14. Fundamentos de NLP
Por que el texto es diferente a otros datos
Con imagenes o datos tabulares, el pipeline de ML es relativamente directo: los numeros ya estan ahi. El texto no: antes de aplicar cualquier modelo, hay que convertir cadenas de caracteres en numeros de una forma que preserve informacion linguistica relevante.
El NLP moderno se divide en dos eras:
- Era clasica (hasta ~2018): preprocesamiento manual + representaciones dispersas (BoW, TF-IDF) + modelos de ML clasicos
- Era de transformers (2018–presente): tokenizacion subword + embeddings densos + modelos preentrenados masivos
Este tema cubre la era clasica, que sigue siendo sorprendentemente competitiva en datasets pequenos y es la base conceptual para entender los transformers del tema 15.
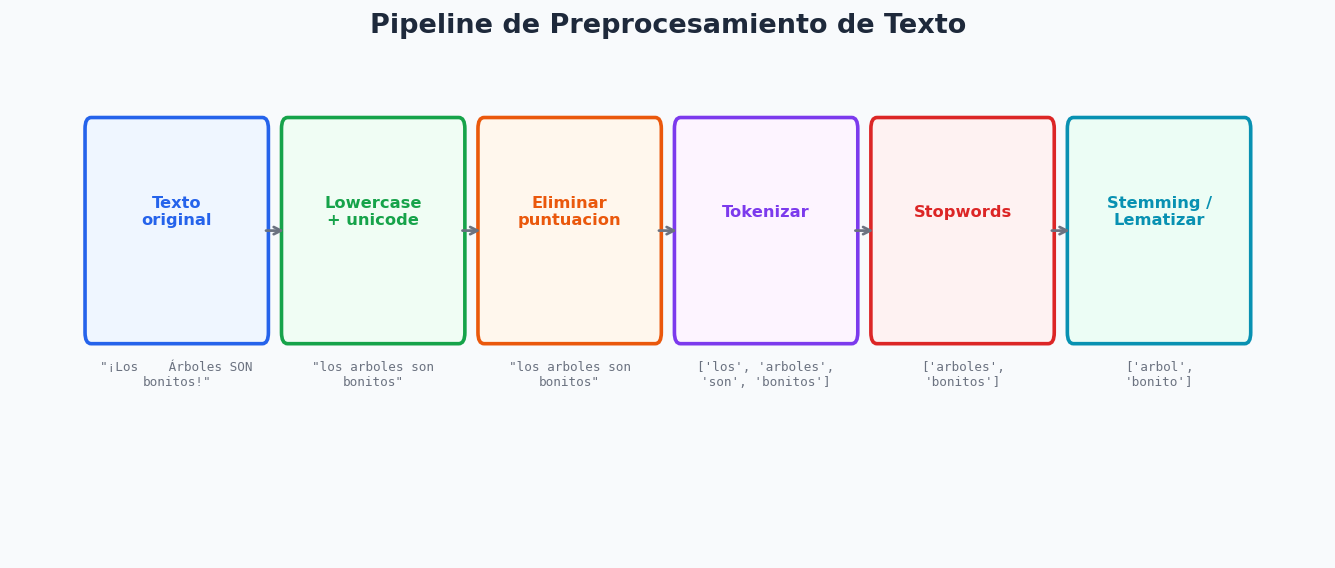
1. Pipeline de preprocesamiento
Cada decision en el pipeline de limpieza afecta el rendimiento final. La regla es: limpiar lo suficiente para reducir ruido, sin destruir informacion.
import re
import unicodedata
def limpiar_texto(texto: str,
lowercase=True,
remove_accents=False,
remove_punctuation=True,
remove_numbers=False) -> str:
"""
Pipeline de limpieza de texto configurable.
Parametros
----------
lowercase : bool
Convertir todo a minusculas.
remove_accents : bool
Normalizar caracteres unicode (eliminar tildes).
CUIDADO: puede cambiar el significado en espanol.
remove_punctuation : bool
Eliminar signos de puntuacion.
remove_numbers : bool
Eliminar digitos numericos.
"""
# 1. Eliminar HTML/XML
texto = re.sub(r"<[^>]+>", " ", texto)
# 2. URLs
texto = re.sub(r"https?://\S+|www\.\S+", " URL ", texto)
# 3. Emails
texto = re.sub(r"\S+@\S+", " EMAIL ", texto)
# 4. Lowercase
if lowercase:
texto = texto.lower()
# 5. Normalizar unicode (quitar tildes)
if remove_accents:
texto = unicodedata.normalize("NFD", texto)
texto = "".join(c for c in texto if unicodedata.category(c) != "Mn")
# 6. Numeros
if remove_numbers:
texto = re.sub(r"\d+", " ", texto)
# 7. Puntuacion (conserva apostrofos en algunas variantes)
if remove_punctuation:
texto = re.sub(r"[^\w\s]", " ", texto)
# 8. Espacios multiples
texto = re.sub(r"\s+", " ", texto).strip()
return texto
# Ejemplos
print(limpiar_texto("¡Los ÁRBOLES son hermosos! Visita www.example.com"))
# los arboles son hermosos url
print(limpiar_texto("El modelo (v2.3) tiene 95.4% de accuracy.", remove_accents=True))
# el modelo v2 3 tiene 95 4 de accuracy
2. Tokenizacion
La tokenizacion divide el texto en unidades (tokens). La eleccion del tokenizador afecta profundamente la representacion.
# ── Tokenizacion con NLTK ─────────────────────────────────────────────────────
import nltk
nltk.download("punkt", quiet=True)
nltk.download("punkt_tab", quiet=True)
from nltk.tokenize import word_tokenize, sent_tokenize, TweetTokenizer
texto = "El modelo de ML superó el 95% en F1-score. ¡Increíble resultado!"
# Por palabras (maneja puntuacion como tokens separados)
tokens_word = word_tokenize(texto, language="spanish")
print(tokens_word)
# ['El', 'modelo', 'de', 'ML', 'superó', 'el', '95', '%', 'en', 'F1-score', '.', '¡', 'Increíble', 'resultado', '!']
# Por oraciones
oraciones = sent_tokenize(texto, language="spanish")
print(oraciones)
# ['El modelo de ML superó el 95% en F1-score.', '¡Increíble resultado!']
# TweetTokenizer: maneja emojis, hashtags, menciones
tweet = "Me encanta #IA 🤖 @usuario_x mejor que nunca!!"
tweet_tok = TweetTokenizer()
print(tweet_tok.tokenize(tweet))
# ['Me', 'encanta', '#IA', '🤖', '@usuario_x', 'mejor', 'que', 'nunca', '!', '!']
# ── Tokenizacion con spaCy (mas completa) ────────────────────────────────────
import spacy
# pip install spacy && python -m spacy download es_core_news_sm
try:
nlp = spacy.load("es_core_news_sm")
doc = nlp("El gato comió el pescado rápidamente.")
for token in doc:
print(f"{token.text:<15} lemma={token.lemma_:<12} pos={token.pos_:<6} stop={token.is_stop}")
# El lemma=el pos=DET stop=True
# gato lemma=gato pos=NOUN stop=False
# comió lemma=comer pos=VERB stop=False
# ...
except OSError:
print("Modelo spaCy no instalado. Ejecutar: python -m spacy download es_core_news_sm")
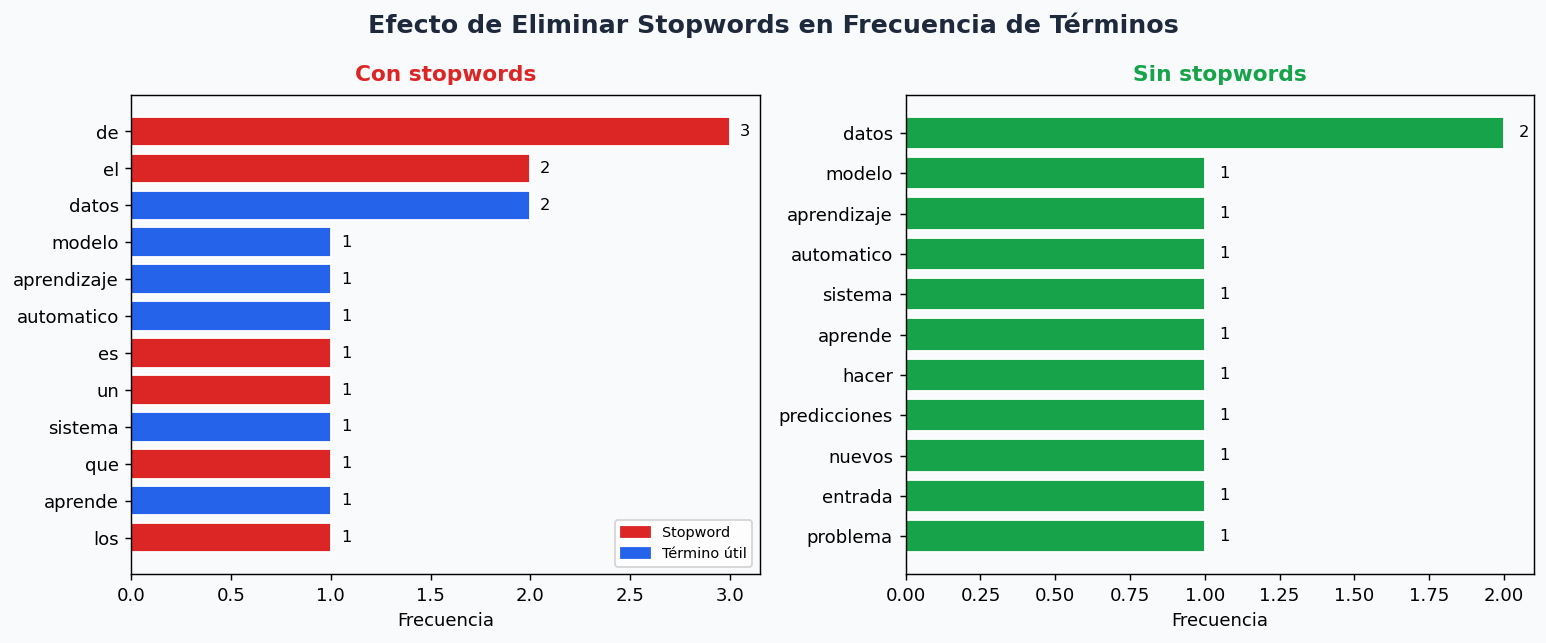
3. Stopwords y su impacto
Las stopwords son palabras tan comunes que aportan poco valor discriminativo (artículos, preposiciones, conjunciones). Eliminarlas reduce dimensionalidad y mejora la señal.
import nltk
from nltk.corpus import stopwords
from collections import Counter
nltk.download("stopwords", quiet=True)
# Stopwords en varios idiomas
stop_es = set(stopwords.words("spanish"))
stop_en = set(stopwords.words("english"))
print(f"Stopwords en espanol: {len(stop_es)} palabras")
print(sorted(list(stop_es))[:10]) # ['a', 'al', 'algo', 'algunas', ...]
# Funcion de limpieza con stopwords
def quitar_stopwords(tokens: list, idioma="spanish") -> list:
stops = set(stopwords.words(idioma))
return [t for t in tokens if t.lower() not in stops and len(t) > 1]
texto = "el modelo de aprendizaje automatico es un sistema que aprende de los datos"
tokens = texto.split()
tokens_limpios = quitar_stopwords(tokens)
print(f"Antes: {len(tokens)} tokens → Después: {len(tokens_limpios)} tokens")
print(tokens_limpios)
# ['modelo', 'aprendizaje', 'automatico', 'sistema', 'aprende', 'datos']
# Stopwords personalizadas: agrega las especificas de tu dominio
stop_custom = stop_es | {"url", "email", "nombre", "fecha"}
def tokenizar_y_limpiar(texto: str, idioma="spanish") -> list:
"""Pipeline completo: limpiar → tokenizar → quitar stopwords."""
texto_limpio = limpiar_texto(texto)
tokens = word_tokenize(texto_limpio, language=idioma)
return quitar_stopwords(tokens, idioma)
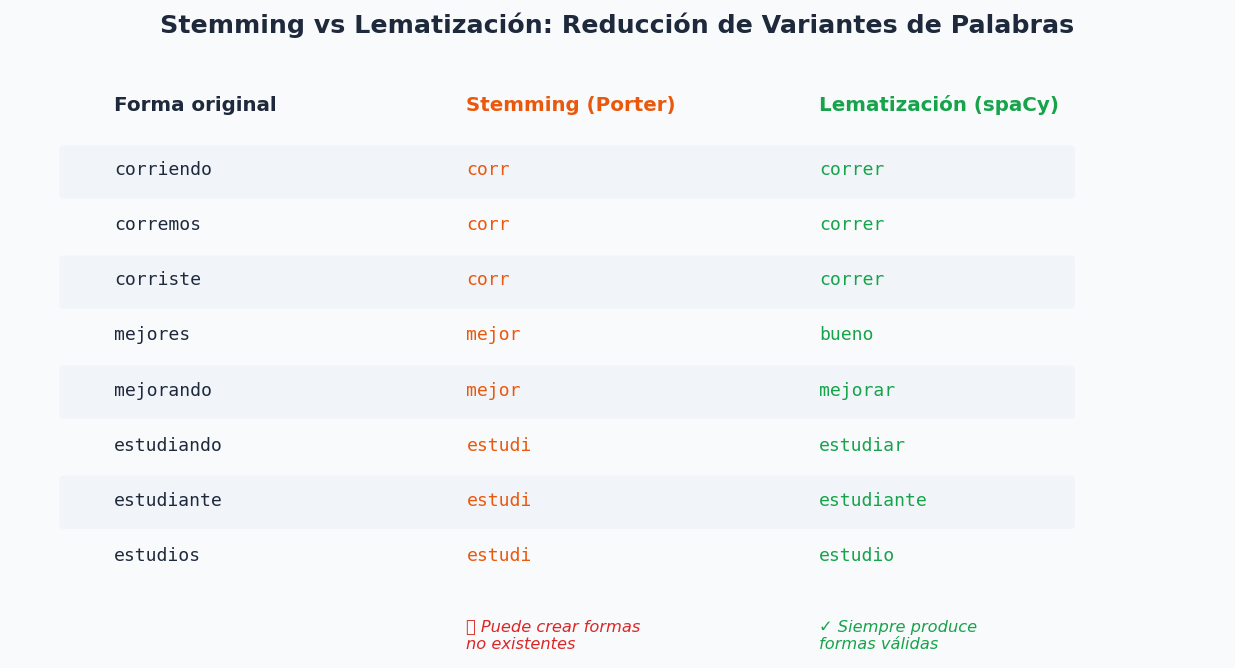
4. Stemming y Lematizacion
Ambas tecnicas reducen variantes morfologicas a una forma base, disminuyendo el vocabulario y mejorando la generalizacion.
import nltk
from nltk.stem import SnowballStemmer
nltk.download("wordnet", quiet=True)
# ── Stemming con SnowballStemmer ─────────────────────────────────────────────
stemmer = SnowballStemmer("spanish")
palabras = ["corriendo", "corremos", "corriste", "mejores",
"mejorando", "estudiando", "estudiante", "estudios"]
print("Stemming (SnowballStemmer):")
for p in palabras:
print(f" {p:<15} → {stemmer.stem(p)}")
# corriendo → corr
# mejores → mejor
# estudiando → estudi ← puede no ser una palabra real
# Problema del stemming: puede crear formas inexistentes
print(stemmer.stem("computadora")) # "comput" — no es una palabra valida
# ── Lematizacion con spaCy ───────────────────────────────────────────────────
try:
import spacy
nlp = spacy.load("es_core_news_sm")
def lematizar(texto: str) -> list:
doc = nlp(texto.lower())
return [token.lemma_ for token in doc
if not token.is_stop and not token.is_punct and len(token.text) > 1]
texto = "Los estudiantes estuvieron estudiando modelos de aprendizaje automatico"
print("\nLematizacion (spaCy):")
print(lematizar(texto))
# ['estudiante', 'estudiar', 'modelo', 'aprendizaje', 'automatico']
# — siempre formas validas del diccionario
except OSError:
print("spaCy: modelo ES no disponible")
# ── Comparacion practica ──────────────────────────────────────────────────────
def pipeline_stem(texto, idioma="spanish"):
tokens = tokenizar_y_limpiar(texto, idioma)
return [stemmer.stem(t) for t in tokens]
print("\nStemming pipeline:", pipeline_stem("Los modelos aprenden de los datos"))
# ['model', 'aprend', 'dat']
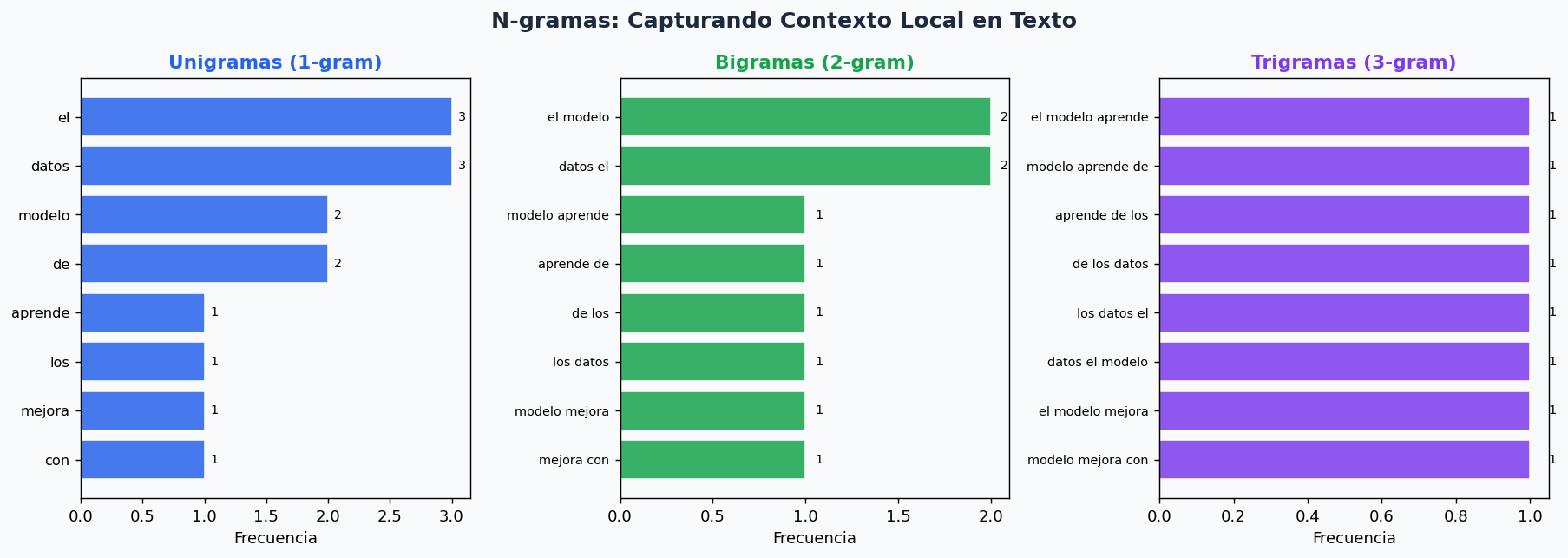
5. N-gramas: capturando contexto local
Un n-grama es una secuencia contigua de n tokens. Los bigramas y trigramas capturan contexto que los unigramas pierden.
from nltk.util import ngrams
from collections import Counter
texto = "el modelo de machine learning aprende de los datos de entrenamiento"
tokens = texto.split()
# Unigramas, bigramas, trigramas
unigramas = list(ngrams(tokens, 1))
bigramas = list(ngrams(tokens, 2))
trigramas = list(ngrams(tokens, 3))
print("Bigramas mas frecuentes:")
for bg, freq in Counter(bigramas).most_common(5):
print(f" {' '.join(bg)}: {freq}")
# Incorporar n-gramas en TF-IDF de sklearn
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
"el modelo de machine learning es bueno",
"los datos de machine learning son importantes",
"machine learning requiere muchos datos buenos",
]
# ngram_range=(1,2) incluye unigramas Y bigramas
vectorizer = TfidfVectorizer(ngram_range=(1, 2), max_features=20)
X = vectorizer.fit_transform(corpus)
print("\nFeatures con bigramas:")
print(vectorizer.get_feature_names_out()[:10])
# ['buenos', 'bueno', 'datos', 'datos de', 'de machine', 'el modelo',
# 'learning', 'learning es', 'machine', 'machine learning']
print(f"\nShape del vocabulario: {X.shape}") # (3, 20)
6. Bag of Words y TF-IDF
Estas son las dos representaciones vectoriales clasicas mas usadas en NLP competitivo.
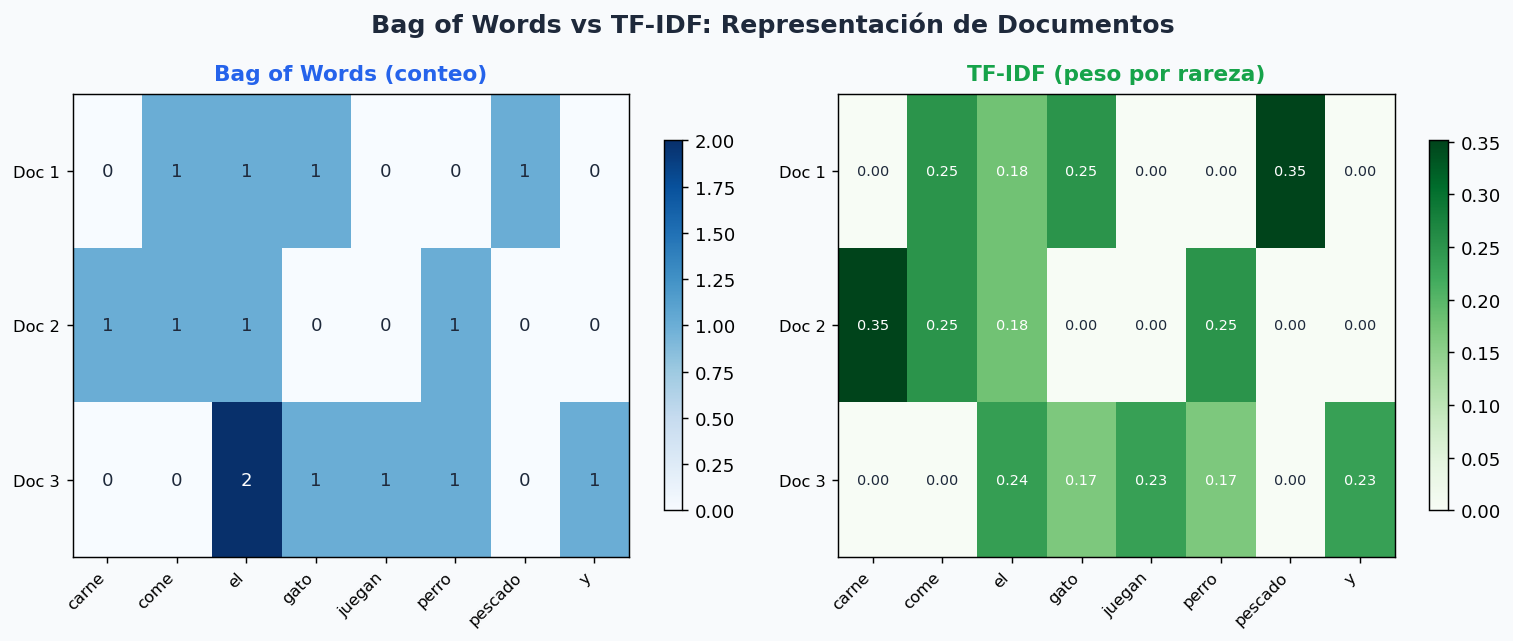
Bag of Words
Cuenta cuantas veces aparece cada palabra del vocabulario en cada documento. Resultado: vector disperso de enteros.
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
"el gato come pescado fresco",
"el perro come carne fresca",
"el gato y el perro juegan juntos",
]
# CountVectorizer = Bag of Words
bow_vec = CountVectorizer()
X_bow = bow_vec.fit_transform(corpus)
print("Vocabulario:", bow_vec.vocabulary_)
print("Matriz BoW (densa):")
print(X_bow.toarray())
# Cada fila = 1 documento, cada columna = 1 palabra del vocabulario
# [[0 1 0 0 1 1 0 0 1 0] ← doc 1: 'come'=1, 'gato'=1, ...
# [1 1 0 0 1 0 0 1 0 0] ← doc 2
# [0 0 1 1 0 1 1 1 0 1]] ← doc 3
TF-IDF: penalizar palabras comunes
TF (Term Frequency): frecuencia normalizada del termino en el documento.
IDF (Inverse Document Frequency): penaliza palabras que aparecen en muchos documentos.
TF-IDF = TF × IDF
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vec = TfidfVectorizer(
max_features=5000, # limitar vocabulario a las N palabras mas frecuentes
ngram_range=(1, 2), # unigramas y bigramas
min_df=2, # ignorar terminos que aparecen en < 2 documentos
max_df=0.95, # ignorar terminos en > 95% de documentos (stopwords de facto)
sublinear_tf=True, # usar log(1+tf) para suavizar conteos altos
norm="l2", # normalizar vectores a norma unitaria
)
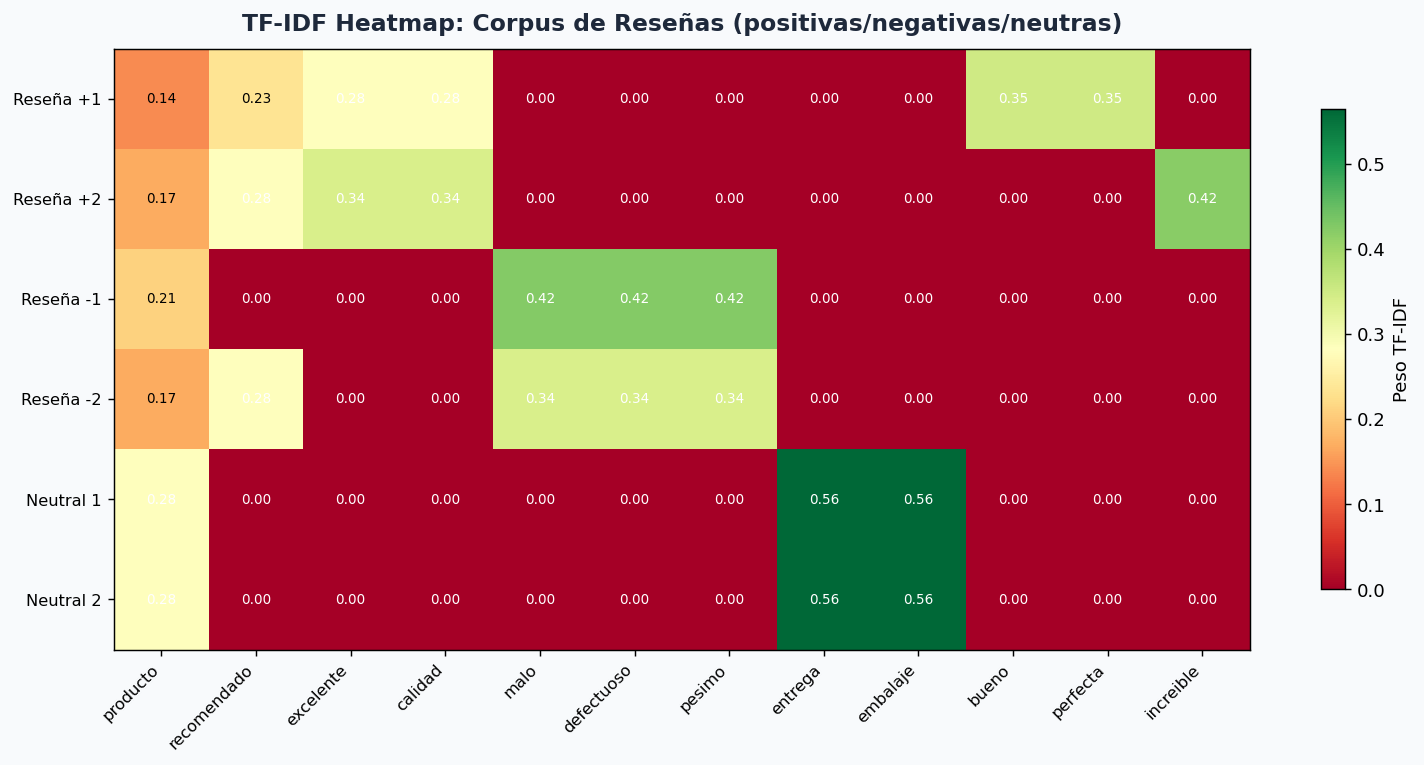
# Corpus de reseñas
reseñas = [
"excelente producto muy bueno recomendado",
"terrible mal pesimo no funciona defectuoso",
"producto normal entrega rapida correcto",
"increible calidad perfecta muy recomendado",
"malo roto defectuoso no recomendado terrible",
]
labels = [1, 0, 2, 1, 0] # 0=neg, 1=pos, 2=neutro
X_tfidf = tfidf_vec.fit_transform(reseñas)
print(f"Shape: {X_tfidf.shape}") # (5, N_features)
print(f"Densidad: {X_tfidf.nnz / (X_tfidf.shape[0]*X_tfidf.shape[1]):.2%}") # muy disperso
# Ver palabras mas importantes para el documento 0
feature_names = tfidf_vec.get_feature_names_out()
scores = X_tfidf[0].toarray()[0]
top_idx = scores.argsort()[::-1][:5]
for idx in top_idx:
if scores[idx] > 0:
print(f" '{feature_names[idx]}': {scores[idx]:.4f}")
Heatmap TF-IDF en corpus de reseñas
7. Clasificacion de texto con TF-IDF
Con TF-IDF como representacion, los modelos de ML clasicos alcanzan rendimiento sorprendentemente bueno.
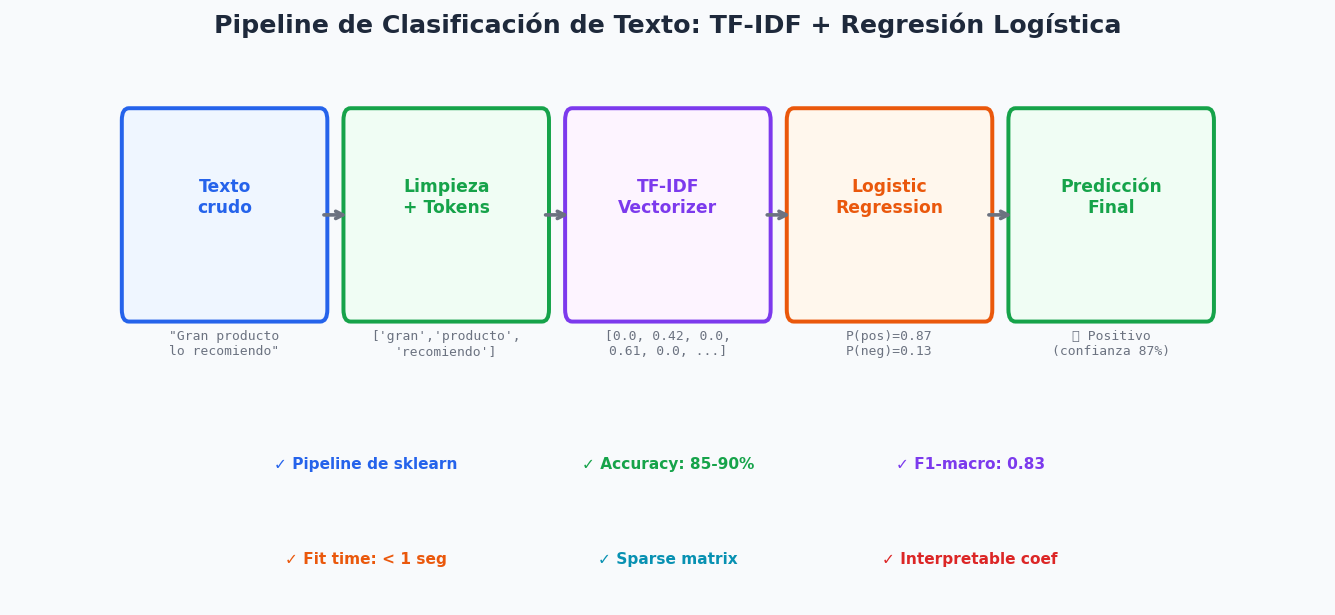
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
import numpy as np
# Dataset simulado de analisis de sentimiento
textos = [
"excelente servicio muy rapido lo recomiendo",
"horrible experiencia nunca mas volvere",
"producto ok nada especial precio razonable",
"increible calidad supero mis expectativas",
"mal servicio tardaron demasiado muy caro",
"entrega puntual producto bien embalado",
"decepcionante calidad baja no vale el precio",
"perfecto exactamente lo que necesitaba",
"regular podria ser mejor pero cumple",
"pesimo tuve que devolver el producto",
]
labels = [1, 0, 2, 1, 0, 2, 0, 1, 2, 0] # 0=neg, 1=pos, 2=neutro
# Pipeline sklearn: preprocesamiento + modelo en un solo objeto
pipeline_lr = Pipeline([
("tfidf", TfidfVectorizer(
ngram_range=(1, 2),
max_features=1000,
sublinear_tf=True,
)),
("clf", LogisticRegression(
C=1.0, # inverso de regularizacion (mayor = menos regularizacion)
max_iter=1000,
class_weight="balanced", # para clases desbalanceadas
solver="lbfgs",
multi_class="multinomial",
)),
])
# Comparar multiples modelos
modelos = {
"Naive Bayes": Pipeline([("tfidf", TfidfVectorizer(ngram_range=(1,2))),
("clf", MultinomialNB(alpha=0.1))]),
"Logistic Reg": pipeline_lr,
"Linear SVM": Pipeline([("tfidf", TfidfVectorizer(ngram_range=(1,2), sublinear_tf=True)),
("clf", LinearSVC(C=1.0, max_iter=2000))]),
}
print("Comparacion de modelos (cv=3):")
for nombre, modelo in modelos.items():
scores = cross_val_score(modelo, textos, labels, cv=3, scoring="f1_macro")
print(f" {nombre:<18}: F1-macro = {scores.mean():.3f} ± {scores.std():.3f}")
# Entrenar y evaluar en split manual
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
textos, labels, test_size=0.3, random_state=42, stratify=labels
)
pipeline_lr.fit(X_train, y_train)
y_pred = pipeline_lr.predict(X_test)
print("\nReporte de clasificacion:")
print(classification_report(y_test, y_pred,
target_names=["Negativo", "Positivo", "Neutro"]))
Analizar los coeficientes del modelo
# Con LogisticRegression, los coeficientes revelan que palabras son mas informativas
def top_features_por_clase(pipeline, n_features=10):
"""Muestra las palabras con mayor peso para cada clase."""
tfidf = pipeline.named_steps["tfidf"]
clf = pipeline.named_steps["clf"]
nombres = tfidf.get_feature_names_out()
clases = clf.classes_
for i, clase in enumerate(clases):
coefs = clf.coef_[i]
top_pos = np.argsort(coefs)[-n_features:][::-1]
top_neg = np.argsort(coefs)[:n_features]
print(f"\nClase '{clase}':")
print(f" Top palabras positivas: {[nombres[j] for j in top_pos]}")
print(f" Top palabras negativas: {[nombres[j] for j in top_neg]}")
pipeline_lr.fit(textos, labels)
top_features_por_clase(pipeline_lr, n_features=5)
8. Evaluacion y metricas en NLP
En NLP casi nunca se usa solo accuracy. El texto suele tener clases desbalanceadas.
from sklearn.metrics import (
accuracy_score, precision_recall_fscore_support,
confusion_matrix, roc_auc_score
)
import numpy as np
y_true = [1, 0, 1, 1, 0, 2, 0, 1, 2, 0]
y_pred = [1, 0, 0, 1, 0, 2, 1, 1, 2, 0]
# Metricas por clase
prec, rec, f1, support = precision_recall_fscore_support(
y_true, y_pred, average=None, labels=[0, 1, 2]
)
for cls, p, r, f, s in zip(["neg", "pos", "neu"], prec, rec, f1, support):
print(f" {cls}: P={p:.2f} R={r:.2f} F1={f:.2f} n={s}")
# F1 macro vs weighted
f1_macro = precision_recall_fscore_support(y_true, y_pred, average="macro")[2]
f1_weighted = precision_recall_fscore_support(y_true, y_pred, average="weighted")[2]
print(f"\nF1-macro: {f1_macro:.3f} (penaliza clases con F1 bajo, sin importar tamaño)")
print(f"F1-weighted: {f1_weighted:.3f} (pesa por frecuencia de clase)")
# Cuando usar cual:
# F1-macro: competencias con clases raras que importan
# F1-weighted: datasets con desbalance natural
# Accuracy: SOLO si clases estan perfectamente balanceadas
9. Comparacion: clasico vs transformer
El momento de decidir si usar TF-IDF+LogReg o un transformer depende principalmente del tamaño del dataset y el tiempo disponible.
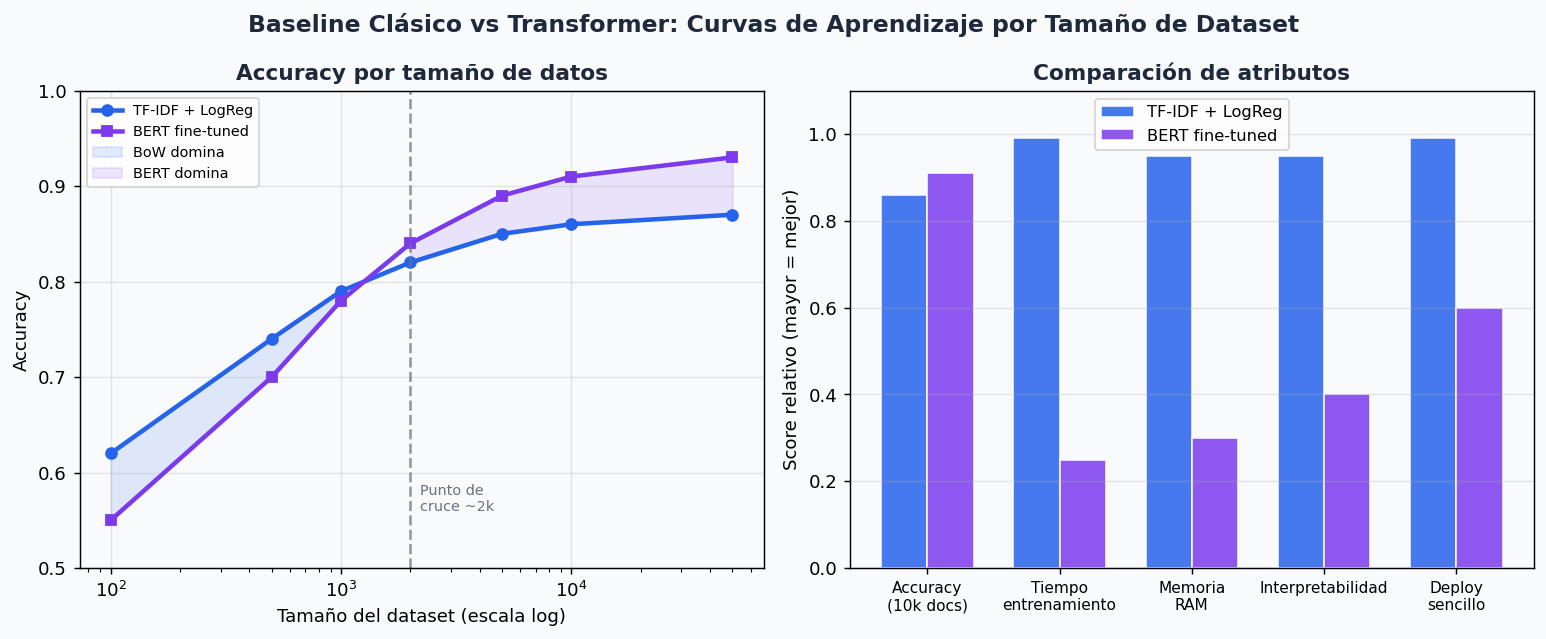
| Criterio | TF-IDF + LogReg | BERT fine-tuned |
|---|---|---|
| Dataset < 1k ejemplos | Excelente | Mediocre (overfitting) |
| Dataset 1k-10k | Muy bueno | Bueno-muy bueno |
| Dataset > 100k | Bueno | Excelente |
| Tiempo de entrenamiento | Segundos | Minutos-horas |
| Memoria RAM | < 500 MB | 4-16 GB |
| Interpretabilidad | Alta (coefs) | Baja (black-box) |
| Idiomas con pocos recursos | Funciona bien | Limitado por modelo pre-trained |
| Texto muy corto (tweets) | Regular | Bueno con CLS token |
Regla practica para competencias: empieza SIEMPRE con TF-IDF + LogReg como baseline. Te da un numero concreto en minutos y te dice si el problema es facil o dificil antes de invertir tiempo en transformers.
# Receta de baseline en 10 lineas para cualquier clasificacion de texto
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
def baseline_nlp(textos, labels, cv=5):
"""Baseline TF-IDF + LogReg listo para competencias."""
pipe = Pipeline([
("tfidf", TfidfVectorizer(
ngram_range=(1, 2),
max_features=50_000,
sublinear_tf=True,
min_df=2,
)),
("clf", LogisticRegression(
C=5.0,
max_iter=1000,
class_weight="balanced",
)),
])
scores = cross_val_score(pipe, textos, labels, cv=cv, scoring="f1_macro")
print(f"Baseline F1-macro: {scores.mean():.4f} ± {scores.std():.4f}")
return pipe
Dashboard resumen
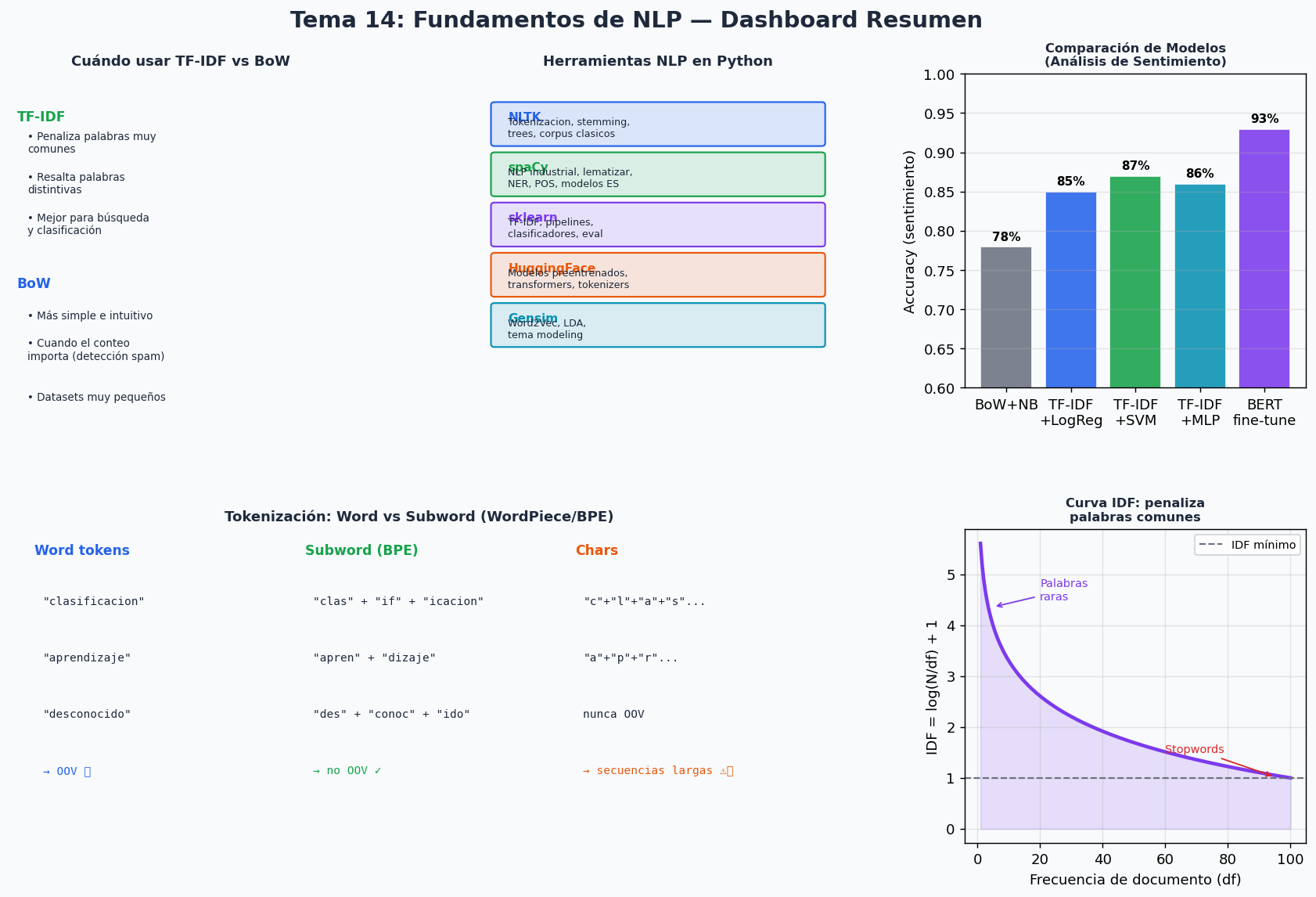
Recursos recomendados
- Documentacion de NLTK: libreria clasica con tokenizacion, stemming, corpora y parsers para espanol e ingles
- Documentacion de spaCy: NLP industrial con modelos preentrenados en espanol (
es_core_news_sm/md/lg) - Hugging Face NLP Course — Modulos 1-3: introduccion moderna que conecta preprocessing clasico con transformers
- Kaggle Learn — Natural Language Processing: practica guiada con TF-IDF, embeddings y clasificacion
- Speech and Language Processing — Jurafsky & Martin (Cap. 2-4): referencia academica de NLP con fundamentos solidos
Navegacion
← 13. Redes Convolucionales (CNNs) | 15. Embeddings y Transformers →