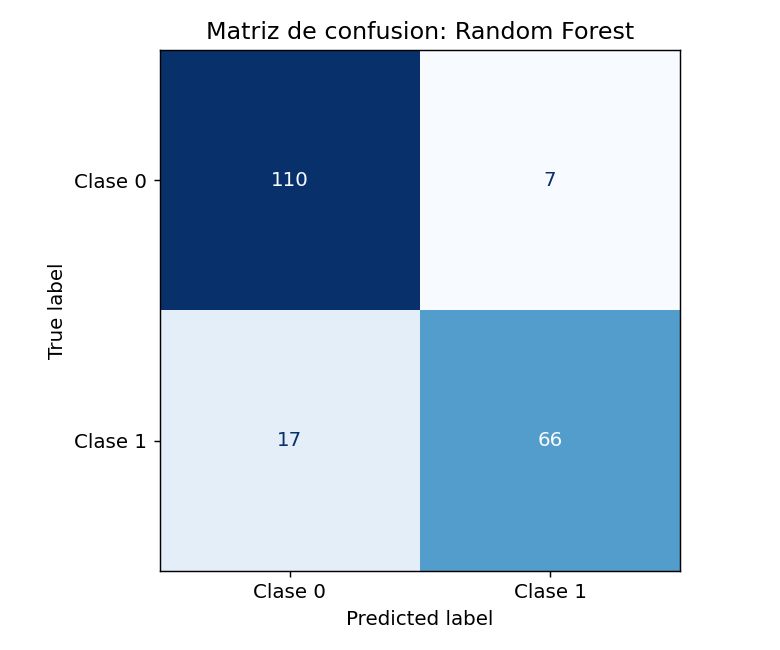
from sklearn.metrics import ConfusionMatrixDisplay
cm = confusion_matrix(y_te, y_pred)
tn, fp, fn, tp = cm.ravel()
print(f"Verdaderos Negativos (TN): {tn}")
print(f"Falsos Positivos (FP): {fp} <- predijo positivo siendo negativo")
print(f"Falsos Negativos (FN): {fn} <- predijo negativo siendo positivo")
print(f"Verdaderos Positivos (TP): {tp}")
# Visualizar
fig, ax = plt.subplots(figsize=(5, 4))
ConfusionMatrixDisplay(cm, display_labels=["Neg", "Pos"]).plot(ax=ax, cmap="Blues")
plt.title("Matriz de confusion")
plt.tight_layout()
plt.show()
9. Curvas ROC y Precision-Recall
Curva ROC
La curva ROC grafica TPR (Recall) vs FPR para todos los umbrales posibles. El area bajo la curva (AUC) resume el rendimiento:
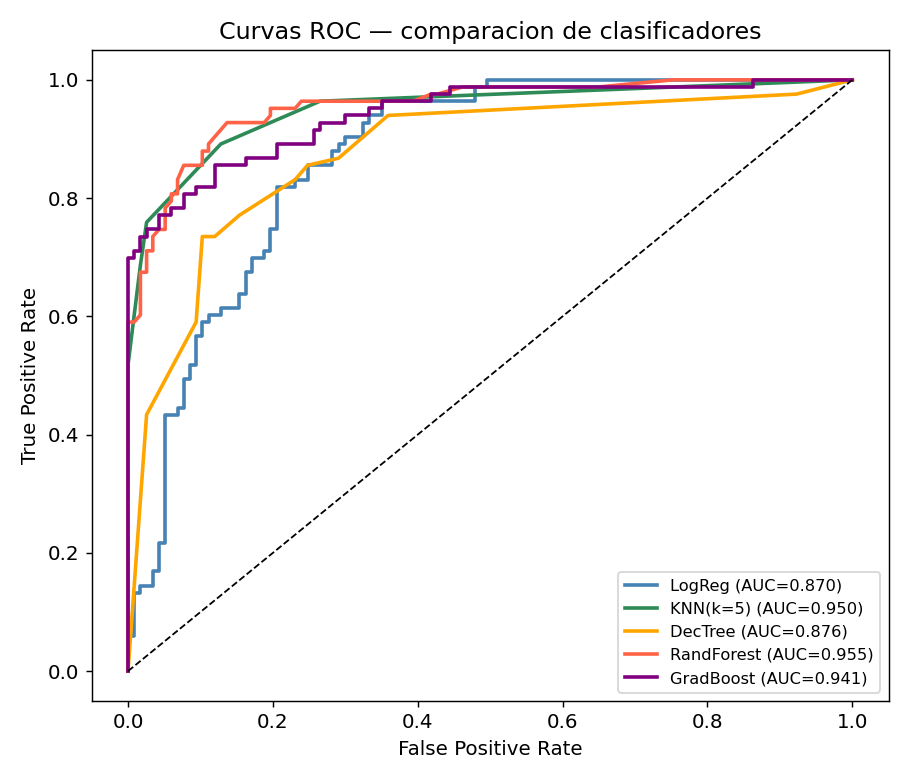
from sklearn.metrics import roc_curve, auc
fpr, tpr, thresholds = roc_curve(y_te, y_proba)
roc_auc = auc(fpr, tpr)
plt.figure(figsize=(7, 5))
plt.plot(fpr, tpr, color='steelblue', linewidth=2,
label=f'Random Forest (AUC = {roc_auc:.3f})')
plt.plot([0, 1], [0, 1], 'k--', label='Clasificador aleatorio (AUC=0.5)')
plt.xlabel('False Positive Rate (FPR)')
plt.ylabel('True Positive Rate (Recall)')
plt.title('Curva ROC')
plt.legend()
plt.show()
Curva Precision-Recall (mejor para desbalance)
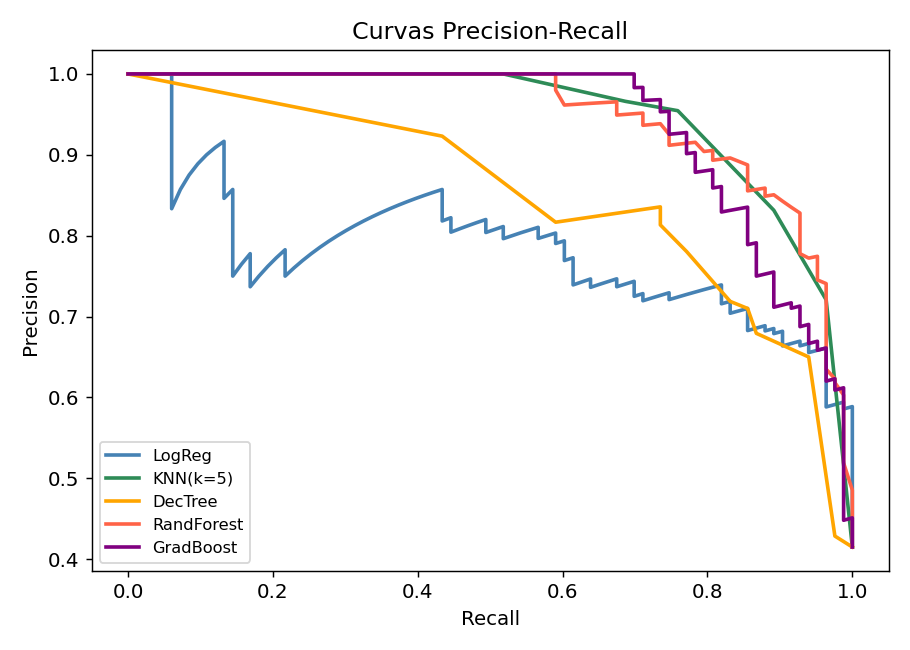
from sklearn.metrics import precision_recall_curve, average_precision_score
precision, recall, _ = precision_recall_curve(y_te, y_proba)
ap = average_precision_score(y_te, y_proba)
plt.figure(figsize=(7, 5))
plt.plot(recall, precision, color='steelblue', linewidth=2,
label=f'AP = {ap:.3f}')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Curva Precision-Recall')
plt.legend()
plt.show()
Cuando usar cada curva: ROC-AUC es buena en general. En datasets con 1-5% de clase positiva (fraude, enfermedad rara), usa Precision-Recall AUC porque ROC-AUC puede ser optimistamente alto.
10. Ajuste del umbral de decision
Por defecto, predict() usa umbral=0.5. Pero a veces es mejor cambiarlo:
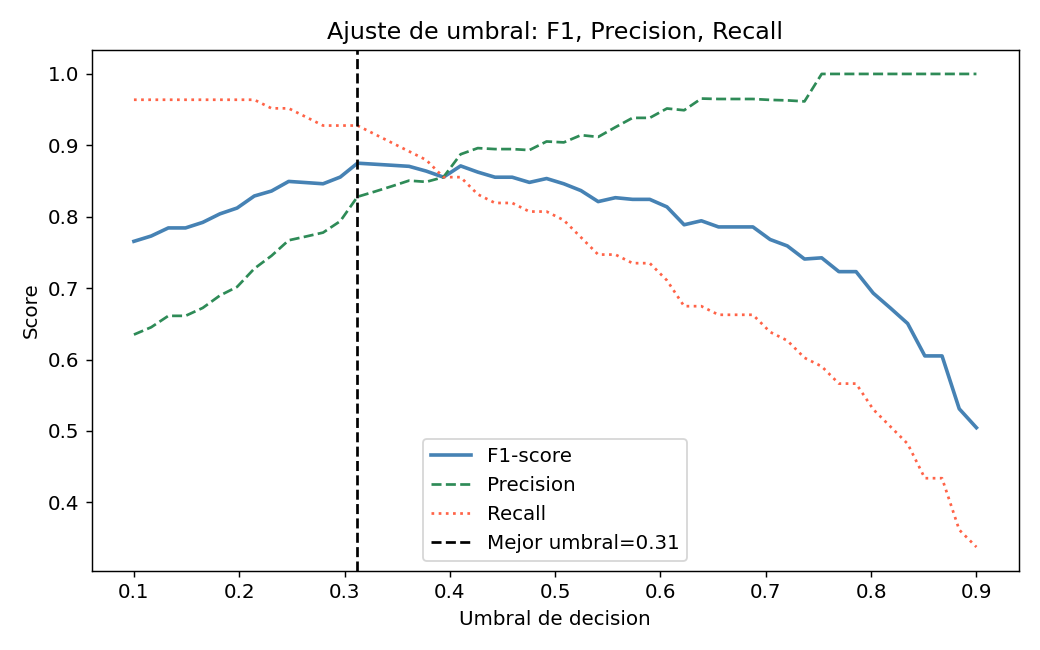
from sklearn.metrics import f1_score, precision_score, recall_score
# Buscar umbral que maximiza F1
thresholds = np.linspace(0.1, 0.9, 100)
best_f1, best_threshold = 0, 0.5
for t in thresholds:
preds_t = (y_proba >= t).astype(int)
f1 = f1_score(y_te, preds_t, zero_division=0)
if f1 > best_f1:
best_f1 = f1
best_threshold = t
print(f"Umbral optimo para F1: {best_threshold:.3f}")
print(f"F1 con umbral 0.5: {f1_score(y_te, (y_proba >= 0.5).astype(int)):.4f}")
print(f"F1 con umbral optimo: {best_f1:.4f}")
# Aplicar en produccion
y_final = (y_proba >= best_threshold).astype(int)
Cuando bajar el umbral (mas Recall):
Deteccion de cancer, fraude, falla critica — preferimos no perder ningun positivo aunque haya mas falsos positivos.
Cuando subir el umbral (mas Precision):
Spam, recomendaciones — preferimos estar seguros antes de marcar algo como positivo.
11. Pipeline completo con preprocesamiento
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import StratifiedKFold, cross_val_score
import pandas as pd
# Dataset con features mixtas
np.random.seed(42)
n = 800
df = pd.DataFrame({
"edad": np.random.randint(18, 70, n),
"salario": np.random.normal(50000, 20000, n).clip(10000, 200000),
"ciudad": np.random.choice(["La Paz", "Cochabamba", "Santa Cruz", "Oruro"], n),
"deuda": np.random.normal(5000, 3000, n).clip(0, 50000),
})
# Target: riesgo alto (1) o bajo (0)
df["riesgo"] = ((df["deuda"] / df["salario"] > 0.15) |
(df["edad"] < 25)).astype(int)
# Introducir nulos
df.loc[np.random.choice(n, 50, replace=False), "salario"] = np.nan
df.loc[np.random.choice(n, 30, replace=False), "deuda"] = np.nan
X = df.drop("riesgo", axis=1)
y = df["riesgo"]
# Separar por tipo
num_cols = ["edad", "salario", "deuda"]
cat_cols = ["ciudad"]
num_transformer = Pipeline([
("imputer", SimpleImputer(strategy="median")),
("scaler", StandardScaler()),
])
cat_transformer = Pipeline([
("imputer", SimpleImputer(strategy="most_frequent")),
("ohe", OneHotEncoder(handle_unknown="ignore", sparse_output=False)),
])
preprocessor = ColumnTransformer([
("num", num_transformer, num_cols),
("cat", cat_transformer, cat_cols),
])
pipeline = Pipeline([
("prep", preprocessor),
("model", RandomForestClassifier(n_estimators=200, min_samples_leaf=5,
n_jobs=-1, random_state=42)),
])
# Validacion estratificada (mantiene proporcion de clases por fold)
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(pipeline, X, y, cv=skf, scoring="roc_auc")
print(f"ROC-AUC CV: {scores.mean():.4f} ± {scores.std():.4f}")
12. Clasificacion multiclase
from sklearn.datasets import load_iris
from sklearn.metrics import roc_auc_score
iris = load_iris()
X_ir, y_ir = iris.data, iris.target
X_tr_ir, X_te_ir, y_tr_ir, y_te_ir = train_test_split(X_ir, y_ir,
test_size=0.2, random_state=0)
rf_mc = RandomForestClassifier(n_estimators=100, random_state=42)
rf_mc.fit(X_tr_ir, y_tr_ir)
y_proba_mc = rf_mc.predict_proba(X_te_ir)
print(f"Accuracy: {rf_mc.score(X_te_ir, y_te_ir):.4f}")
# ROC-AUC multiclase: OvR (One vs Rest)
print(f"ROC-AUC OvR: {roc_auc_score(y_te_ir, y_proba_mc, multi_class='ovr'):.4f}")
# OvO (One vs One) — mejor para clases desbalanceadas
print(f"ROC-AUC OvO: {roc_auc_score(y_te_ir, y_proba_mc, multi_class='ovo'):.4f}")
# Reporte completo
print(classification_report(y_te_ir, rf_mc.predict(X_te_ir),
target_names=iris.target_names))
13. Dashboard visual completo
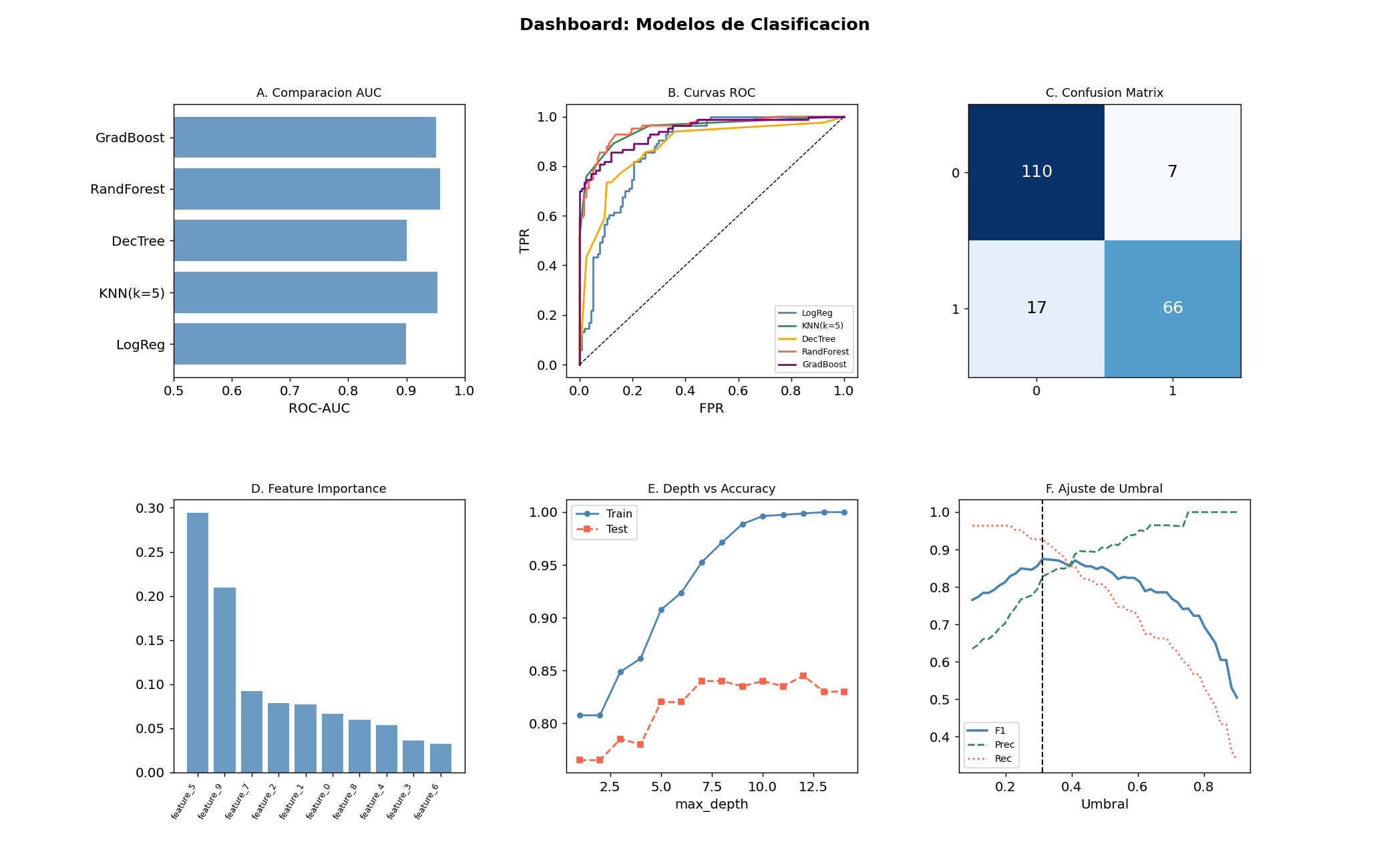
Panel A: comparacion de AUC entre modelos
Panel B: curvas ROC superpuestas
Panel C: matriz de confusion del mejor modelo
Panel D: importancia de features
Panel E: profundidad del arbol vs accuracy (overfitting)
Panel F: ajuste de umbral — F1, Precision, Recall
Mini-proyecto: clasificador de riesgo crediticio
Paso 1: explorar el desbalance
print(f"Distribucion de clases:\n{y.value_counts(normalize=True).round(3)}")
# Si una clase tiene menos del 20%, es un dataset desbalanceado
# Estrategias: class_weight='balanced', oversampling (SMOTE), undersampling
Paso 2: baseline y comparacion
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
modelos_comp = {
"LogReg": Pipeline([("prep", preprocessor), ("model", LogisticRegression(max_iter=1000, class_weight='balanced'))]),
"RF": Pipeline([("prep", preprocessor), ("model", RandomForestClassifier(n_estimators=100, class_weight='balanced', random_state=42))]),
"GBM": Pipeline([("prep", preprocessor), ("model", GradientBoostingClassifier(n_estimators=100, random_state=42))]),
}
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
for nombre, pipe in modelos_comp.items():
sc = cross_val_score(pipe, X, y, cv=skf, scoring="roc_auc")
print(f"{nombre:<10} AUC = {sc.mean():.4f} ± {sc.std():.4f}")
Paso 3: tuning del mejor modelo
from sklearn.model_selection import RandomizedSearchCV
param_dist = {
"model__n_estimators": [100, 200, 300],
"model__max_depth": [3, 5, None],
"model__min_samples_leaf": [5, 10, 20],
"model__max_features": ["sqrt", "log2"],
}
best_pipe = modelos_comp["RF"]
search = RandomizedSearchCV(best_pipe, param_dist, n_iter=20, cv=skf,
scoring="roc_auc", random_state=42, n_jobs=-1)
search.fit(X, y)
print(f"Mejor AUC: {search.best_score_:.4f}")
print(f"Mejores params: {search.best_params_}")
Paso 4: reporte final
X_tr_f, X_te_f, y_tr_f, y_te_f = train_test_split(X, y, test_size=0.2,
random_state=42, stratify=y)
search.best_estimator_.fit(X_tr_f, y_tr_f)
y_proba_f = search.best_estimator_.predict_proba(X_te_f)[:, 1]
# Ajustar umbral para maximizar F1
best_f1_f, best_t_f = 0, 0.5
for t in np.linspace(0.1, 0.9, 100):
f1 = f1_score(y_te_f, (y_proba_f >= t).astype(int), zero_division=0)
if f1 > best_f1_f:
best_f1_f, best_t_f = f1, t
y_final_f = (y_proba_f >= best_t_f).astype(int)
print(f"\nReporte final (umbral={best_t_f:.2f}):")
print(classification_report(y_te_f, y_final_f))
print(f"ROC-AUC: {roc_auc_score(y_te_f, y_proba_f):.4f}")
Errores comunes
| Error | Descripcion | Solucion |
|---|---|---|
| Usar solo accuracy | Engañosa en clases desbalanceadas | Reporta siempre F1, ROC-AUC y matriz de confusion |
| No usar StratifiedKFold | Folds sin la proporcion correcta de clases | StratifiedKFold(shuffle=True) siempre |
| Umbral fijo de 0.5 | No optimo para tu metrica objetivo | Ajusta el umbral segun el costo del negocio |
| Ignorar class_weight | El modelo ignora la clase minoritaria | class_weight='balanced' o SMOTE |
| Fuga de datos en el pipeline | El scaler ve datos de test durante fit | Siempre usa Pipeline — nunca fit_transform en todo el dataset |
| Demasiado tuning al leaderboard publico | Overfitting al test publico | Valida localmente con CV, submission con cautela |
Seccion avanzada
Datasets desbalanceados con imbalanced-learn
# pip install imbalanced-learn
from imblearn.over_sampling import SMOTE
from imblearn.pipeline import Pipeline as ImbPipeline
# SMOTE genera ejemplos sinteticos de la clase minoritaria
smote_pipe = ImbPipeline([
("prep", preprocessor),
("smote", SMOTE(random_state=42)),
("model", RandomForestClassifier(n_estimators=100, random_state=42)),
])
scores_smote = cross_val_score(smote_pipe, X, y, cv=skf, scoring="roc_auc")
print(f"Con SMOTE: {scores_smote.mean():.4f}")
Calibracion de probabilidades
from sklearn.calibration import CalibratedClassifierCV, calibration_curve
# Los arboles suelen tener probabilidades mal calibradas
rf_cal = CalibratedClassifierCV(
RandomForestClassifier(n_estimators=100, random_state=42),
method="isotonic", # o "sigmoid"
cv=5
)
rf_cal.fit(X_tr_s, y_tr)
prob_cal = rf_cal.predict_proba(X_te_s)[:, 1]
# Curva de calibracion
frac_pos, mean_pred = calibration_curve(y_te, prob_cal, n_bins=10)
plt.plot(mean_pred, frac_pos, "s-", label="Calibrado")
plt.plot([0,1],[0,1],"k--", label="Perfectamente calibrado")
plt.xlabel("Probabilidad predicha")
plt.ylabel("Fraccion de positivos reales")
plt.title("Curva de calibracion")
plt.legend()
plt.show()
Recursos recomendados
- Documentacion sklearn: clasificadores: referencia de todos los clasificadores con ejemplos
- XGBoost docs: documentacion oficial con guias de uso y parametros
- ISLR capitulos 4 y 8 (libro gratuito): clasificacion y metodos basados en arboles
- imbalanced-learn: guia practica de metricas y tecnicas para datos desbalanceados