15. Embeddings y Transformers
Por que los embeddings cambiaron el NLP
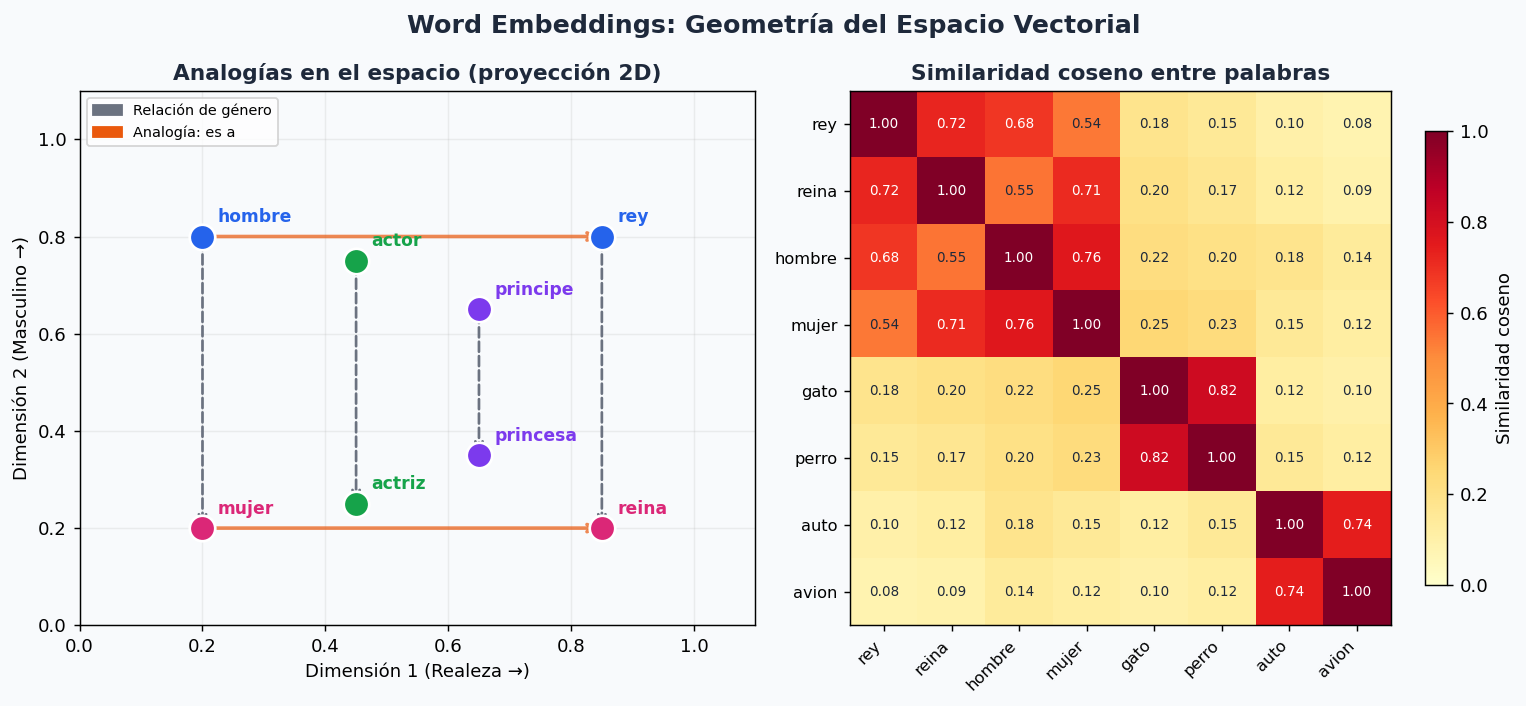
En el tema 14 cada palabra era una columna en una matriz dispersa. El problema es claro: “perro” y “can” son la misma columna 0 e infinito — no hay ninguna nocion de que esas palabras son similares.
Los embeddings resuelven esto: cada palabra se mapea a un vector denso de 50-768 numeros reales, y la geometria del espacio codifica significado. La distancia entre vectores refleja similitud semantica, y operaciones aritmeticas tienen sentido:
1. Word2Vec: aprender embeddings por prediccion
Word2Vec (Mikolov et al., 2013) aprende embeddings entrenando una red neuronal en una tarea de prediccion sobre grandes corpus de texto. La intuicion clave: las palabras que aparecen en contextos similares tienen significados similares.
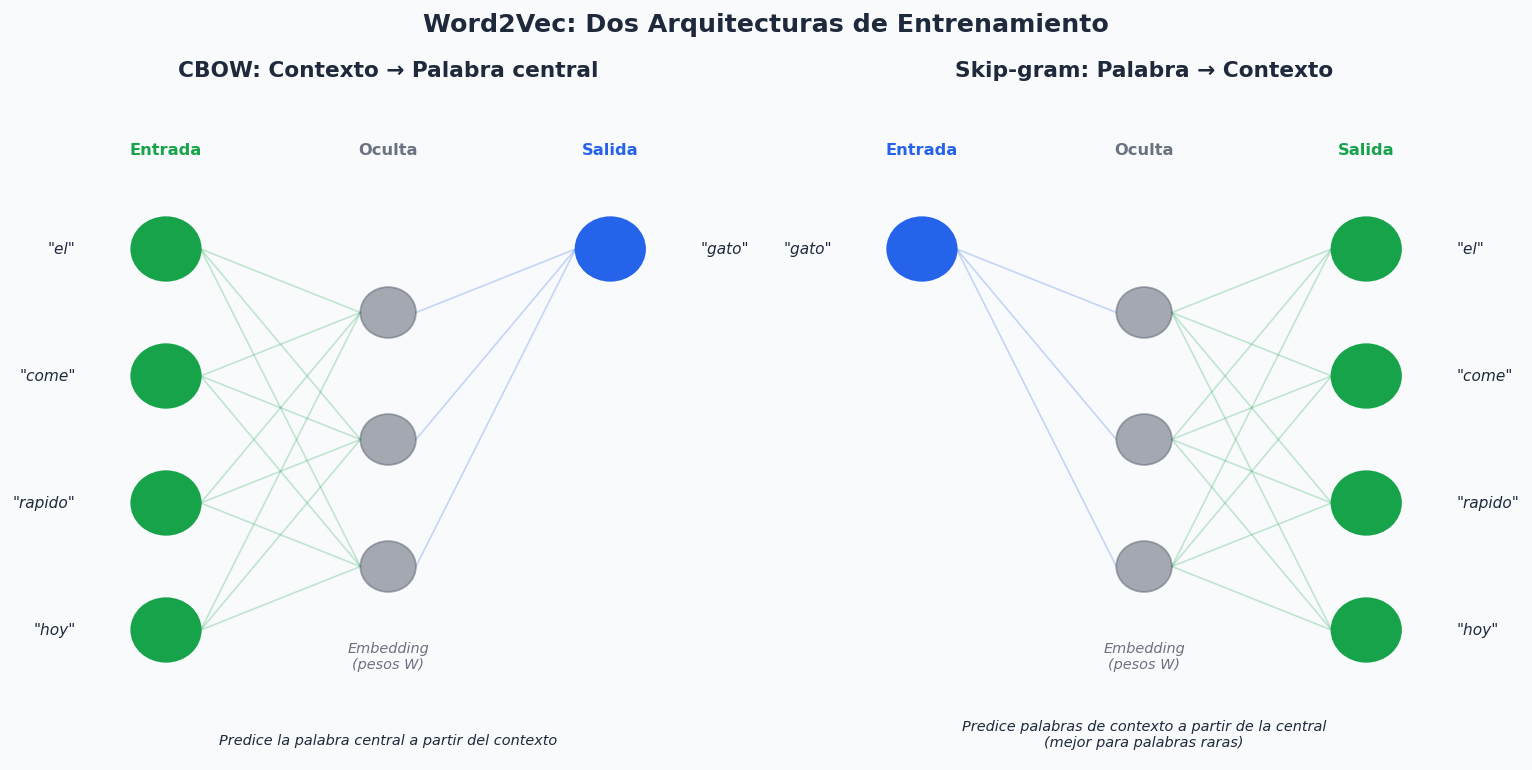
Hay dos variantes:
- CBOW (Continuous Bag of Words): predice la palabra central dado el contexto. Mas rapido, mejor para palabras frecuentes.
- Skip-gram: predice el contexto dada la palabra central. Mas lento, mejor para palabras raras.
# Opcion A: usar Gensim para entrenar Word2Vec desde cero
from gensim.models import Word2Vec
# Corpus: lista de listas de tokens
corpus = [
["el", "gato", "come", "pescado"],
["el", "perro", "come", "carne"],
["el", "gato", "y", "el", "perro", "juegan"],
# ... muchas mas oraciones
]
modelo = Word2Vec(
sentences=corpus,
vector_size=100, # dimension del embedding
window=5, # tamano de la ventana de contexto
min_count=2, # ignorar palabras con < 2 apariciones
sg=1, # 0=CBOW, 1=Skip-gram
workers=4,
epochs=10,
)
# Operaciones sobre el espacio vectorial
print(modelo.wv["gato"]) # vector de 100 dims
# Palabras mas similares
print(modelo.wv.most_similar("gato", topn=5))
# [('perro', 0.85), ('felino', 0.79), ...]
# Analogia: rey - hombre + mujer = ?
resultado = modelo.wv.most_similar(
positive=["rey", "mujer"],
negative=["hombre"],
topn=3
)
print(resultado) # [('reina', 0.82), ...]
# Guardar y cargar
modelo.save("word2vec_custom.model")
modelo_cargado = Word2Vec.load("word2vec_custom.model")
# Opcion B: usar embeddings preentrenados (lo mas comun en competencias)
import gensim.downloader as api
# Modelos disponibles: word2vec-google-news-300, glove-wiki-gigaword-100, etc.
# modelo_pretrain = api.load("word2vec-google-news-300") # 1.6 GB
# Para espanol: fasttext-wiki-news-subwords-300
# Opcion C: fastText — maneja palabras desconocidas con subwords
from gensim.models import FastText
ft_model = FastText(sentences=corpus, vector_size=100, window=5, min_count=1, epochs=10)
# fastText puede generar vectores incluso para palabras fuera del vocabulario
print(ft_model.wv["clasificacion"]) # funciona aunque no este en el corpus
print(ft_model.wv["clasificar"]) # vector similar por compartir subwords
Usar embeddings preentrenados como features en sklearn
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
def texto_a_vector(texto, modelo_wv, dim=100):
"""Promedia los vectores de las palabras del texto (doc embedding simple)."""
tokens = texto.lower().split()
vecs = [modelo_wv[w] for w in tokens if w in modelo_wv.key_to_index]
if not vecs:
return np.zeros(dim)
return np.mean(vecs, axis=0)
# Suponiendo que tenemos modelo Word2Vec entrenado
# X = np.array([texto_a_vector(t, modelo.wv) for t in textos])
# scores = cross_val_score(LogisticRegression(), X, labels, cv=5, scoring="f1_macro")
2. Similaridad coseno
La metrica estandar para comparar embeddings es la similaridad coseno (insensible a la magnitud):
import numpy as np
def similaridad_coseno(u, v):
"""Similaridad coseno entre dos vectores."""
norm = np.linalg.norm(u) * np.linalg.norm(v)
if norm == 0:
return 0.0
return float(np.dot(u, v) / norm)
# Con sklearn (mas eficiente para matrices)
from sklearn.metrics.pairwise import cosine_similarity
# Matriz de similaridad entre N vectores
vecs = np.random.randn(5, 100) # 5 palabras, 100 dims
sim_matrix = cosine_similarity(vecs) # (5, 5)
print(sim_matrix.round(3))
3. El mecanismo de atencion
El attention es el corazon de los transformers. Resuelve un problema fundamental: para entender “banco” en “fui al banco del rio”, necesitas ver “rio”; para “banco de sangre” necesitas ver “sangre”. Los embeddings estaticos (Word2Vec) no pueden hacer esto: un token siempre tiene el mismo vector, independientemente del contexto.
Self-attention produce representaciones contextuales: el vector de “banco” cambia segun que otras palabras aparecen en la oracion.
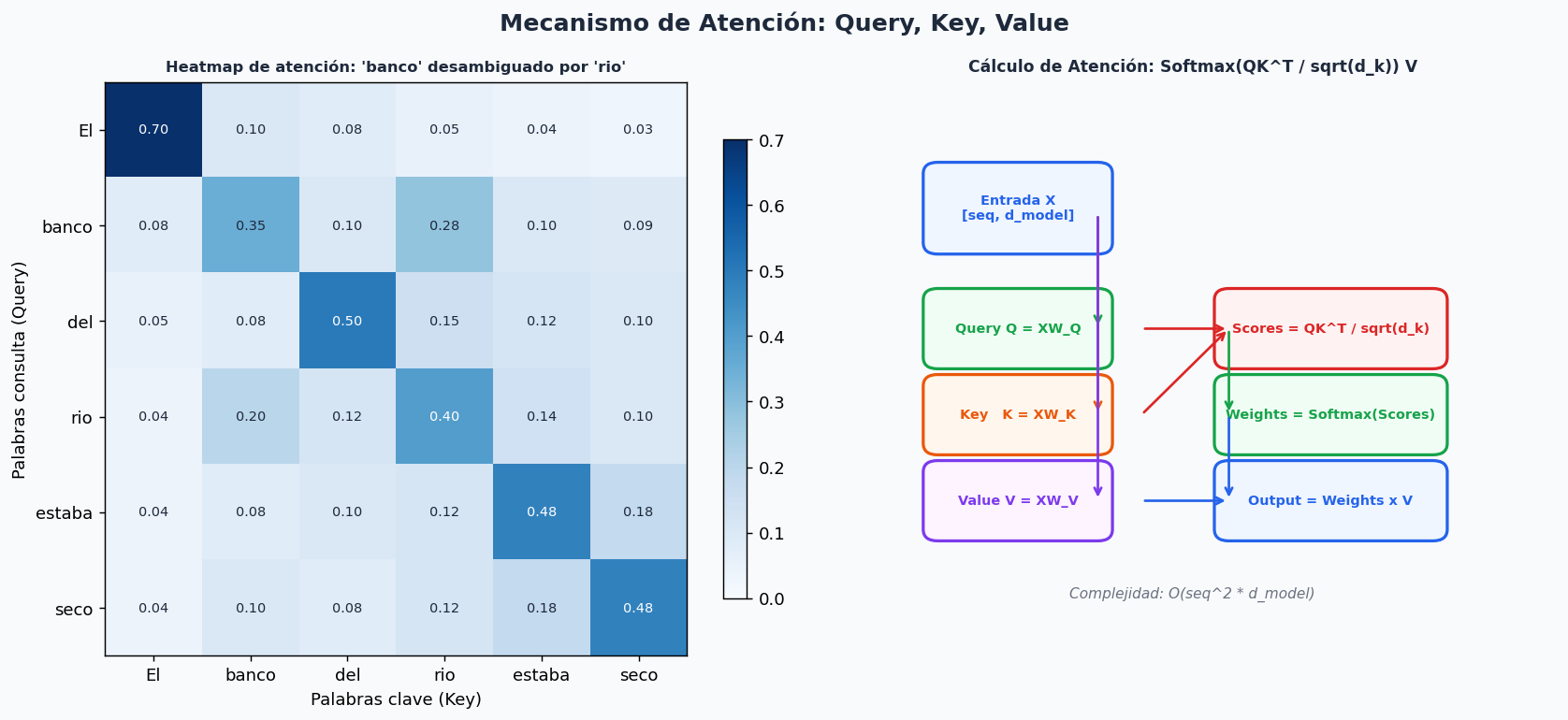
La formula de Scaled Dot-Product Attention
- Q (Query): “que estoy buscando”
- K (Key): “que informacion tengo”
- V (Value): “cual es esa informacion”
- La division por √d_k evita que los productos punto sean tan grandes que el gradiente del softmax se vuelva muy pequeno
import torch
import torch.nn.functional as F
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
Atencion Scaled Dot-Product.
Params:
Q: [batch, heads, seq, d_k]
K: [batch, heads, seq, d_k]
V: [batch, heads, seq, d_v]
mask: mascara opcional (para padding o causal)
Returns:
output: [batch, heads, seq, d_v]
weights: [batch, heads, seq, seq]
"""
d_k = Q.size(-1)
scores = torch.matmul(Q, K.transpose(-2, -1)) / (d_k ** 0.5) # [b, h, seq, seq]
if mask is not None:
scores = scores.masked_fill(mask == 0, float("-inf"))
weights = F.softmax(scores, dim=-1) # [b, h, seq, seq]
output = torch.matmul(weights, V) # [b, h, seq, d_v]
return output, weights
# Ejemplo de uso con valores aleatorios
batch, heads, seq, d_k = 2, 4, 10, 64
Q = torch.randn(batch, heads, seq, d_k)
K = torch.randn(batch, heads, seq, d_k)
V = torch.randn(batch, heads, seq, d_k)
out, weights = scaled_dot_product_attention(Q, K, V)
print(f"Output shape: {out.shape}") # [2, 4, 10, 64]
print(f"Weights shape: {weights.shape}") # [2, 4, 10, 10]
print(f"Weights sum: {weights.sum(-1)[0,0]}") # deberia ser ~ [1, 1, ..., 1]
4. Multi-Head Attention
En lugar de calcular un solo conjunto de Q, K, V, se calculan h conjuntos en paralelo (heads), cada uno con proyecciones diferentes. Cada head aprende a atender diferentes tipos de relaciones.
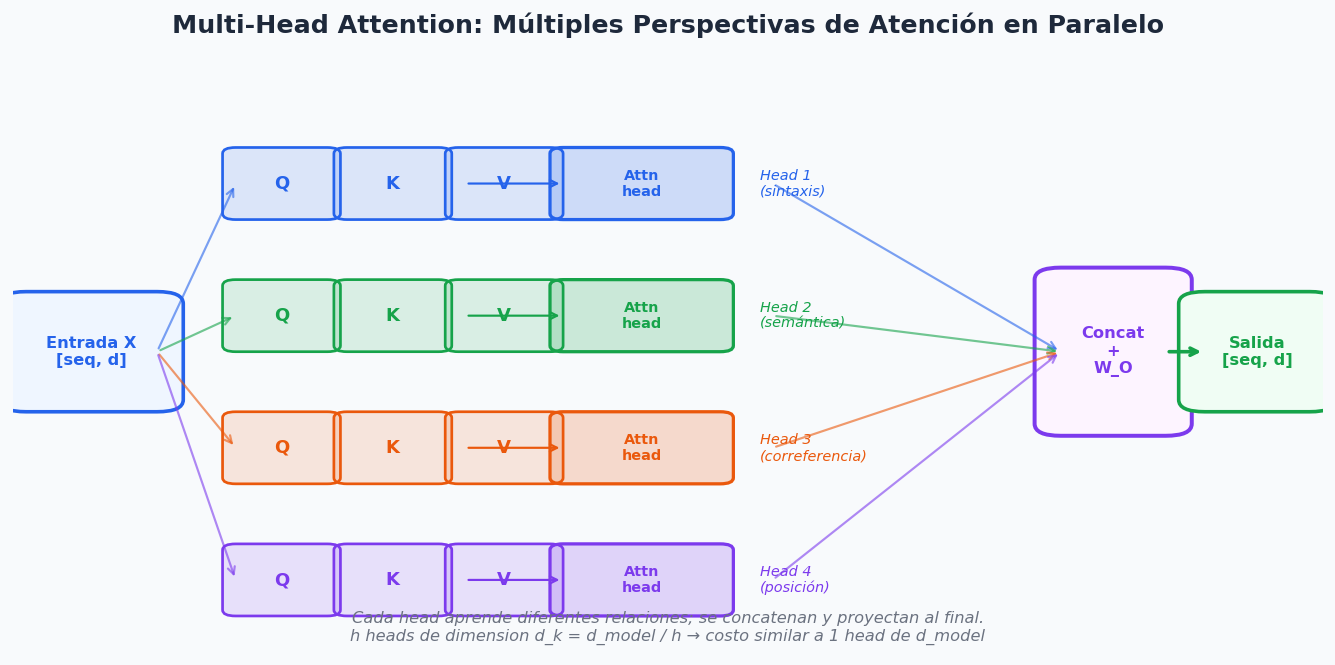
donde cada head_i = Attention(Q W_Qi, K W_Ki, V W_Vi) con matrices de proyeccion aprendidas.
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, d_model=512, n_heads=8, dropout=0.1):
super().__init__()
assert d_model % n_heads == 0
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads # dimension por head
# Proyecciones Q, K, V y salida (una matriz por head, pero se hacen juntas)
self.W_q = nn.Linear(d_model, d_model, bias=False)
self.W_k = nn.Linear(d_model, d_model, bias=False)
self.W_v = nn.Linear(d_model, d_model, bias=False)
self.W_o = nn.Linear(d_model, d_model, bias=False)
self.dropout = nn.Dropout(dropout)
def split_heads(self, x):
"""[batch, seq, d_model] → [batch, n_heads, seq, d_k]"""
B, S, _ = x.shape
return x.view(B, S, self.n_heads, self.d_k).transpose(1, 2)
def forward(self, x, mask=None):
B, S, _ = x.shape
Q = self.split_heads(self.W_q(x))
K = self.split_heads(self.W_k(x))
V = self.split_heads(self.W_v(x))
# Atencion escalada
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)
if mask is not None:
scores = scores.masked_fill(mask == 0, float("-inf"))
weights = self.dropout(torch.softmax(scores, dim=-1))
# Combinar heads
out = torch.matmul(weights, V) # [B, h, S, d_k]
out = out.transpose(1, 2).contiguous().view(B, S, -1) # [B, S, d_model]
return self.W_o(out), weights
# Verificacion
mha = MultiHeadAttention(d_model=512, n_heads=8)
x = torch.randn(2, 10, 512) # batch=2, seq=10, d_model=512
out, w = mha(x)
print(f"MHA output: {out.shape}") # [2, 10, 512]
print(f"Attn weights: {w.shape}") # [2, 8, 10, 10]
5. Arquitectura del Transformer
El Transformer combina Multi-Head Self-Attention con Feed-Forward Networks, normalizacion y conexiones residuales. BERT usa solo la parte Encoder.
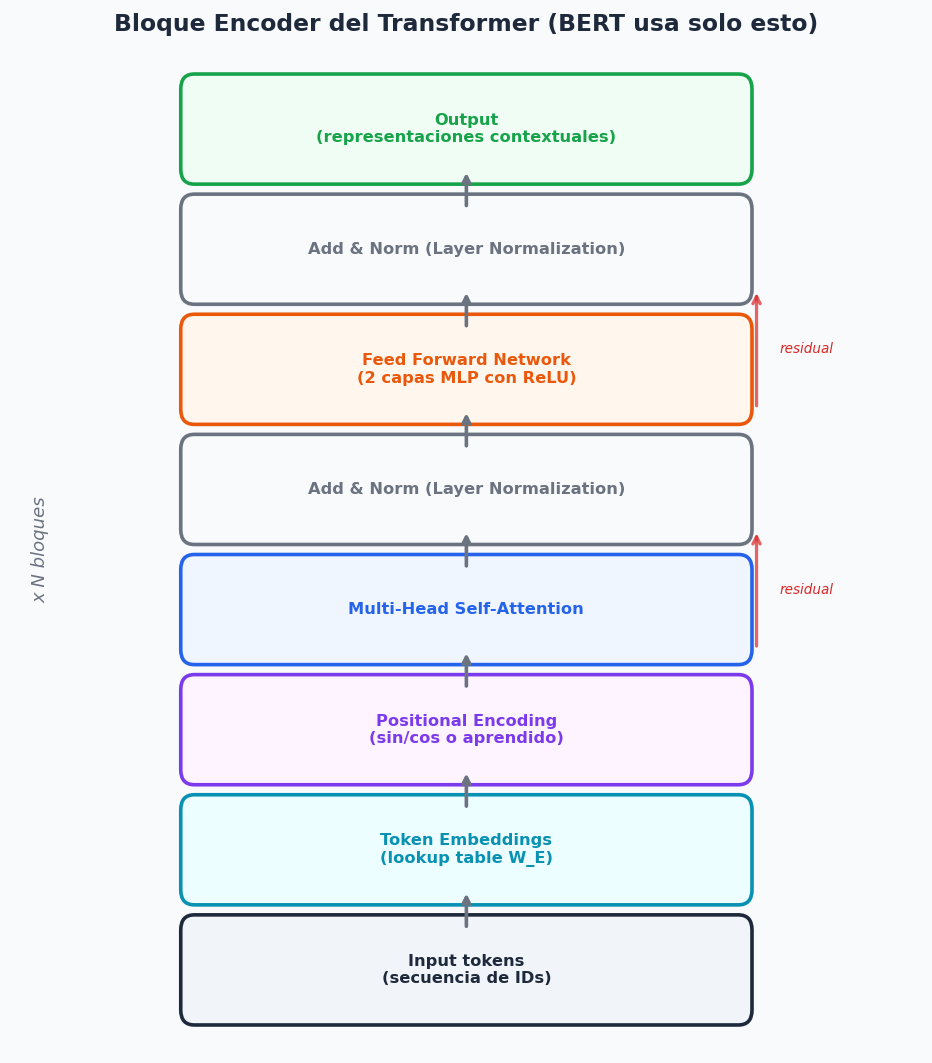
Positional Encoding
Los transformers no tienen recurrencia ni convolucion, asi que hay que codificar el orden de los tokens explicitamente:
import torch
import torch.nn as nn
import math
class PositionalEncoding(nn.Module):
"""
Codificacion posicional sinusoidal del paper original.
PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
"""
def __init__(self, d_model=512, max_len=5000, dropout=0.1):
super().__init__()
self.dropout = nn.Dropout(dropout)
pe = torch.zeros(max_len, d_model)
pos = torch.arange(0, max_len).unsqueeze(1).float()
div = torch.exp(torch.arange(0, d_model, 2).float()
* (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(pos * div)
pe[:, 1::2] = torch.cos(pos * div)
self.register_buffer("pe", pe.unsqueeze(0)) # [1, max_len, d_model]
def forward(self, x):
"""x: [batch, seq, d_model]"""
return self.dropout(x + self.pe[:, :x.size(1)])
class TransformerEncoderBlock(nn.Module):
"""Un bloque del encoder: MHA + AddNorm + FFN + AddNorm"""
def __init__(self, d_model=512, n_heads=8, d_ff=2048, dropout=0.1):
super().__init__()
self.attn = MultiHeadAttention(d_model, n_heads, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.ff = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(d_ff, d_model),
)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
# Pre-norm (variante moderna, mas estable que post-norm)
attn_out, _ = self.attn(self.norm1(x), mask)
x = x + self.dropout(attn_out) # conexion residual
x = x + self.dropout(self.ff(self.norm2(x)))
return x
6. BERT vs GPT: encoder vs decoder
Dos familias principales de modelos, con casos de uso muy distintos.
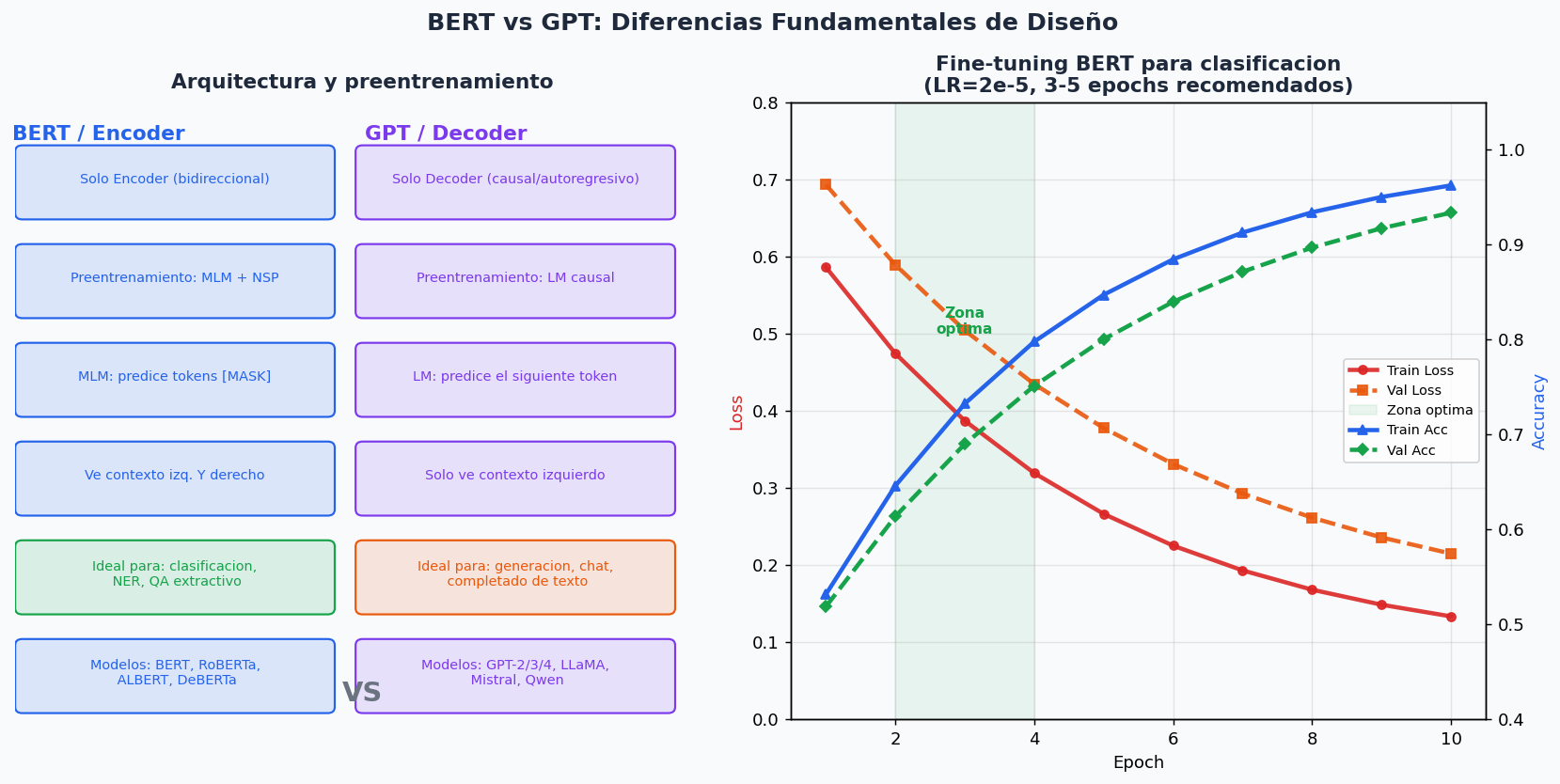
| BERT (Encoder) | GPT (Decoder) | |
|---|---|---|
| Visibilidad de contexto | Bidireccional (izq + der) | Causal (solo izquierda) |
| Preentrenamiento | Masked LM + NSP | Language Modeling |
| Ideal para | Clasificacion, NER, QA | Generacion, chatbots |
| Fine-tuning | Anadir capa de clasificacion | Prompt engineering o SFT |
| Modelo tipico | bert-base-multilingual | gpt2, llama-3 |
7. Tokenizacion subword (WordPiece / BPE)
Los transformers usan tokenizacion subword en lugar de words completas. Esto elimina el problema OOV (Out-of-Vocabulary) al dividir palabras desconocidas en subunidades conocidas.
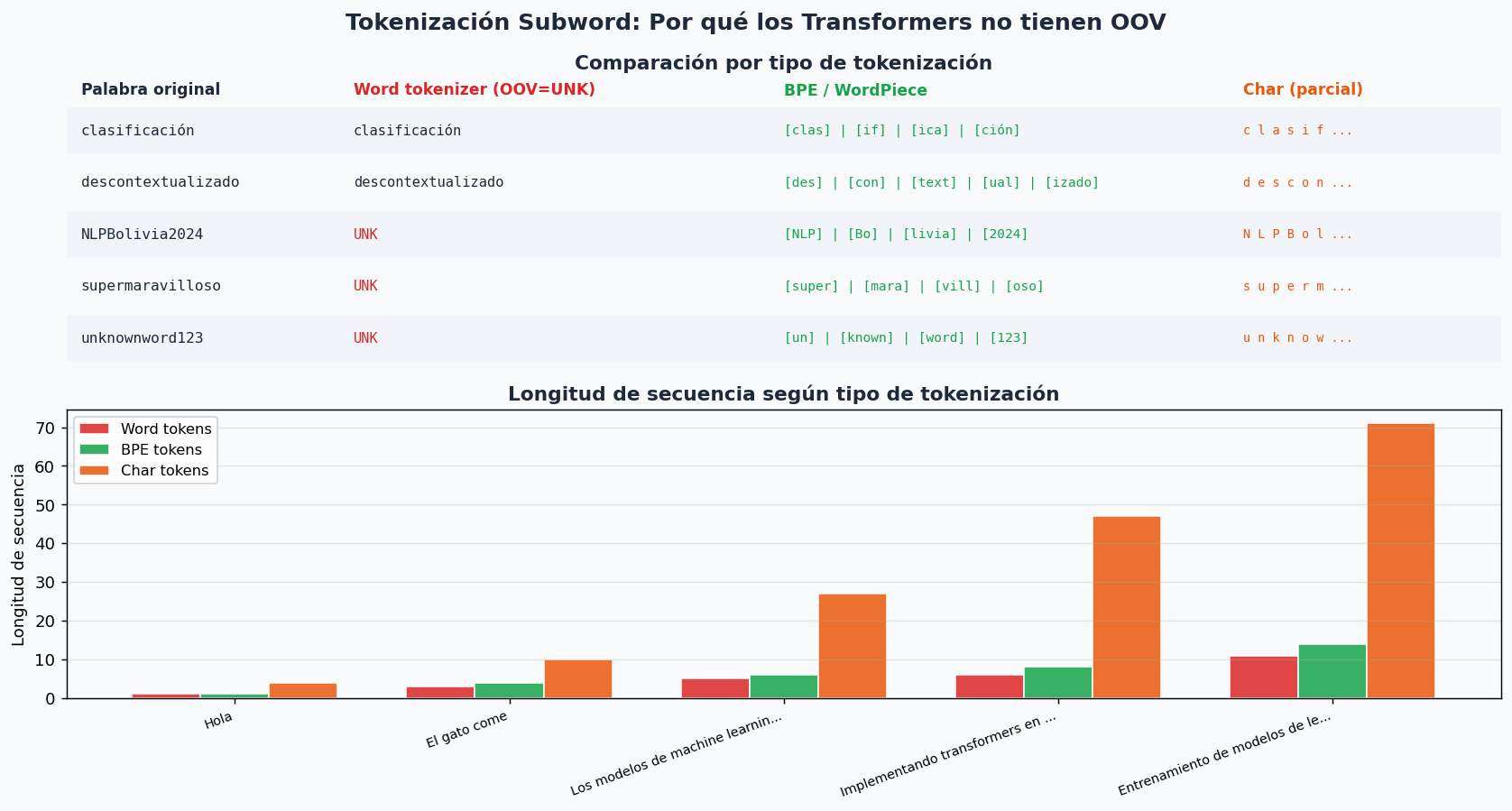
from transformers import AutoTokenizer
# Cargar tokenizador de BERT multilingue
tokenizer = AutoTokenizer.from_pretrained("bert-base-multilingual-cased")
# Tokenizar texto en espanol
texto = "Los clasificadores de aprendizaje automatico son increibles"
tokens = tokenizer.tokenize(texto)
print(tokens)
# ['Los', 'clas', '##ific', '##adores', 'de', 'apren', '##dizaje',
# 'automatic', '##o', 'son', 'incre', '##ible', '##s']
# "##" indica que el token es una continuacion (subword)
# Codificacion completa (con [CLS], [SEP] y padding)
encoding = tokenizer(
texto,
max_length=128,
padding="max_length",
truncation=True,
return_tensors="pt",
)
print(encoding.keys())
# dict_keys(['input_ids', 'token_type_ids', 'attention_mask'])
print(encoding["input_ids"].shape) # [1, 128]
print(encoding["attention_mask"].shape)# [1, 128] — 1=token real, 0=padding
# Decodificar de vuelta
ids = encoding["input_ids"][0]
print(tokenizer.decode(ids, skip_special_tokens=True))
# Batch de textos (lo que usaras en la practica)
batch_textos = [
"Excelente producto, lo recomiendo",
"Muy malo, no funciona",
"Normal, cumple su funcion",
]
batch_enc = tokenizer(
batch_textos,
max_length=64,
padding=True, # pad al maximo del batch
truncation=True,
return_tensors="pt",
)
print(batch_enc["input_ids"].shape) # [3, max_len_del_batch]
8. Fine-tuning de BERT con Hugging Face
El flujo estandar en competencias: cargar modelo preentrenado → agregar capa de tarea → fine-tuning.
import torch
from torch.utils.data import Dataset, DataLoader
from transformers import (
AutoTokenizer, AutoModelForSequenceClassification,
get_linear_schedule_with_warmup,
)
from torch.optim import AdamW
# ── Dataset ──────────────────────────────────────────────────────────────────
class TextDataset(Dataset):
def __init__(self, textos, labels, tokenizer, max_len=128):
self.enc = tokenizer(
textos,
max_length=max_len,
padding="max_length",
truncation=True,
return_tensors="pt",
)
self.labels = torch.tensor(labels, dtype=torch.long)
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
return {
"input_ids": self.enc["input_ids"][idx],
"attention_mask": self.enc["attention_mask"][idx],
"labels": self.labels[idx],
}
# ── Configuracion ────────────────────────────────────────────────────────────
MODEL_NAME = "bert-base-multilingual-cased"
N_CLASSES = 3
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
LR = 2e-5
N_EPOCHS = 4
BATCH_SIZE = 32
WARMUP_FRAC = 0.06 # 6% de pasos con warmup
# ── Datos de ejemplo ─────────────────────────────────────────────────────────
train_texts = ["excelente producto", "muy malo", "normal", "increible calidad",
"pesimo servicio", "entrega rapida"]
train_labels = [1, 0, 2, 1, 0, 2]
val_texts = ["bueno", "terrible", "aceptable"]
val_labels = [1, 0, 2]
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
train_ds = TextDataset(train_texts, train_labels, tokenizer)
val_ds = TextDataset(val_texts, val_labels, tokenizer)
train_dl = DataLoader(train_ds, batch_size=BATCH_SIZE, shuffle=True)
val_dl = DataLoader(val_ds, batch_size=BATCH_SIZE)
# ── Modelo ───────────────────────────────────────────────────────────────────
model = AutoModelForSequenceClassification.from_pretrained(
MODEL_NAME,
num_labels=N_CLASSES,
ignore_mismatched_sizes=True,
).to(DEVICE)
# ── Optimizador con weight decay diferencial ─────────────────────────────────
# Las capas de bias y LayerNorm NO deben tener weight decay
no_decay = ["bias", "LayerNorm.weight"]
optimizer_groups = [
{"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": 0.01},
{"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0},
]
optimizer = AdamW(optimizer_groups, lr=LR)
total_steps = len(train_dl) * N_EPOCHS
warmup_steps = int(total_steps * WARMUP_FRAC)
scheduler = get_linear_schedule_with_warmup(
optimizer, num_warmup_steps=warmup_steps,
num_training_steps=total_steps
)
# ── Loop de entrenamiento ─────────────────────────────────────────────────────
def train_epoch(model, loader, optimizer, scheduler):
model.train()
total_loss, correct, total = 0, 0, 0
for batch in loader:
batch = {k: v.to(DEVICE) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
preds = outputs.logits.argmax(-1)
correct += (preds == batch["labels"]).sum().item()
total += len(batch["labels"])
total_loss += loss.item() * len(batch["labels"])
return total_loss/total, correct/total
@torch.no_grad()
def evaluate(model, loader):
model.eval()
correct, total, total_loss = 0, 0, 0
for batch in loader:
batch = {k: v.to(DEVICE) for k, v in batch.items()}
outputs = model(**batch)
preds = outputs.logits.argmax(-1)
correct += (preds == batch["labels"]).sum().item()
total += len(batch["labels"])
total_loss += outputs.loss.item() * len(batch["labels"])
return total_loss/total, correct/total
best_val_acc = 0
for ep in range(N_EPOCHS):
tr_loss, tr_acc = train_epoch(model, train_dl, optimizer, scheduler)
vl_loss, vl_acc = evaluate(model, val_dl)
if vl_acc > best_val_acc:
best_val_acc = vl_acc
model.save_pretrained("bert_clasificador_best")
tokenizer.save_pretrained("bert_clasificador_best")
print(f"Ep {ep+1}/{N_EPOCHS} | tr={tr_acc:.3f} vl={vl_acc:.3f} | "
f"lr={scheduler.get_last_lr()[0]:.2e}")
print(f"\nMejor val accuracy: {best_val_acc:.4f}")
Inferencia con el modelo guardado
from transformers import pipeline
# Carga el modelo guardado como pipeline de clasificacion
clf = pipeline(
"text-classification",
model="bert_clasificador_best",
device=0 if torch.cuda.is_available() else -1,
)
resultados = clf([
"Este producto es increible, lo recomiendo totalmente",
"Terrible experiencia, nunca volvere",
"El producto llego bien embalado",
])
for r in resultados:
print(r)
# {'label': 'LABEL_1', 'score': 0.934} → positivo
9. Modelos multilingues y seleccion de modelo
Para textos en espanol o en multiples idiomas, hay modelos especializados.
# Modelos recomendados para NLP en espanol / multilingue
modelos_recomendados = {
# Clasificacion / NER en espanol
"dccuchile/bert-base-spanish-wwm-cased": "BETO — BERT entrenado en espanol",
"PlanTL-GOB-ES/roberta-base-bne": "RoBERTa espanol BNE",
# Multilingue (cuando el dataset mezcla idiomas)
"bert-base-multilingual-cased": "mBERT — 104 idiomas",
"xlm-roberta-base": "XLM-RoBERTa base — 100 idiomas",
"xlm-roberta-large": "XLM-RoBERTa large — mejor F1",
# Embeddings de oraciones (busqueda semantica, similaridad)
"sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2": "Sentence embeddings 50 idiomas",
"BAAI/bge-m3": "Embeddings multilingues SOTA",
}
# Sentence Transformers: embeddings de oraciones en 2 lineas
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
st_model = SentenceTransformer("sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2")
oraciones = [
"El gato come pescado",
"El felino consume mariscos",
"El perro ladra fuerte",
"La computadora es rapida",
]
embeddings = st_model.encode(oraciones) # (4, 384)
sim_mat = cosine_similarity(embeddings)
print("Oraciones semanticamente similares:")
for i in range(len(oraciones)):
for j in range(i+1, len(oraciones)):
if sim_mat[i, j] > 0.55:
print(f" '{oraciones[i]}' ~ '{oraciones[j]}': {sim_mat[i,j]:.3f}")
Dashboard resumen
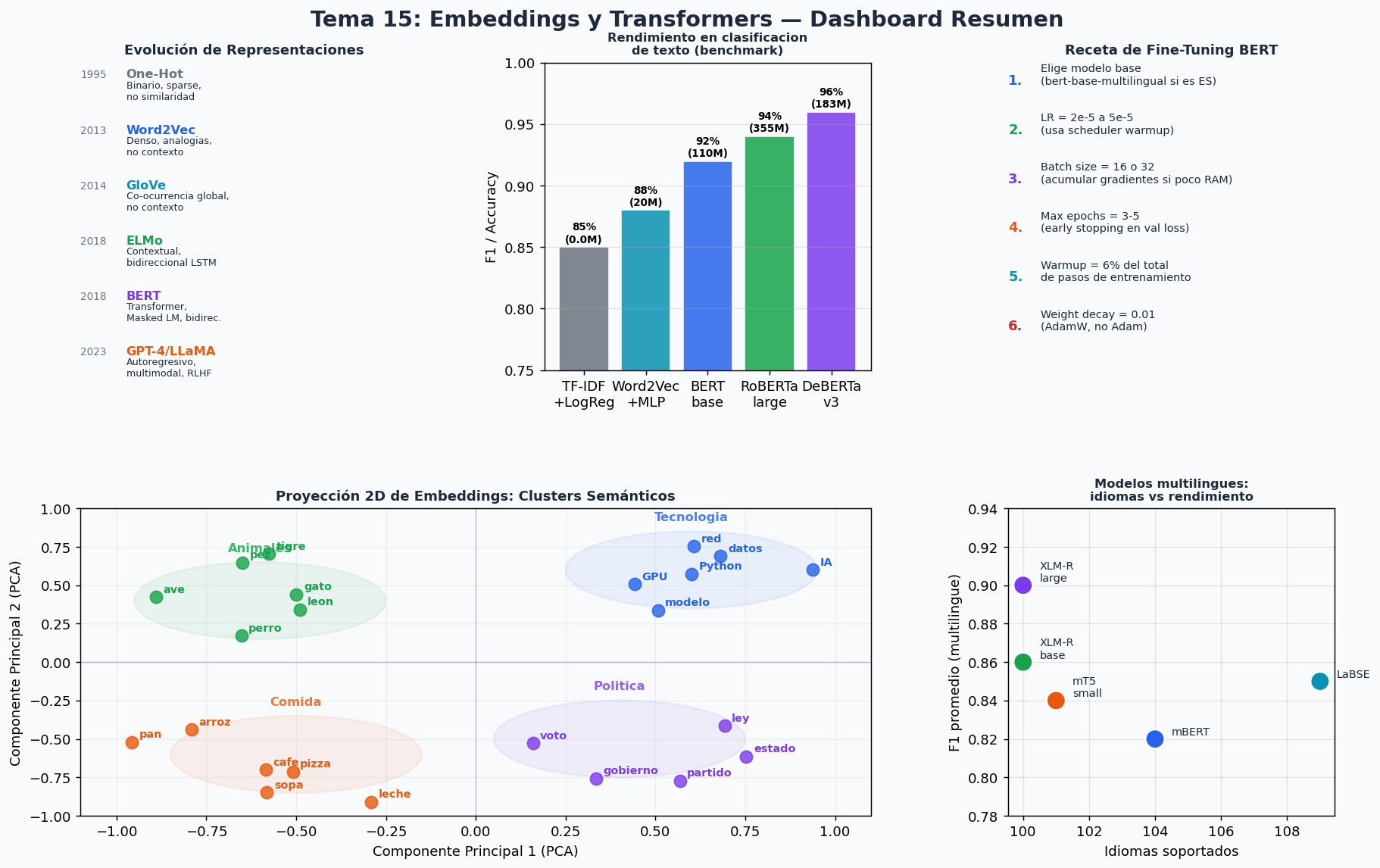
Recursos recomendados
- The Illustrated Transformer (Jay Alammar): la explicacion visual mas clara del mecanismo de atencion y la arquitectura completa
- Curso oficial de Hugging Face: desde tokenizacion hasta fine-tuning de BERT y GPT con codigo
- Documentacion de
transformers: referencia completa de la libreria con ejemplos y APIs - Word2Vec (Mikolov et al., 2013): el paper original que inicio la era de embeddings de palabras
- BERT (Devlin et al., 2018): pre-entrenamiento bidireccional de transformers, fundamento de modelos modernos
Navegacion
← 14. Fundamentos de NLP | 16. Flujo de Trabajo en Kaggle y Competencias →