7. Modelos de Regresion
Por que importa en competencias de IA
La mayoria de retos tabulares en olimpiadas de IA son problemas de regresion: predecir precios, cantidades, puntajes o tiempos. Saber elegir entre regresion lineal, regularizada o polinomial — y saber diagnosticar errores con graficos — marca la diferencia entre un score mediocre y un top-10.
Mapa de este tema:
- Regresion lineal desde cero (ecuacion normal y sklearn)
- Funcion de costo MSE y metricas asociadas
- Descenso de gradiente paso a paso
- Regresion polinomial y sesgo-varianza
- Regularizacion Ridge (L2) y Lasso (L1)
- ElasticNet y como elegir alpha
- Diagnostico visual: residuos y curvas de aprendizaje
- Mini-proyecto: prediccion de precios
1. Regresion lineal
La regresion lineal simple modela la relacion entre una variable de entrada x y una salida y como una linea recta:
En forma matricial para multiples features:
donde X es la matriz de diseno (n_samples x n_features) y w es el vector de pesos.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# Datos sinteticos: y = 3x + 7 + ruido
np.random.seed(42)
n = 200
X = np.random.rand(n, 1) * 10
y = 3 * X.ravel() + 7 + np.random.randn(n) * 4
# Entrenar
model = LinearRegression()
model.fit(X, y)
print(f"Intercepto (w0): {model.intercept_:.3f}") # ~7
print(f"Pendiente (w1): {model.coef_[0]:.3f}") # ~3
y_pred = model.predict(X)
# Metricas
mse = mean_squared_error(y, y_pred)
rmse = np.sqrt(mse)
mae = mean_absolute_error(y, y_pred)
r2 = r2_score(y, y_pred)
print(f"MSE: {mse:.2f}")
print(f"RMSE: {rmse:.2f}")
print(f"MAE: {mae:.2f}")
print(f"R²: {r2:.4f}")
El grafico de prediccion vs real es la primera revision que debes hacer siempre:
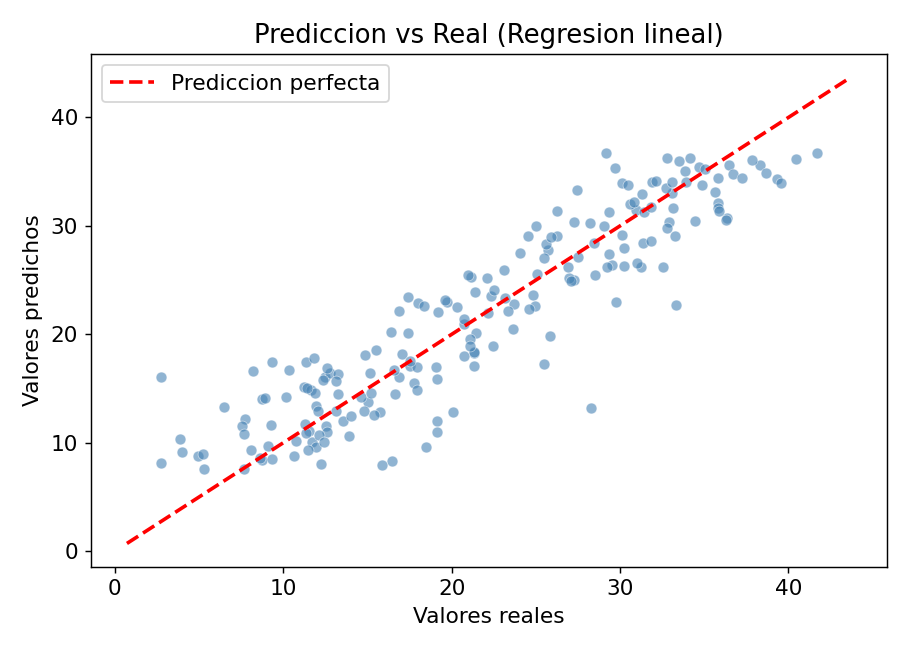
Los puntos deben seguir la linea roja diagonal. Si hay una curva sistematica, el modelo lineal no captura toda la estructura.
Ecuacion normal (solucion analitica)
Para datasets pequenos puedes obtener la solucion exacta en una sola operacion:
# Ecuacion normal manualmente
X_b = np.c_[np.ones((n, 1)), X] # agrega columna de 1s (bias)
w_opt = np.linalg.inv(X_b.T @ X_b) @ X_b.T @ y
print(f"w0={w_opt[0]:.3f}, w1={w_opt[1]:.3f}")
# Limitacion: O(n_features^3) — lento con muchas features
# Para datasets grandes usa sklearn con solver='lsqr' o descenso de gradiente
2. Funcion de costo: MSE
La funcion que minimiza la regresion lineal es el Error Cuadratico Medio:
# Comparacion de metricas: cuando usar cada una
# MSE: penaliza errores grandes fuertemente (sensible a outliers)
# MAE: penaliza todos los errores por igual (robusta a outliers)
# RMSE: mismas unidades que y, facil de interpretar
# R²: proporcion de varianza explicada (1 = perfecto, 0 = modelo nulo)
# Ejemplo: impacto de un outlier
y_con_outlier = y.copy()
y_con_outlier[0] = y.max() * 3 # outlier extremo
print("Sin outlier:")
print(f" MSE={mean_squared_error(y, y_pred):.2f}, MAE={mean_absolute_error(y, y_pred):.2f}")
y_pred_out = model.predict(X) # mismo modelo
print("Con outlier en y_true:")
print(f" MSE={mean_squared_error(y_con_outlier, y_pred_out):.2f}")
print(f" MAE={mean_absolute_error(y_con_outlier, y_pred_out):.2f}")
# MSE sube dramaticamente, MAE mucho menos
3. Descenso de gradiente
Para datasets grandes la ecuacion normal es muy lenta. El descenso de gradiente actualiza los pesos iterativamente:
donde eta es la tasa de aprendizaje (learning rate).
# Descenso de gradiente batch para regresion lineal
def gradient_descent(X, y, lr=0.01, n_iter=100):
m, n = X.shape
w = np.zeros(n)
history = []
for _ in range(n_iter):
preds = X @ w
error = preds - y
grad = (2 / m) * X.T @ error # gradiente del MSE
w -= lr * grad
history.append(np.mean(error ** 2))
return w, history
# Agrega columna de bias
X_b = np.c_[np.ones(n), X.ravel()]
w_gd, cost_history = gradient_descent(X_b, y, lr=0.01, n_iter=200)
print(f"w0={w_gd[0]:.3f}, w1={w_gd[1]:.3f}")
# Comparacion con sklearn
print(f"sklearn: w0={model.intercept_:.3f}, w1={model.coef_[0]:.3f}")
El grafico de convergencia muestra como cae el MSE con cada iteracion:
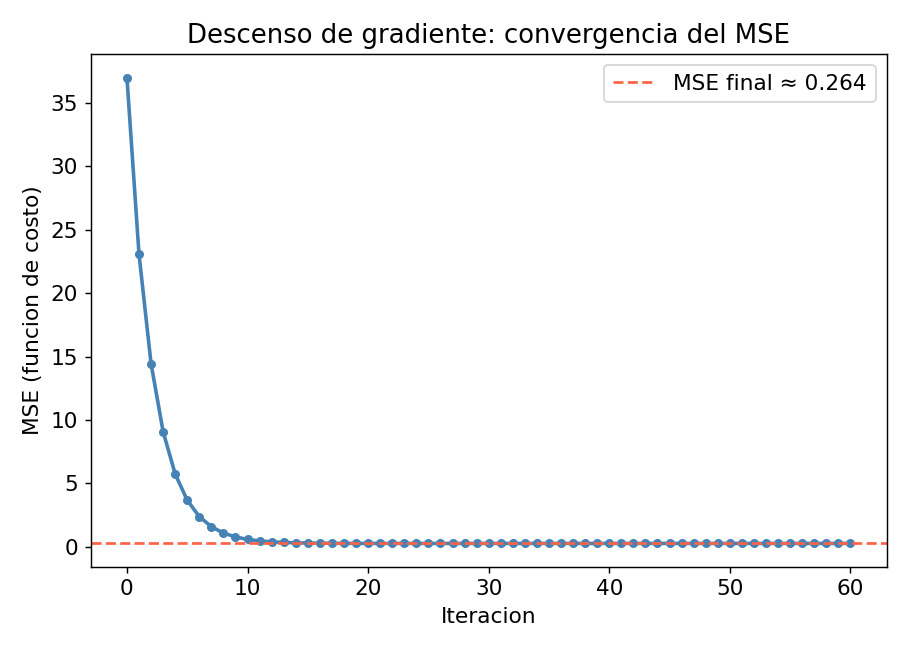
Efecto del learning rate:
fig, axes = plt.subplots(1, 3, figsize=(14, 4))
for ax, lr_val, color in zip(axes, [0.001, 0.01, 0.5], ['steelblue', 'seagreen', 'tomato']):
_, hist = gradient_descent(X_b, y, lr=lr_val, n_iter=200)
ax.plot(hist, color=color, linewidth=2)
ax.set_title(f"lr = {lr_val}", fontsize=12)
ax.set_xlabel("Iteracion")
ax.set_ylabel("MSE")
# lr muy pequeno: convergencia lenta
# lr optimo: converge suave
# lr muy grande: puede divergir (explotar)
plt.tight_layout()
plt.show()
Regla practica: Empieza con lr=0.01, observa la curva de costo. Si oscila, baja lr. Si cae muy lento, subelo 10x.
4. Regresion polinomial y el dilema sesgo-varianza
La regresion polinomial expande las features con potencias: x, x², x³, ...
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.model_selection import cross_val_score
np.random.seed(0)
Xp = np.linspace(0, 1, 40).reshape(-1, 1)
yp = np.sin(2 * np.pi * Xp.ravel()) + np.random.randn(40) * 0.3
# Pipeline: PolynomialFeatures -> LinearRegression
for grado in [1, 2, 4, 8, 15]:
pipe = Pipeline([
("poly", PolynomialFeatures(degree=grado, include_bias=False)),
("lr", LinearRegression())
])
scores = cross_val_score(pipe, Xp, yp, cv=5, scoring="neg_mean_squared_error")
rmse_cv = np.sqrt(-scores.mean())
print(f"Grado {grado:2d}: CV RMSE = {rmse_cv:.4f}")
Grado 1: CV RMSE = 0.4221 # underfitting (alto sesgo)
Grado 2: CV RMSE = 0.3908
Grado 4: CV RMSE = 0.2854 # buena zona
Grado 8: CV RMSE = 0.3102
Grado 15: CV RMSE = 0.7841 # overfitting (alta varianza)
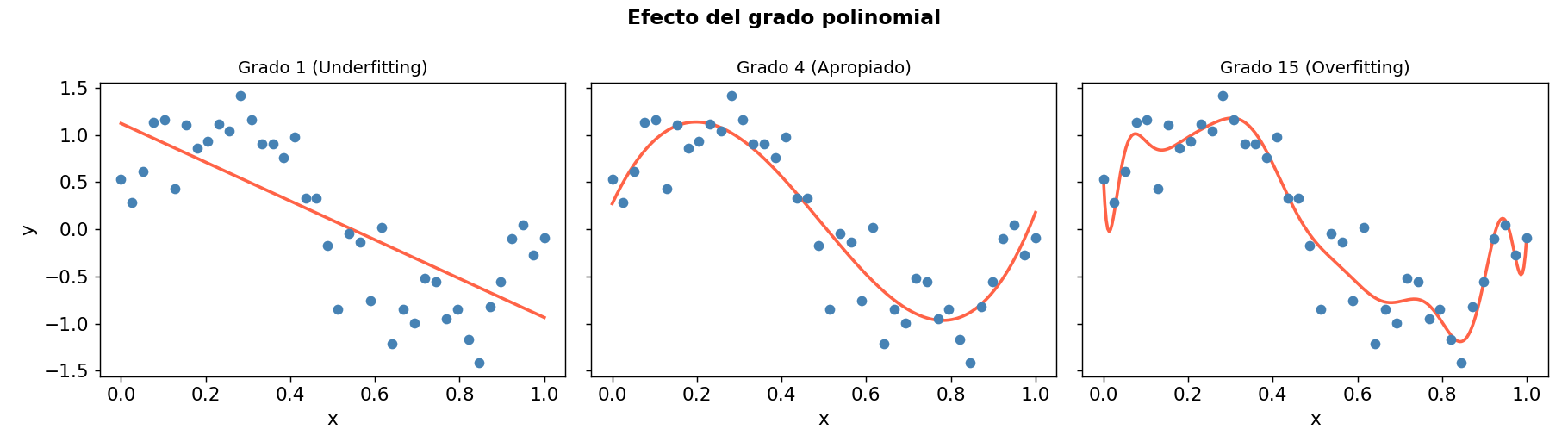
El grafico muestra los tres estados clasicos:
- Grado 1 (underfitting): la linea no captura la curvatura.
- Grado 4 (apropiado): ajusta bien sin memorizar.
- Grado 15 (overfitting): pasa exactamente por cada punto de entrenamiento pero generaliza mal.
Curvas de aprendizaje: diagnostico rapido
Las curvas de aprendizaje muestran como evolucionan el error de entrenamiento y validacion al aumentar la cantidad de datos:
from sklearn.model_selection import learning_curve
def plot_learning_curve(model, X, y, title):
train_sizes, train_scores, val_scores = learning_curve(
model, X, y, cv=5,
scoring="neg_mean_squared_error",
train_sizes=np.linspace(0.1, 1.0, 10)
)
train_rmse = np.sqrt(-train_scores.mean(axis=1))
val_rmse = np.sqrt(-val_scores.mean(axis=1))
plt.figure(figsize=(7, 4))
plt.plot(train_sizes, train_rmse, "o-", label="Train RMSE")
plt.plot(train_sizes, val_rmse, "s--", label="Validacion RMSE")
plt.xlabel("Ejemplos de entrenamiento")
plt.ylabel("RMSE")
plt.title(title)
plt.legend()
plt.show()
from sklearn.datasets import make_regression
Xl, yl = make_regression(n_samples=300, n_features=5, noise=2, random_state=7)
# Modelo correcto
plot_learning_curve(LinearRegression(), Xl, yl, "Modelo apropiado")
# Modelo con underfitting
pipe_under = Pipeline([("poly", PolynomialFeatures(1)), ("lr", LinearRegression())])
plot_learning_curve(pipe_under, Xp, yp, "Underfitting: ambas curvas altas")
# Modelo con overfitting
pipe_over = Pipeline([("poly", PolynomialFeatures(15)), ("lr", LinearRegression())])
plot_learning_curve(pipe_over, Xp, yp, "Overfitting: gap grande")
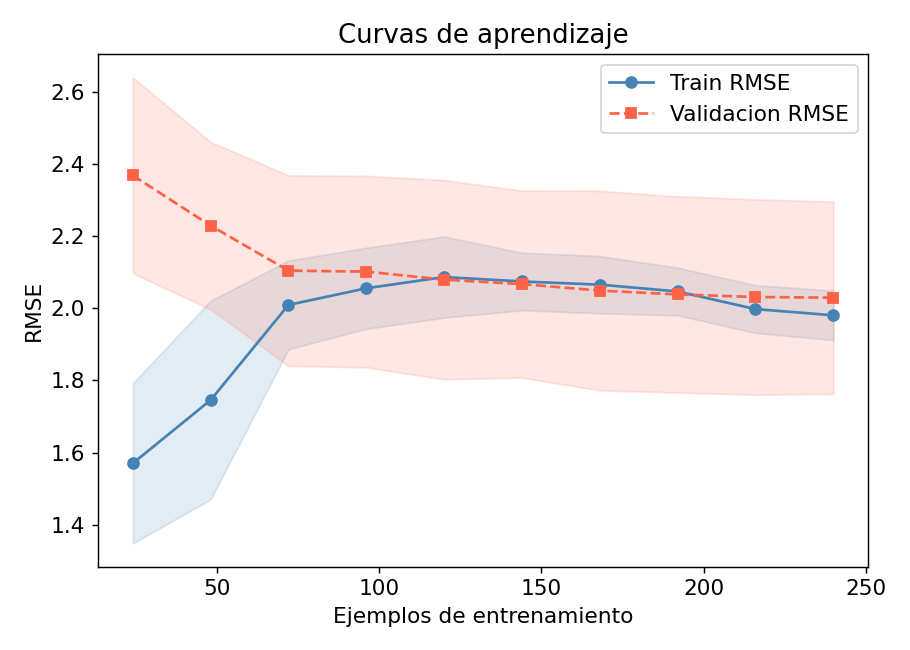
Lectura del grafico:
| Patron observado | Diagnostico | Solucion |
|---|---|---|
| Ambas curvas altas y juntas | Alto sesgo (underfitting) | Mas features, modelo mas complejo |
| Gran brecha train-val | Alta varianza (overfitting) | Mas datos, regularizacion, menos features |
| Val baja y estable | Buen ajuste | Optimizar hiperparametros |
5. Regularizacion: Ridge (L2) y Lasso (L1)
La regularizacion agrega una penalizacion a la funcion de costo para evitar coeficientes extremos:
Ridge (L2):
Lasso (L1):
from sklearn.linear_model import Ridge, Lasso, ElasticNet
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_regression
# IMPORTANTE: siempre escalar antes de regularizar
Xr, yr = make_regression(n_samples=200, n_features=20,
n_informative=5, noise=15, random_state=42)
scaler = StandardScaler()
Xr_s = scaler.fit_transform(Xr)
# Comparacion directa
from sklearn.model_selection import train_test_split
X_tr, X_te, y_tr, y_te = train_test_split(Xr_s, yr, test_size=0.2, random_state=0)
modelos = {
"LinearRegression": LinearRegression(),
"Ridge(alpha=1)": Ridge(alpha=1),
"Ridge(alpha=100)": Ridge(alpha=100),
"Lasso(alpha=1)": Lasso(alpha=1, max_iter=5000),
"Lasso(alpha=10)": Lasso(alpha=10, max_iter=5000),
"ElasticNet": ElasticNet(alpha=1, l1_ratio=0.5, max_iter=5000),
}
for nombre, mod in modelos.items():
mod.fit(X_tr, y_tr)
rmse = np.sqrt(mean_squared_error(y_te, mod.predict(X_te)))
n_zero = np.sum(np.abs(mod.coef_) < 1e-4) if hasattr(mod, "coef_") else 0
print(f"{nombre:<25} RMSE={rmse:.2f} coefs_cero={n_zero}")
LinearRegression RMSE=14.87 coefs_cero=0
Ridge(alpha=1) RMSE=14.12 coefs_cero=0 # shrinkage suave
Ridge(alpha=100) RMSE=15.44 coefs_cero=0 # demasiado shrinkage
Lasso(alpha=1) RMSE=14.08 coefs_cero=11 # seleccion automatica!
Lasso(alpha=10) RMSE=17.21 coefs_cero=18 # demasiado sparse
ElasticNet RMSE=14.30 coefs_cero=6
Efecto visual en los coeficientes
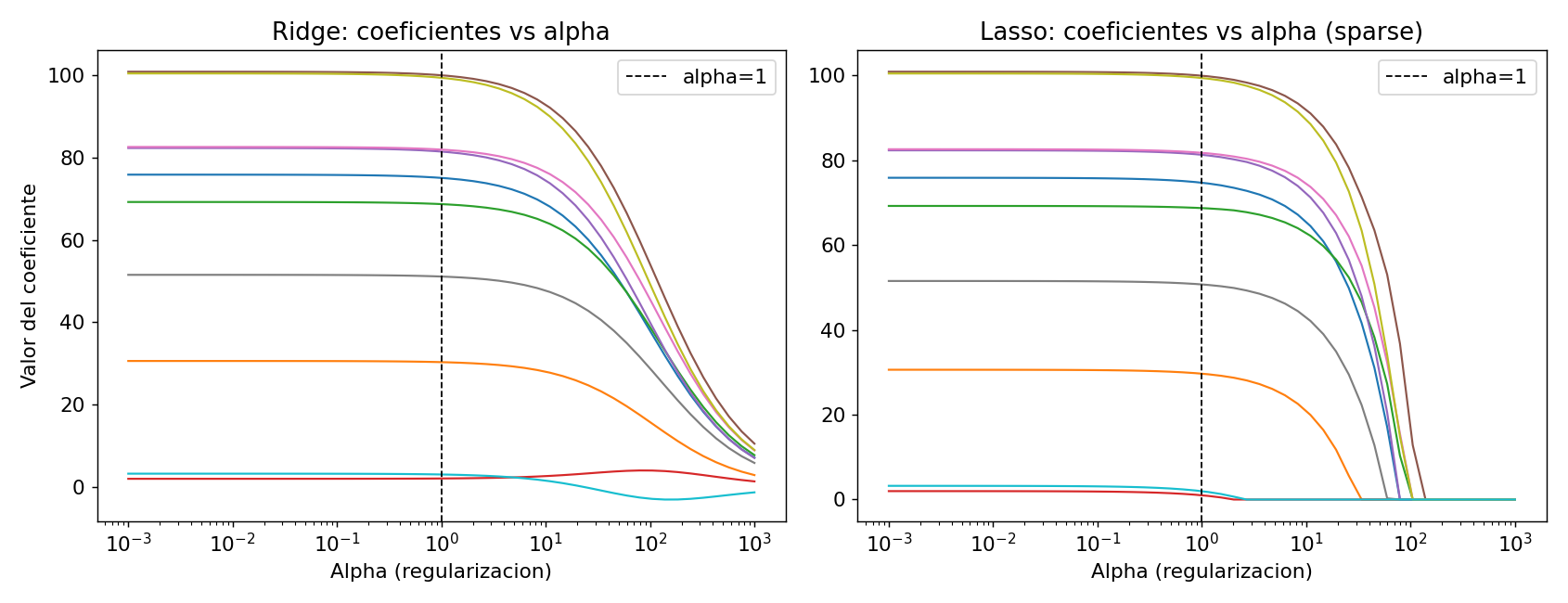
Ridge: todos los coeficientes se reducen suavemente pero ninguno llega exactamente a cero.
Lasso: los coeficientes van a cero bruscamente — esto es seleccion de features automatica.
Comparacion de RMSE en test por alpha
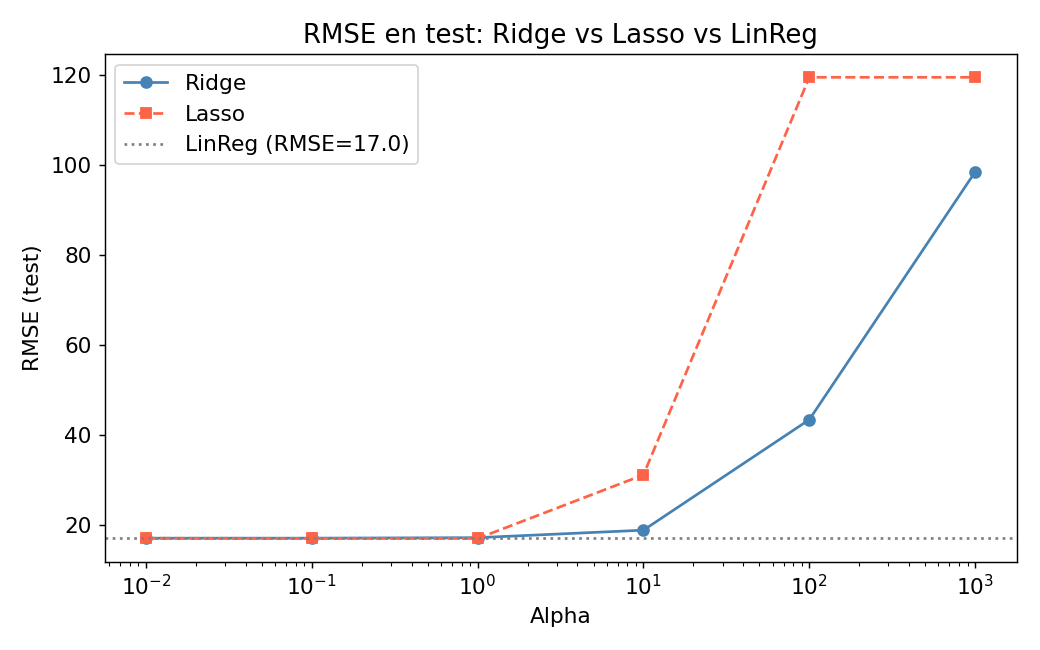
La linea gris punteada es el baseline de regresion lineal sin regularizacion. Nota como valores extremos de alpha deterioran el modelo.
Como elegir alpha: RidgeCV / LassoCV
from sklearn.linear_model import RidgeCV, LassoCV
# RidgeCV prueba multiples alphas con validacion cruzada interna
ridge_cv = RidgeCV(alphas=np.logspace(-3, 3, 50), cv=5)
ridge_cv.fit(X_tr, y_tr)
print(f"Mejor alpha Ridge: {ridge_cv.alpha_:.4f}")
print(f"RMSE: {np.sqrt(mean_squared_error(y_te, ridge_cv.predict(X_te))):.2f}")
# LassoCV igual
lasso_cv = LassoCV(alphas=np.logspace(-3, 2, 50), cv=5, max_iter=10000)
lasso_cv.fit(X_tr, y_tr)
print(f"Mejor alpha Lasso: {lasso_cv.alpha_:.4f}")
print(f"RMSE: {np.sqrt(mean_squared_error(y_te, lasso_cv.predict(X_te))):.2f}")
# Features seleccionadas por Lasso
feature_names = [f"x{i}" for i in range(Xr_s.shape[1])]
seleccionadas = [name for name, coef in zip(feature_names, lasso_cv.coef_)
if abs(coef) > 1e-4]
print(f"Features seleccionadas: {seleccionadas}")
ElasticNet: lo mejor de ambos mundos
from sklearn.linear_model import ElasticNetCV
# l1_ratio=0 es Ridge puro, l1_ratio=1 es Lasso puro
enet_cv = ElasticNetCV(
l1_ratio=[0.1, 0.3, 0.5, 0.7, 0.9, 0.95, 1.0],
alphas=np.logspace(-3, 2, 30),
cv=5, max_iter=10000
)
enet_cv.fit(X_tr, y_tr)
print(f"Mejor alpha={enet_cv.alpha_:.4f}, l1_ratio={enet_cv.l1_ratio_:.2f}")
Regla practica: Usa Ridge cuando creas que todas las features contribuyen. Usa Lasso cuando sospechas que muchas son irrelevantes. Usa ElasticNet cuando hay features correlacionadas entre si.
6. Analisis de residuos
Los residuos son la diferencia entre el valor real y el predicho: e = y - y_pred. Un modelo bien ajustado tiene residuos que parecen ruido blanco.
from sklearn.linear_model import LinearRegression
import scipy.stats as stats
model = LinearRegression().fit(X_tr, y_tr)
y_pred_tr = model.predict(X_tr)
residuals = y_tr - y_pred_tr
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
# 1. Residuos vs predichos
axes[0].scatter(y_pred_tr, residuals, alpha=0.5, color='coral')
axes[0].axhline(0, color='black', linestyle='--')
axes[0].set_xlabel("Predichos")
axes[0].set_ylabel("Residuos")
axes[0].set_title("Residuos vs Predichos")
# 2. Histograma de residuos
axes[1].hist(residuals, bins=30, color='steelblue', edgecolor='white')
axes[1].set_title("Distribucion de residuos")
# 3. Q-Q plot
stats.probplot(residuals, dist="norm", plot=axes[2])
axes[2].set_title("Q-Q Plot (normalidad)")
plt.tight_layout()
plt.show()
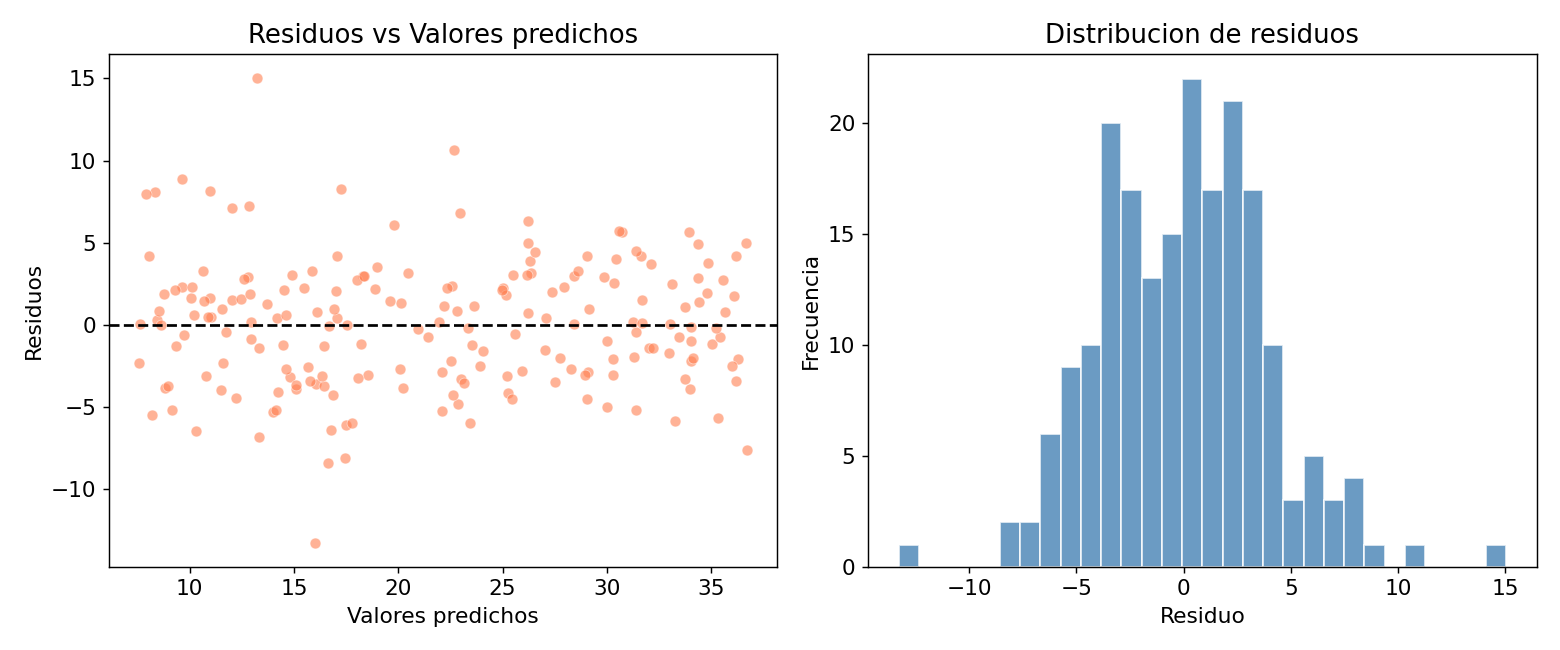
Como leer el grafico de residuos:
| Patron en residuos vs predichos | Significado |
|---|---|
| Nube aleatoria alrededor de 0 | Modelo correcto |
| Patron en U o curva | Falta termino no lineal |
| Embudo (heterocedasticidad) | Varianza no constante — considera log(y) |
| Patron periodico | Feature temporal no incluida |
# Solucion para heterocedasticidad: transformar la variable objetivo
import numpy as np
# Si log(y) tiene residuos mas uniformes, usar log
y_log = np.log1p(y_te) # log1p = log(1 + y) para evitar log(0)
model_log = LinearRegression().fit(X_tr, np.log1p(y_tr))
preds_log = np.expm1(model_log.predict(X_te)) # deshacer la transformacion
rmse_log = np.sqrt(mean_squared_error(y_te, preds_log))
print(f"RMSE con log(y): {rmse_log:.2f}")
7. Pipeline completo con preprocesamiento
En competencias, la regresion rara vez se aplica directamente. Siempre va dentro de un pipeline:
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
import pandas as pd
import numpy as np
# Dataset sintetico con features numericas y categoricas
np.random.seed(42)
n = 500
df = pd.DataFrame({
"area": np.random.normal(1400, 400, n).clip(300, 5000),
"calidad": np.random.randint(1, 11, n),
"barrio": np.random.choice(["Norte", "Sur", "Centro", "Este"], n),
"antiguedad": np.random.randint(0, 50, n),
"precio": None
})
df["precio"] = (
50000
+ df["area"] * 120
+ df["calidad"] * 15000
+ df["barrio"].map({"Norte": 20000, "Sur": -10000, "Centro": 5000, "Este": -5000})
- df["antiguedad"] * 500
+ np.random.randn(n) * 30000
)
X = df.drop("precio", axis=1)
y = np.log1p(df["precio"]) # transformacion logaritmica
# Separar features por tipo
num_features = ["area", "calidad", "antiguedad"]
cat_features = ["barrio"]
# Preprocesador
num_pipe = Pipeline([
("imputer", SimpleImputer(strategy="median")),
("scaler", StandardScaler()),
])
cat_pipe = Pipeline([
("imputer", SimpleImputer(strategy="most_frequent")),
("ohe", OneHotEncoder(handle_unknown="ignore", sparse_output=False)),
])
preprocessor = ColumnTransformer([
("num", num_pipe, num_features),
("cat", cat_pipe, cat_features),
])
# Pipeline final
pipeline = Pipeline([
("prep", preprocessor),
("model", Ridge(alpha=10)),
])
# Validacion cruzada
scores = cross_val_score(pipeline, X, y, cv=5,
scoring="neg_root_mean_squared_error")
print(f"CV RMSE (log-espacio): {(-scores.mean()):.4f} ± {scores.std():.4f}")
# Para interpretar en espacio original: deshacer log
# rmse_original = np.expm1(rmse_log) es una aproximacion
8. Diagnostico visual completo
El dashboard de abajo resume los 6 graficos clave para cualquier proyecto de regresion:
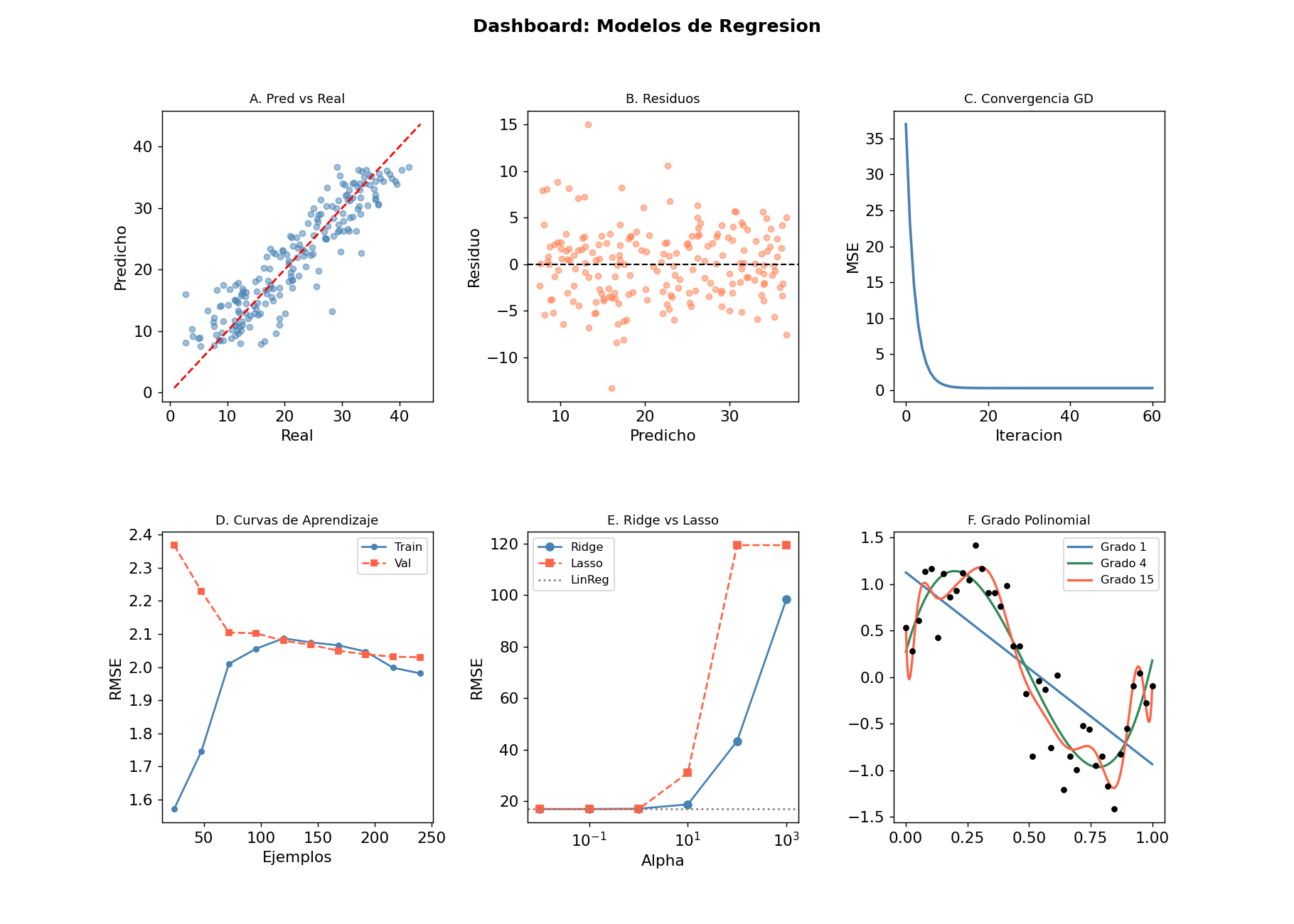
Panel por panel:
- A. Pred vs Real: busca que los puntos sigan la diagonal
- B. Residuos: busca nube aleatoria alrededor de 0
- C. Convergencia GD: confirma que el costo cae y se estabiliza
- D. Curvas de aprendizaje: diagnostica underfitting/overfitting
- E. Ridge vs Lasso: elige alpha optimo por RMSE en test
- F. Grado polinomial: visualiza el efecto sesgo-varianza
9. Mini-proyecto: prediccion de precios de casas
Objetivo: predecir el precio de casas dado area, calidad, barrio y antiguedad. Reportar RMSE y analizar residuos.
Paso 1: Explorar y limpiar
import pandas as pd
import numpy as np
# Carga (usa el dataset sintetico o descarga Ames Housing)
# df = pd.read_csv("train.csv")
# Revision rapida
print(df.dtypes)
print(df.isnull().sum())
print(df.describe())
# Variables objetivo: transformar si es asimetrica
print(f"Skewness precio: {df['precio'].skew():.2f}")
# Si skew > 1, aplicar log1p
Paso 2: Feature engineering basico
# Features derivadas utiles para precios de casas
df["log_area"] = np.log1p(df["area"])
df["calidad_cuadrada"] = df["calidad"] ** 2 # efecto cuadratico de calidad
df["casa_nueva"] = (df["antiguedad"] < 5).astype(int)
# Interacciones
df["area_calidad"] = df["log_area"] * df["calidad"]
Paso 3: Baseline y mejoras iterativas
from sklearn.linear_model import LinearRegression, RidgeCV, LassoCV
from sklearn.model_selection import KFold, cross_val_score
kf = KFold(n_splits=5, shuffle=True, random_state=42)
resultados = {}
# Baseline: regresion lineal sin feature engineering
pipe_base = Pipeline([("prep", preprocessor), ("model", LinearRegression())])
scores = cross_val_score(pipe_base, X, y, cv=kf, scoring="neg_root_mean_squared_error")
resultados["LinearReg baseline"] = -scores.mean()
# Ridge con CV
pipe_ridge = Pipeline([("prep", preprocessor), ("model", RidgeCV(alphas=np.logspace(-2, 3, 50), cv=5))])
scores = cross_val_score(pipe_ridge, X, y, cv=kf, scoring="neg_root_mean_squared_error")
resultados["RidgeCV"] = -scores.mean()
# Lasso con CV
pipe_lasso = Pipeline([("prep", preprocessor), ("model", LassoCV(alphas=np.logspace(-3, 2, 50), cv=5, max_iter=10000))])
scores = cross_val_score(pipe_lasso, X, y, cv=kf, scoring="neg_root_mean_squared_error")
resultados["LassoCV"] = -scores.mean()
for nombre, rmse in sorted(resultados.items(), key=lambda x: x[1]):
print(f"{nombre:<30} RMSE = {rmse:.5f}")
Paso 4: Analizar coeficientes
# Entrenar RidgeCV final en todos los datos de entrenamiento
pipe_ridge.fit(X, y)
ridge_model = pipe_ridge.named_steps["model"]
# Obtener nombres de features despues del preprocesamiento
num_names = num_features
cat_names = list(pipe_ridge.named_steps["prep"]
.named_transformers_["cat"]
.named_steps["ohe"]
.get_feature_names_out(cat_features))
all_names = num_names + cat_names
coefs = pd.Series(ridge_model.coef_, index=all_names).sort_values(key=abs, ascending=False)
print("\nTop coeficientes (por magnitud):")
print(coefs.head(10))
Paso 5: Reporte de errores por segmento
# Predecir en conjunto de prueba
X_tr2, X_te2, y_tr2, y_te2 = train_test_split(X, y, test_size=0.2, random_state=0)
pipe_ridge.fit(X_tr2, y_tr2)
y_pred2 = pipe_ridge.predict(X_te2)
# Reporte global
print(f"RMSE test (log): {np.sqrt(mean_squared_error(y_te2, y_pred2)):.5f}")
print(f"R² test: {r2_score(y_te2, y_pred2):.4f}")
# Errores por barrio
X_te2_copia = X_te2.copy()
X_te2_copia["error_abs"] = np.abs(y_te2.values - y_pred2)
print("\nError medio por barrio:")
print(X_te2_copia.groupby("barrio")["error_abs"].mean().sort_values(ascending=False))
Errores comunes y como evitarlos
| Error | Descripcion | Solucion |
|---|---|---|
| No escalar antes de Ridge/Lasso | Coeficientes sesgados por magnitud de features | Siempre usa StandardScaler en el pipeline antes de regularizar |
| Interpretar coeficientes Lasso como causalidad | Un coef=0 no significa que la feature es inutil, puede estar correlacionada con otra | Usa VIF o analisis de correlacion |
| Ignorar outliers extremos | MSE les da peso cuadratico enorme | Revisa boxplots, considera HuberRegressor o transformar y |
| Ajustar grado polinomial alto sin validacion cruzada | Overfitting garantizado | Siempre valida con CV antes de subir el grado |
| No verificar supuestos de residuos | El modelo puede ser invalido estadisticamente | Grafica residuos vs predichos y Q-Q plot |
| Usar la misma escala para Ridge y Lasso | Los alphas optimos son muy diferentes entre si | Busca alpha por separado para cada modelo |
Seccion avanzada
HuberRegressor: robusto a outliers
from sklearn.linear_model import HuberRegressor
# HuberRegressor minimiza una funcion que es MSE para errores pequenos
# y MAE para errores grandes
huber = HuberRegressor(epsilon=1.35, alpha=0.01, max_iter=500)
huber.fit(X_tr, y_tr)
print(f"RMSE Huber: {np.sqrt(mean_squared_error(y_te, huber.predict(X_te))):.2f}")
Bayesian Ridge: con incertidumbre
from sklearn.linear_model import BayesianRidge
# Devuelve media Y desviacion estandar de la prediccion
bay_ridge = BayesianRidge()
bay_ridge.fit(X_tr, y_tr)
y_mean, y_std = bay_ridge.predict(X_te, return_std=True)
print(f"RMSE Bayesian Ridge: {np.sqrt(mean_squared_error(y_te, y_mean)):.2f}")
print(f"Incertidumbre promedio: ±{y_std.mean():.2f}")
SGDRegressor: para datasets masivos
from sklearn.linear_model import SGDRegressor
# Stochastic Gradient Descent — equivalente a LinearRegression/Ridge/Lasso
# pero escala a millones de filas
sgd = SGDRegressor(
loss="squared_error", # equivale a LinearRegression
penalty="l2", # equivale a Ridge
alpha=0.01,
learning_rate="adaptive",
eta0=0.01,
max_iter=1000,
random_state=42
)
sgd.fit(X_tr, y_tr)
print(f"RMSE SGD: {np.sqrt(mean_squared_error(y_te, sgd.predict(X_te))):.2f}")
Recursos recomendados
- Documentacion sklearn: modelos lineales: referencia completa de regresion lineal, Ridge, Lasso y ElasticNet
- ISLR capitulo 3 — Linear Regression (libro gratuito): fundamentos estadisticos de regresion
- ISLR capitulo 6 — Regularization (libro gratuito): Ridge, Lasso y seleccion de variables
- Visualizacion interactiva de regularizacion: intuicion geometrica sobre Ridge y Lasso
Navegacion
← 6. Fundamentos de Scikit-Learn | 8. Modelos de Clasificacion →