16. Flujo de Trabajo en Kaggle y Competencias
Por que el flujo importa tanto como el modelo
Una verdad incomoda de las competencias: la mayoria de los equipos que pierden no pierden por saber menos teoria. Pierden por saltar pasos, confiar en el Leaderboard Publico, no registrar sus experimentos, o filtrar informacion del test al train sin darse cuenta.
El flujo de trabajo es el meta-algoritmo que decide como vas a usar tu tiempo y tus recursos de computo. Dominarlo te pone por encima del 80% de los participantes antes de escribir una sola linea de modelo.
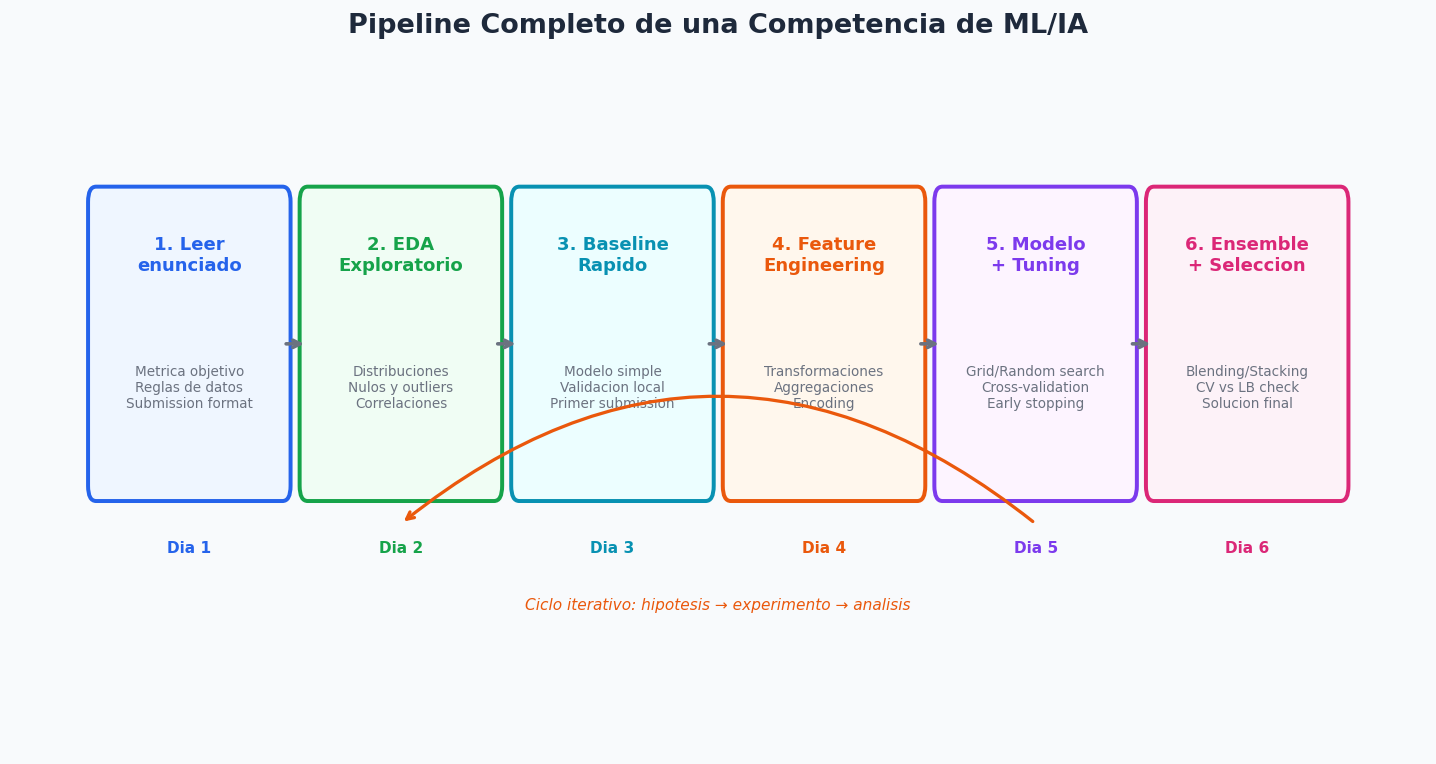
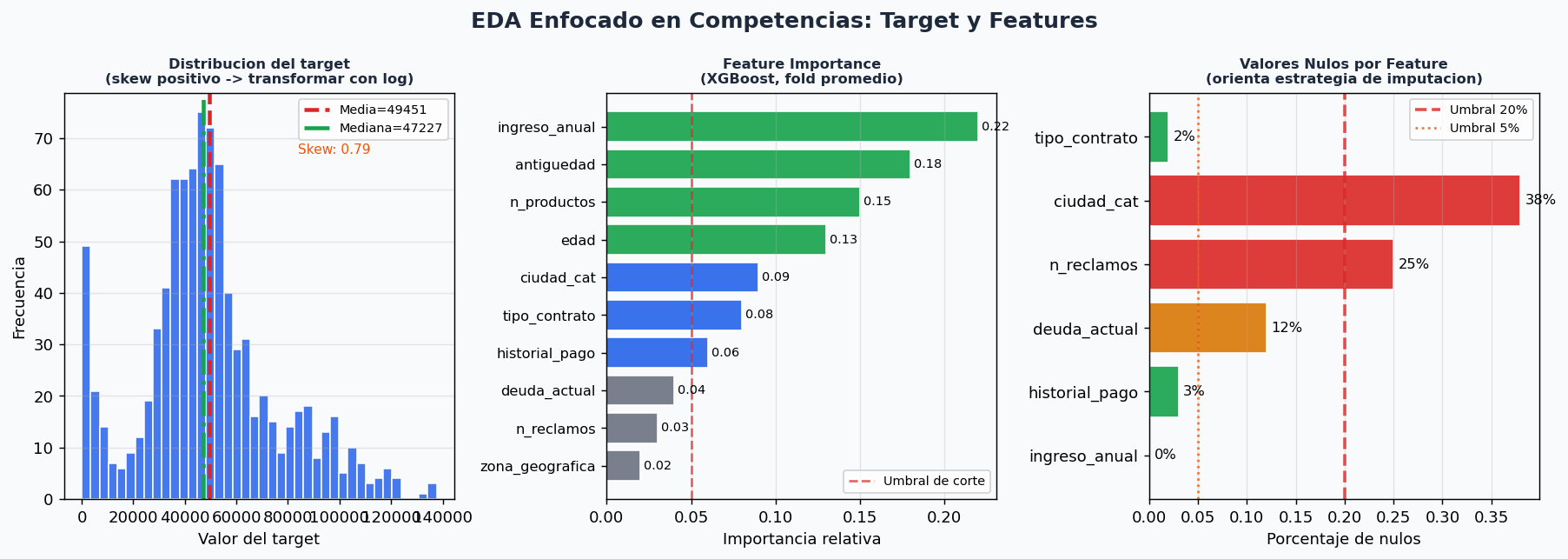
1. EDA enfocado en competencias
El EDA en competencias no es exploratorio libre: es diagnostico dirigido por la metrica. Las preguntas que debes responder en la primera hora:
- Cual es la distribucion del target? (regresion: skew? log-transform? clasificacion: desbalance?)
- Que features tienen mas correlacion con el target?
- Que porcentaje de nulos tiene cada feature? Que estrategia de imputacion usa?
- Hay features categoricas de alta cardinalidad que requieren encoding especial?
- Hay patrones temporales? (si hay fecha, son los datos i.i.d.?)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
def eda_competencia(df, target_col, figsize=(16, 10)):
"""EDA rapido y dirigido para competencias."""
print(f"Shape: {df.shape}")
print(f"\nTipos de datos:\n{df.dtypes.value_counts()}")
print(f"\nNulos por feature (top 10):")
nulos = df.isnull().mean().sort_values(ascending=False)
print(nulos[nulos > 0].head(10))
# Target
target = df[target_col].dropna()
print(f"\nTarget: {target_col}")
print(f" min={target.min():.4f} max={target.max():.4f}")
print(f" mean={target.mean():.4f} median={target.median():.4f}")
print(f" skewness={stats.skew(target):.4f}")
if stats.skew(target) > 1.0:
print(" >> Skew > 1: considera log1p(target) antes de entrenar")
fig, axes = plt.subplots(2, 3, figsize=figsize)
# 1. Distribucion del target
ax = axes[0, 0]
ax.hist(target, bins=50, color="steelblue", edgecolor="white", alpha=0.8)
ax.axvline(target.mean(), color="red", ls="--", label=f"media={target.mean():.2f}")
ax.axvline(target.median(), color="green", ls="-.", label=f"mediana={target.median():.2f}")
ax.set_title(f"Distribucion: {target_col}")
ax.legend()
# 2. Si aplica log-transform
if stats.skew(target) > 0.5:
ax2 = axes[0, 1]
ax2.hist(np.log1p(target), bins=50, color="orange", edgecolor="white", alpha=0.8)
ax2.set_title(f"log1p({target_col})")
# 3. Correlacion con features numericas
numericas = df.select_dtypes(include=[np.number]).columns.tolist()
if target_col in numericas:
numericas.remove(target_col)
if numericas:
corrs = df[numericas + [target_col]].corr()[target_col].drop(target_col)
corrs.abs().sort_values(ascending=True).tail(10).plot(
kind="barh", ax=axes[0, 2], color="mediumpurple")
axes[0, 2].set_title(f"Correlacion con {target_col}")
# 4. Mapa de nulos
nulos_plot = df[df.columns[df.isnull().any()]].isnull()
if not nulos_plot.empty:
sns.heatmap(nulos_plot.T, ax=axes[1, 0], cbar=False, yticklabels=True)
axes[1, 0].set_title("Mapa de valores nulos")
# 5. Balance de clases (si clasificacion)
if df[target_col].nunique() <= 20:
df[target_col].value_counts().plot(kind="bar", ax=axes[1, 1], color="teal")
axes[1, 1].set_title("Balance de clases")
# 6. Features categoricas: cardinalidad
cats = df.select_dtypes(include=["object", "category"]).columns
if len(cats) > 0:
card = {c: df[c].nunique() for c in cats}
pd.Series(card).sort_values(ascending=False).head(10).plot(
kind="barh", ax=axes[1, 2], color="coral")
axes[1, 2].set_title("Cardinalidad de categoricas")
plt.tight_layout()
return fig
# Uso
# df = pd.read_csv("train.csv")
# eda_competencia(df, target_col="precio")
2. Baseline en menos de 1 hora
El baseline no es una perdida de tiempo. Es el punto de referencia que te dice si tus mejoras futuras son reales. Una regla practica: si no tienes baseline en la primera hora, estas perdiendo el tiempo.
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OrdinalEncoder
from sklearn.impute import SimpleImputer
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import StratifiedKFold, cross_val_score
import pandas as pd
import numpy as np
def baseline_rapido(df_train, target_col, task="clasificacion"):
"""
Baseline reproducible en <1 hora para cualquier dataset tabular.
Maneja automaticamente tipos de features, nulos y encoding.
"""
X = df_train.drop(columns=[target_col])
y = df_train[target_col]
# Separar features por tipo
num_cols = X.select_dtypes(include=[np.number]).columns.tolist()
cat_cols = X.select_dtypes(include=["object", "category"]).columns.tolist()
# Preprocesamiento
num_pipe = Pipeline([
("imputer", SimpleImputer(strategy="median")),
("scaler", StandardScaler()),
])
cat_pipe = Pipeline([
("imputer", SimpleImputer(strategy="most_frequent")),
("encoder", OrdinalEncoder(handle_unknown="use_encoded_value", unknown_value=-1)),
])
preprocessor = ColumnTransformer([
("num", num_pipe, num_cols),
("cat", cat_pipe, cat_cols),
])
# Modelo baseline (GBM ligero)
from lightgbm import LGBMClassifier, LGBMRegressor
if task == "clasificacion":
modelo = LGBMClassifier(n_estimators=300, learning_rate=0.05,
num_leaves=31, random_state=42, verbose=-1)
scoring = "f1_macro"
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
else:
modelo = LGBMRegressor(n_estimators=300, learning_rate=0.05,
num_leaves=31, random_state=42, verbose=-1)
scoring = "neg_root_mean_squared_error"
from sklearn.model_selection import KFold
cv = KFold(n_splits=5, shuffle=True, random_state=42)
pipe = Pipeline([("prep", preprocessor), ("model", modelo)])
scores = cross_val_score(pipe, X, y, cv=cv, scoring=scoring, n_jobs=-1)
print(f"Baseline 5-Fold {scoring}:")
print(f" Folds: {scores.round(4)}")
print(f" Media: {scores.mean():.4f} ± {scores.std():.4f}")
return pipe, scores
# df_train = pd.read_csv("train.csv")
# pipe_base, scores_base = baseline_rapido(df_train, "target")
3. Validacion cruzada vs Leaderboard
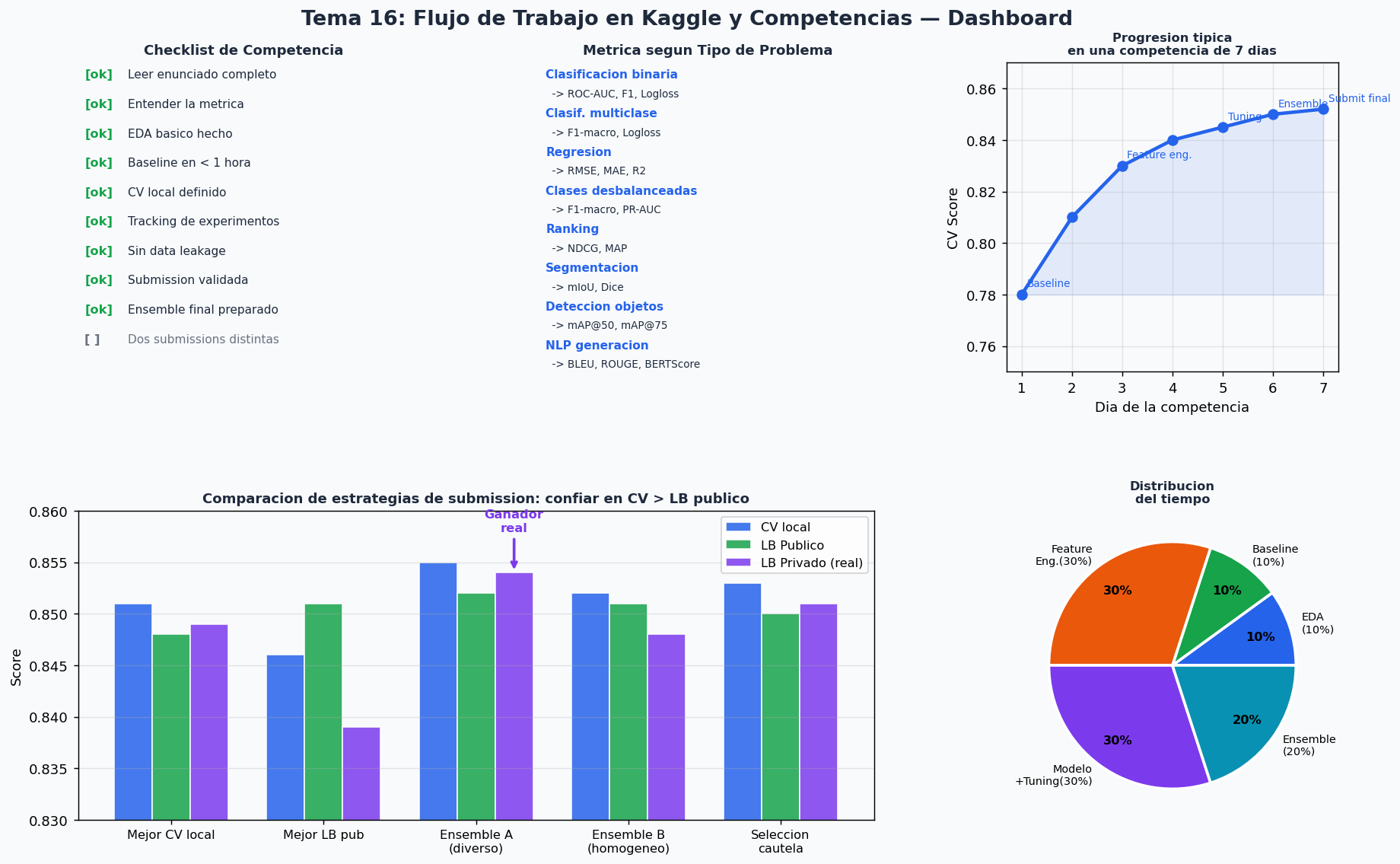
La regla de oro: confia en tu CV local, no en el LB publico.
El Leaderboard Publico solo usa el 20-30% del test set. Si haces mas de 2 submissions por dia ajustando al LB publico, estas haciendo overfit al test set. La metrica que importa es el LB Privado, que se revela al final y usa el 70-80% restante.
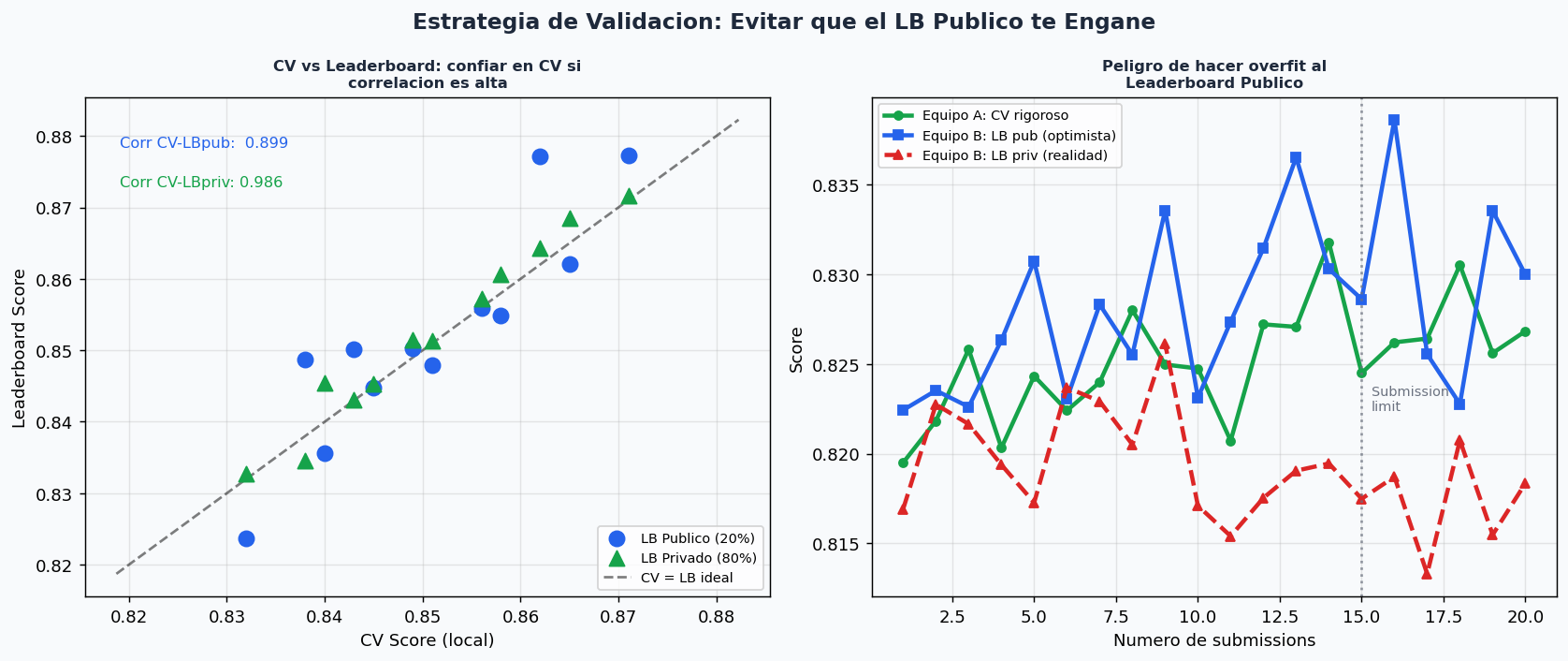
from sklearn.model_selection import StratifiedKFold, GroupKFold, TimeSeriesSplit
import numpy as np
def elegir_cv(df, target_col, tipo="estandar", grupo_col=None, fecha_col=None):
"""
Elige la estrategia de CV correcta segun el tipo de datos.
tipo:
"estandar" -> StratifiedKFold (clasificacion desbalanceada)
"grupo" -> GroupKFold (no mezclar entidades: clientes, pacientes)
"temporal" -> TimeSeriesSplit (series temporales, no leak futuro)
"regresion" -> KFold simple (target continuo, i.i.d.)
"""
if tipo == "estandar":
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
return cv, df[target_col], None
elif tipo == "grupo":
assert grupo_col, "grupo_col es requerido para CV de grupo"
cv = GroupKFold(n_splits=5)
return cv, df[target_col], df[grupo_col]
elif tipo == "temporal":
assert fecha_col, "fecha_col es requerido para CV temporal"
df_sorted = df.sort_values(fecha_col)
cv = TimeSeriesSplit(n_splits=5)
return cv, df_sorted[target_col], None
else:
from sklearn.model_selection import KFold
cv = KFold(n_splits=5, shuffle=True, random_state=42)
return cv, df[target_col], None
# Ejemplo de uso con GroupKFold (ej: transacciones por cliente)
# cv, y, groups = elegir_cv(df, "fraude", tipo="grupo", grupo_col="cliente_id")
# scores = cross_val_score(pipe, X, y, cv=cv, groups=groups, scoring="roc_auc")
def cv_diagnostico(scores, nombre_modelo="modelo"):
"""Diagnostica la calidad del CV."""
media = scores.mean()
std = scores.std()
cv_pct = std / media * 100
print(f"\n{nombre_modelo}:")
print(f" CV: {media:.4f} ± {std:.4f} (CV%={cv_pct:.1f}%)")
if cv_pct > 5:
print(" >> Alta varianza entre folds (CV% > 5%): considera mas folds o repeatedKFold")
if std < 0.002:
print(" >> Varianza muy baja: el dataset puede ser demasiado facil o hay leakage")
if media > 0.99:
print(" >> Score > 0.99: señal de posible data leakage")
return media, std
4. Tracking de experimentos
Sin registro sistematico no puedes saber que mejoro, que empeoro, ni reproducir tu mejor solucion.
![]()
import json
import os
from datetime import datetime
from dataclasses import dataclass, asdict, field
from typing import Optional
@dataclass
class Experimento:
"""Registro de un experimento de ML."""
nombre: str
modelo: str
features: str
cv_score: float
cv_std: float
lb_publico: Optional[float] = None
notas: str = ""
timestamp: str = field(default_factory=lambda: datetime.now().isoformat())
params: dict = field(default_factory=dict)
class ExperimentTracker:
"""Tracker minimalista de experimentos — sin dependencias externas."""
def __init__(self, path="experimentos.jsonl"):
self.path = path
def log(self, exp: Experimento):
with open(self.path, "a", encoding="utf-8") as f:
f.write(json.dumps(asdict(exp), ensure_ascii=False) + "\n")
print(f"[{exp.nombre}] CV={exp.cv_score:.4f}±{exp.cv_std:.4f} "
f"LB={exp.lb_publico} | {exp.notas}")
def cargar(self):
import pandas as pd
if not os.path.exists(self.path):
return pd.DataFrame()
with open(self.path, encoding="utf-8") as f:
return pd.DataFrame([json.loads(l) for l in f])
def resumen(self):
df = self.cargar()
if df.empty:
print("Sin experimentos registrados")
return
df = df.sort_values("cv_score", ascending=False)
cols = ["nombre", "modelo", "features", "cv_score", "cv_std", "lb_publico", "notas"]
print(df[cols].to_string(index=False))
print(f"\nMejor CV: {df['cv_score'].max():.4f} ({df.iloc[0]['nombre']})")
# Ejemplo de uso
tracker = ExperimentTracker("mi_competencia/experimentos.jsonl")
# Despues de cada experimento:
tracker.log(Experimento(
nombre = "exp_01_baseline",
modelo = "LGBM",
features = "features_base",
cv_score = 0.831,
cv_std = 0.008,
lb_publico= 0.826,
notas = "Baseline con ordinal encoding",
params = {"n_estimators": 500, "lr": 0.05, "num_leaves": 31},
))
tracker.log(Experimento(
nombre = "exp_02_target_enc",
modelo = "LGBM",
features = "features_base + target_enc_cat",
cv_score = 0.845,
cv_std = 0.007,
notas = "+1.4pts, target encoding con regularizacion",
))
tracker.resumen()
# Alternativa con MLflow (para proyectos mas grandes)
# import mlflow
# mlflow.set_experiment("mi_competencia")
# with mlflow.start_run(run_name="exp_02"):
# mlflow.log_params({"n_estimators": 500, "lr": 0.05})
# mlflow.log_metric("cv_f1", 0.845)
# mlflow.log_metric("cv_std", 0.007)
5. Feature Engineering para datos tabulares
El feature engineering suele dar mas ganancia que el tuning de hiperparametros.
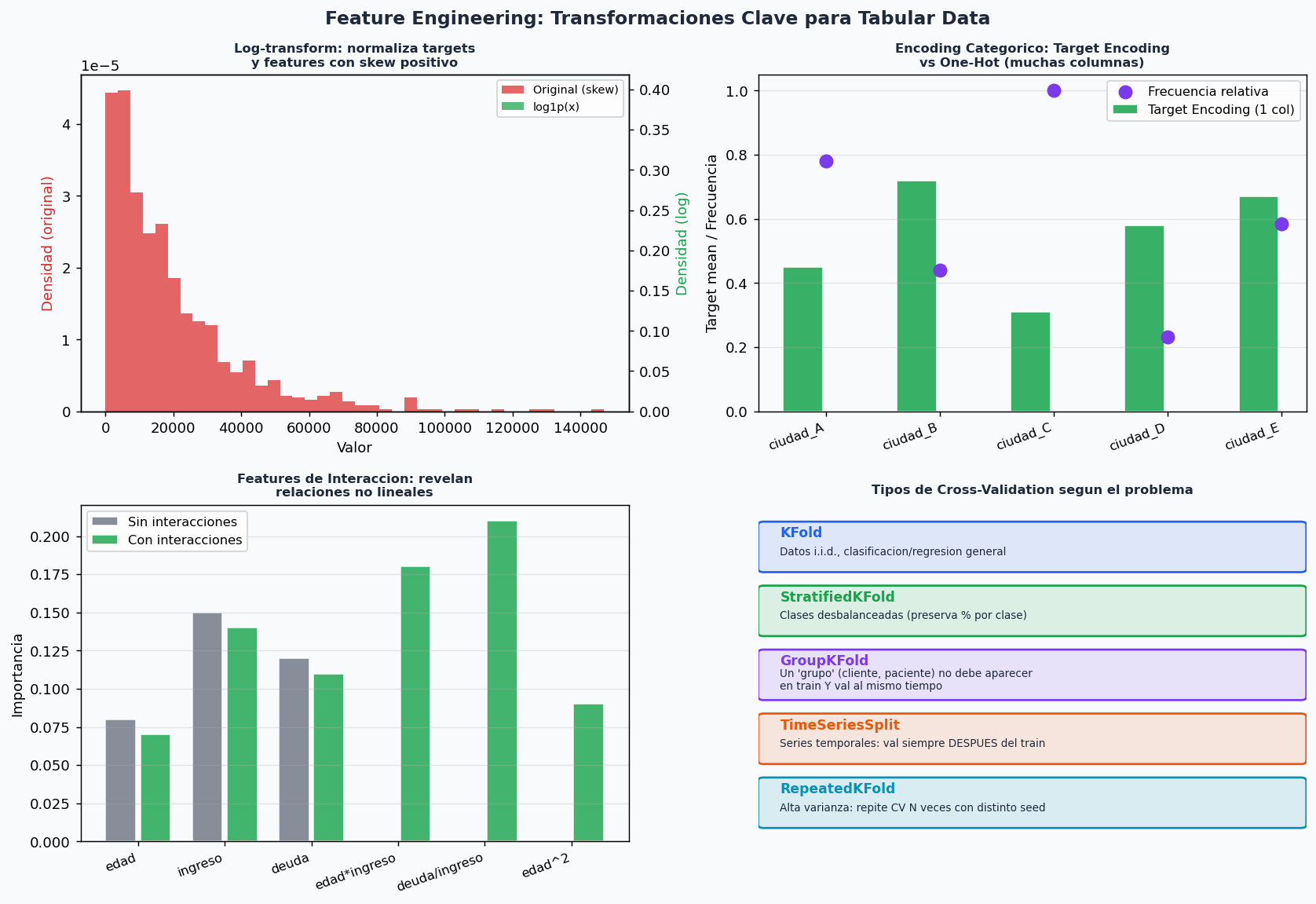
import pandas as pd
import numpy as np
from sklearn.model_selection import KFold
# ── 1. Log-transform para targets/features con skew ─────────────────────────
# Regla practica: si skewness > 1.0, aplica log1p
# Para targets de regresion: entrenar con log1p(y), predecir, luego expm1
def preparar_target_regresion(y_train, y_test=None):
"""Aplica log1p al target si tiene skew alto."""
from scipy.stats import skew
sk = skew(y_train)
if sk > 1.0:
print(f"Skew={sk:.2f} > 1.0 → aplicando log1p al target")
y_train_t = np.log1p(y_train)
y_test_t = np.log1p(y_test) if y_test is not None else None
return y_train_t, y_test_t, True # True = aplicado
return y_train, y_test, False
# ── 2. Target Encoding con regularizacion de Laplace (evita leakage) ─────────
def target_encoding_cv(X_train, y_train, cat_col, n_splits=5, alpha=10):
"""
Target encoding con K-Fold para evitar leakage.
alpha: suavizado hacia la media global (mayor alpha = mas regularizacion)
"""
global_mean = y_train.mean()
oof_enc = np.zeros(len(X_train))
kf = KFold(n_splits=n_splits, shuffle=True, random_state=42)
for fold_idx, (train_idx, val_idx) in enumerate(kf.split(X_train)):
X_tr, y_tr = X_train.iloc[train_idx], y_train.iloc[train_idx]
X_val = X_train.iloc[val_idx]
stats_fold = y_tr.groupby(X_tr[cat_col]).agg(["mean", "count"])
# Suavizado: mezcla media del grupo con media global
stats_fold["enc"] = (
(stats_fold["mean"] * stats_fold["count"] + global_mean * alpha) /
(stats_fold["count"] + alpha)
)
oof_enc[val_idx] = X_val[cat_col].map(stats_fold["enc"]).fillna(global_mean)
# Encoding final para inferencia (usa todo el train)
stats_full = y_train.groupby(X_train[cat_col]).agg(["mean", "count"])
stats_full["enc"] = (
(stats_full["mean"] * stats_full["count"] + global_mean * alpha) /
(stats_full["count"] + alpha)
)
return oof_enc, stats_full["enc"]
# ── 3. Features de interaccion ───────────────────────────────────────────────
def crear_interacciones(df, cols_num):
"""Genera features de multiplicacion y cociente para pares de columnas."""
nuevas = {}
for i, col_a in enumerate(cols_num):
for col_b in cols_num[i+1:]:
nuevas[f"{col_a}_x_{col_b}"] = df[col_a] * df[col_b]
# Cociente (protegido contra division por cero)
denom = df[col_b].replace(0, np.nan)
nuevas[f"{col_a}_div_{col_b}"] = (df[col_a] / denom).fillna(0)
return pd.DataFrame(nuevas, index=df.index)
# ── 4. Aggregation features (para datasets con grupos) ───────────────────────
def agregar_por_grupo(df, grupo_col, valor_col, prefijo=""):
"""Crea estadisticas del 'valor_col' agrupado por 'grupo_col'."""
aggs = df.groupby(grupo_col)[valor_col].agg(
["mean", "std", "min", "max", "count", "median"]
).add_prefix(f"{prefijo}{valor_col}_grupo_")
return df.merge(aggs, on=grupo_col, how="left")
# Ejemplo completo de pipeline de features
def pipeline_features(df_train, df_test, target_col="target"):
"""Pipeline de features para un dataset tabular generico."""
X_tr = df_train.drop(columns=[target_col]).copy()
X_te = df_test.copy()
y_tr = df_train[target_col]
num_cols = X_tr.select_dtypes(include=[np.number]).columns.tolist()
# Log-transform features con skew alto
for col in num_cols:
from scipy.stats import skew as scipy_skew
if X_tr[col].min() > 0 and scipy_skew(X_tr[col].dropna()) > 1.5:
X_tr[f"log_{col}"] = np.log1p(X_tr[col])
X_te[f"log_{col}"] = np.log1p(X_te[col])
# Features de interaccion (solo top features para no explotar dimensionalidad)
top_num = num_cols[:4] # solo top 4 por economia
inter_tr = crear_interacciones(X_tr[top_num], top_num)
inter_te = crear_interacciones(X_te[top_num], top_num)
X_tr = pd.concat([X_tr, inter_tr], axis=1)
X_te = pd.concat([X_te, inter_te], axis=1)
return X_tr, X_te, y_tr
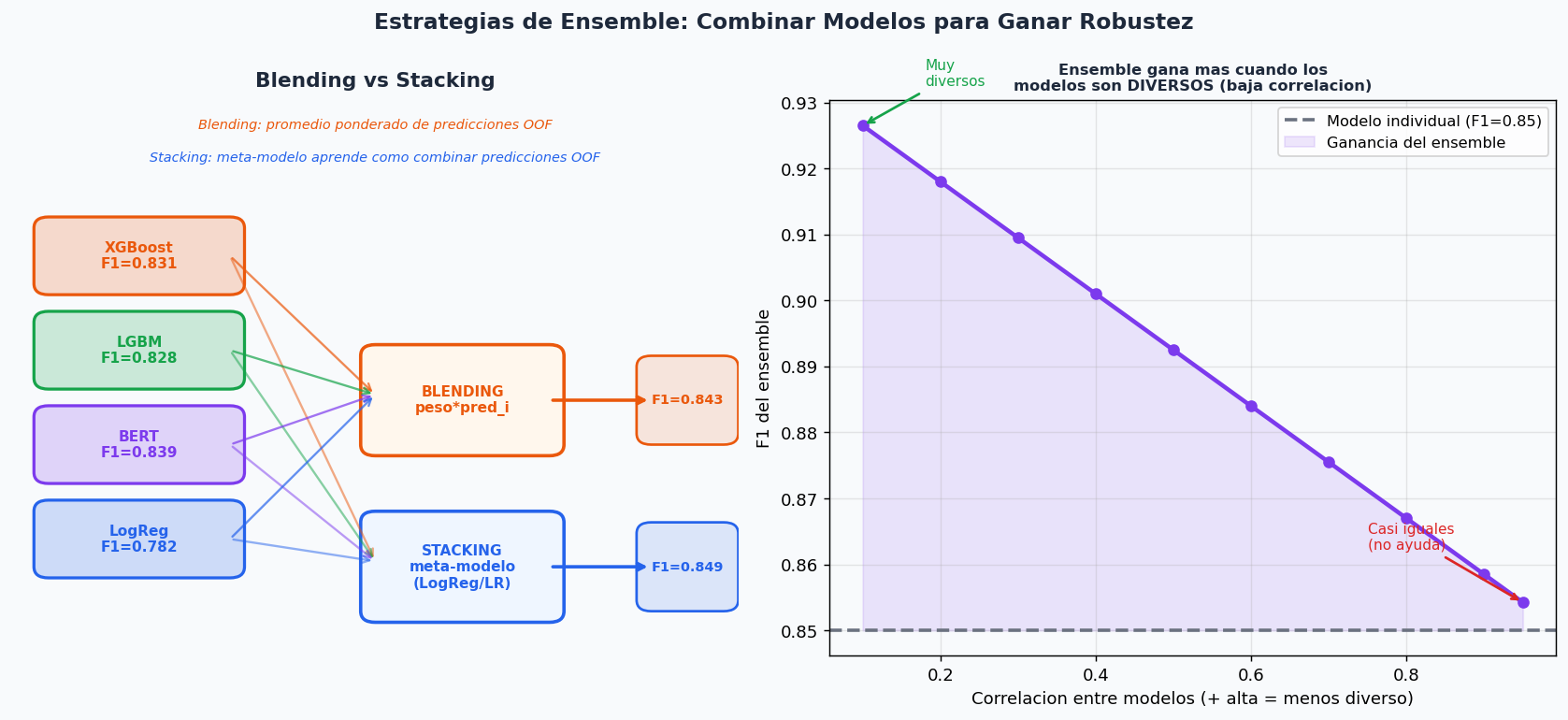
6. Estrategias de Ensemble
El ensemble casi siempre mejora sobre el mejor modelo individual, especialmente cuando los modelos son diversos (bajan la correlacion entre errores).
import numpy as np
from sklearn.model_selection import StratifiedKFold
from sklearn.linear_model import LogisticRegression
# ── Blending: promedio ponderado de predicciones OOF ────────────────────────
def blending(oof_preds_list, test_preds_list, weights=None):
"""
oof_preds_list: lista de arrays OOF [n_train] por modelo
test_preds_list: lista de arrays de predicciones test [n_test] por modelo
weights: pesos por modelo (None = igual)
Optimiza pesos con Nelder-Mead si weights=None y hay suficientes datos.
"""
n = len(oof_preds_list)
if weights is None:
weights = np.ones(n) / n
oof_blend = sum(w * p for w, p in zip(weights, oof_preds_list))
test_blend = sum(w * p for w, p in zip(weights, test_preds_list))
return oof_blend, test_blend
def optimizar_pesos_blend(oof_preds_list, y_true, metrica_fn):
"""Optimiza los pesos del blend minimizando la metrica OOF."""
from scipy.optimize import minimize
n = len(oof_preds_list)
oof_stack = np.column_stack(oof_preds_list)
def neg_score(w):
w = np.abs(w) / np.sum(np.abs(w))
blend = oof_stack @ w
return -metrica_fn(y_true, blend)
result = minimize(neg_score, x0=np.ones(n)/n, method="Nelder-Mead",
options={"maxiter": 1000})
pesos_opt = np.abs(result.x) / np.sum(np.abs(result.x))
print(f"Pesos optimos: {pesos_opt.round(3)}")
return pesos_opt
# ── Stacking: meta-modelo que aprende de predicciones OOF ────────────────────
def stacking(models, X_train, y_train, X_test, cv=None, task="clf"):
"""
Genera meta-features OOF de cada modelo base → entrena meta-modelo.
models: lista de (nombre, estimador sklearn)
"""
if cv is None:
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
n_train = len(X_train)
n_test = len(X_test)
n_models = len(models)
oof_meta = np.zeros((n_train, n_models))
test_meta = np.zeros((n_test, n_models))
for col_idx, (nombre, modelo) in enumerate(models):
test_fold_preds = []
for fold_i, (tr_idx, val_idx) in enumerate(cv.split(X_train, y_train)):
X_tr, y_tr = X_train[tr_idx], y_train[tr_idx]
X_val = X_train[val_idx]
modelo.fit(X_tr, y_tr)
if task == "clf":
oof_meta[val_idx, col_idx] = modelo.predict_proba(X_val)[:, 1]
test_fold_preds.append(modelo.predict_proba(X_test)[:, 1])
else:
oof_meta[val_idx, col_idx] = modelo.predict(X_val)
test_fold_preds.append(modelo.predict(X_test))
test_meta[:, col_idx] = np.mean(test_fold_preds, axis=0)
print(f" Modelo {nombre} [fold done]")
# Meta-modelo sobre OOF
meta = LogisticRegression(C=1.0, max_iter=1000) if task == "clf" else \
__import__("sklearn.linear_model", fromlist=["Ridge"]).Ridge()
meta.fit(oof_meta, y_train)
test_final = meta.predict_proba(test_meta)[:, 1] if task == "clf" else \
meta.predict(test_meta)
return oof_meta, test_final, meta
# ── Correlacion entre modelos (diagnostico de diversidad) ────────────────────
def diagnostico_diversidad(oof_preds_dict):
"""Calcula la correlacion entre modelos para evaluar la diversidad del ensemble."""
import pandas as pd
df = pd.DataFrame(oof_preds_dict)
corr = df.corr()
print("Correlacion entre modelos OOF:")
print(corr.round(3))
print("\nBaja correlacion (<0.95) = mas ganancia potencial del ensemble")
return corr
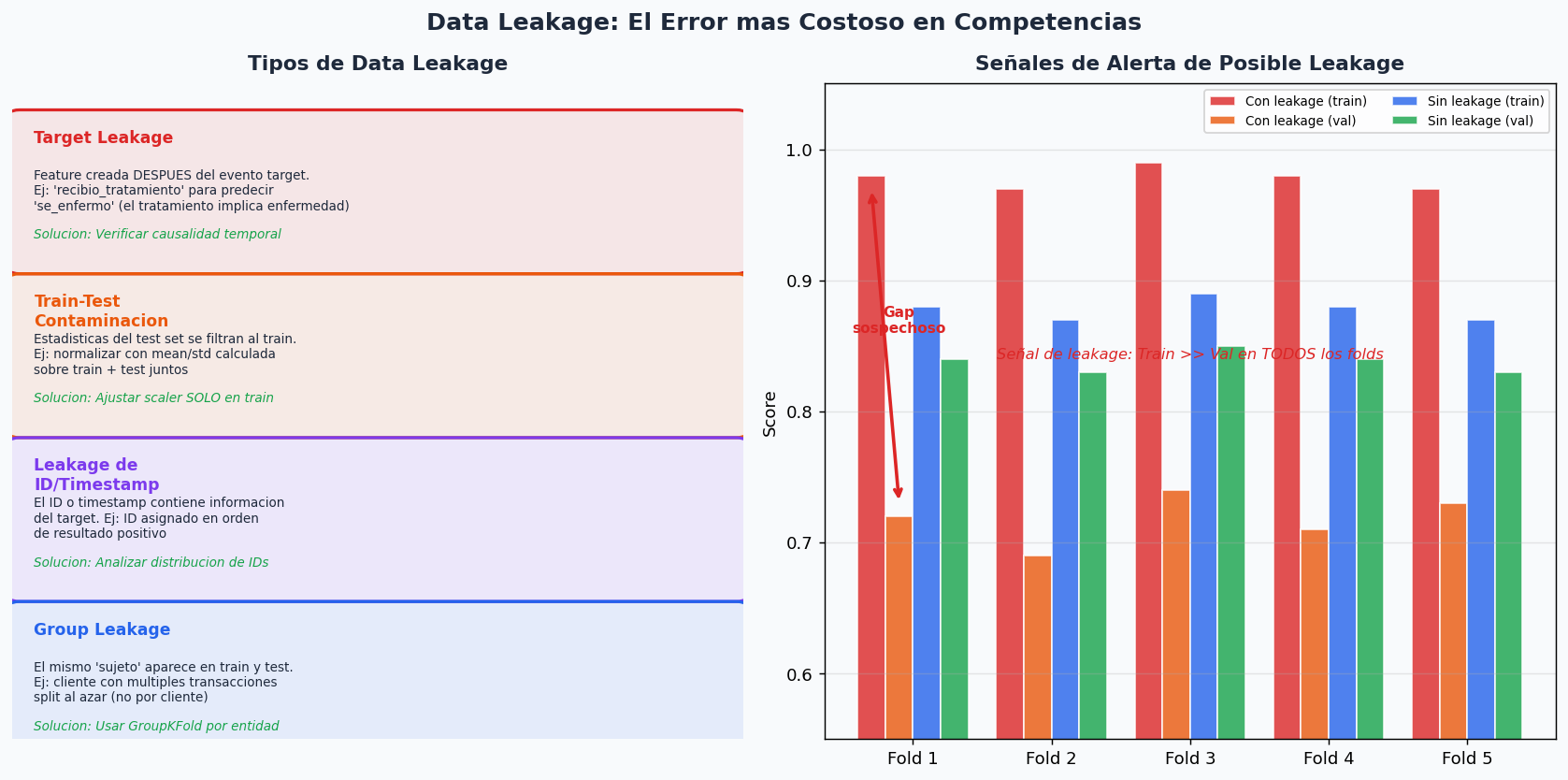
7. Data Leakage: el error mas costoso
Un modelo con leakage tiene CV > 0.99 y parece imparable — hasta que el LB Privado revela la realidad. El leakage es informacion del futuro o del test que se filtra al entrenamiento.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# ── Ejemplo 1: leakage por normalizar con todo el dataset ────────────────────
# MAL (leakage):
def normalizar_mal(X):
scaler = StandardScaler()
return scaler.fit_transform(X) # usa estadisticas de train+test!
# BIEN (sin leakage):
def normalizar_bien(X_train, X_test):
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train) # fit SOLO en train
X_test_scaled = scaler.transform(X_test) # solo transform en test
return X_train_scaled, X_test_scaled, scaler
# ── Ejemplo 2: leakage por target encoding con el fold completo ──────────────
# MAL (leakage):
def target_enc_mal(X, y, col):
medias = y.groupby(X[col]).mean()
return X[col].map(medias) # usa el target de los mismos datos que validas!
# BIEN: usar target encoding con K-Fold (ver seccion anterior)
# ── Ejemplo 3: leakage temporal ───────────────────────────────────────────────
# MAL:
def split_temporal_mal(df, target_col, test_size=0.2):
X = df.drop(columns=[target_col])
y = df[target_col]
return train_test_split(X, y, test_size=test_size, random_state=42)
# Problema: mezcla fechas futuras con pasadas en train
# BIEN:
def split_temporal_bien(df, fecha_col, target_col, test_fraction=0.2):
df_sorted = df.sort_values(fecha_col)
cutoff = int(len(df_sorted) * (1 - test_fraction))
df_train = df_sorted.iloc[:cutoff]
df_test = df_sorted.iloc[cutoff:]
return (df_train.drop(columns=[target_col]), df_train[target_col],
df_test.drop(columns=[target_col]), df_test[target_col])
# ── Checklist de deteccion de leakage ─────────────────────────────────────────
def detectar_leakage(X_train, y_train, modelo, cv, threshold_auc=0.99):
"""
Señales de alerta de posible data leakage.
Si el score CV es sospechosamente alto, investiga:
1. Hay features creadas despues del evento target?
2. El scaler/encoder fue ajustado con datos de test?
3. El mismo 'grupo' (cliente, producto) esta en train y val?
4. Hay un ID o timestamp correlacionado con el target?
"""
from sklearn.model_selection import cross_val_score
scores = cross_val_score(modelo, X_train, y_train, cv=cv, scoring="roc_auc")
cv_mean = scores.mean()
print(f"CV AUC: {cv_mean:.4f} ± {scores.std():.4f}")
if cv_mean > threshold_auc:
print(f"\n[ALERTA] Score > {threshold_auc} — posible data leakage!")
print(" Verificar:")
print(" 1. Features calculadas DESPUES del evento target")
print(" 2. Normalizacion/encoding ajustada en todo el dataset")
print(" 3. Group leakage (misma entidad en train y val)")
print(" 4. ID o timestamp con informacion del target")
# Correlacion de features con target (features con corr muy alta son sospechosas)
if hasattr(X_train, 'columns'):
corrs = pd.Series(
[abs(np.corrcoef(X_train[c], y_train)[0,1]) for c in X_train.columns],
index=X_train.columns
).sort_values(ascending=False)
sospechosas = corrs[corrs > 0.9]
if not sospechosas.empty:
print(f"\n[ALERTA] Features con correlacion > 0.9 con el target:")
print(sospechosas)
return scores
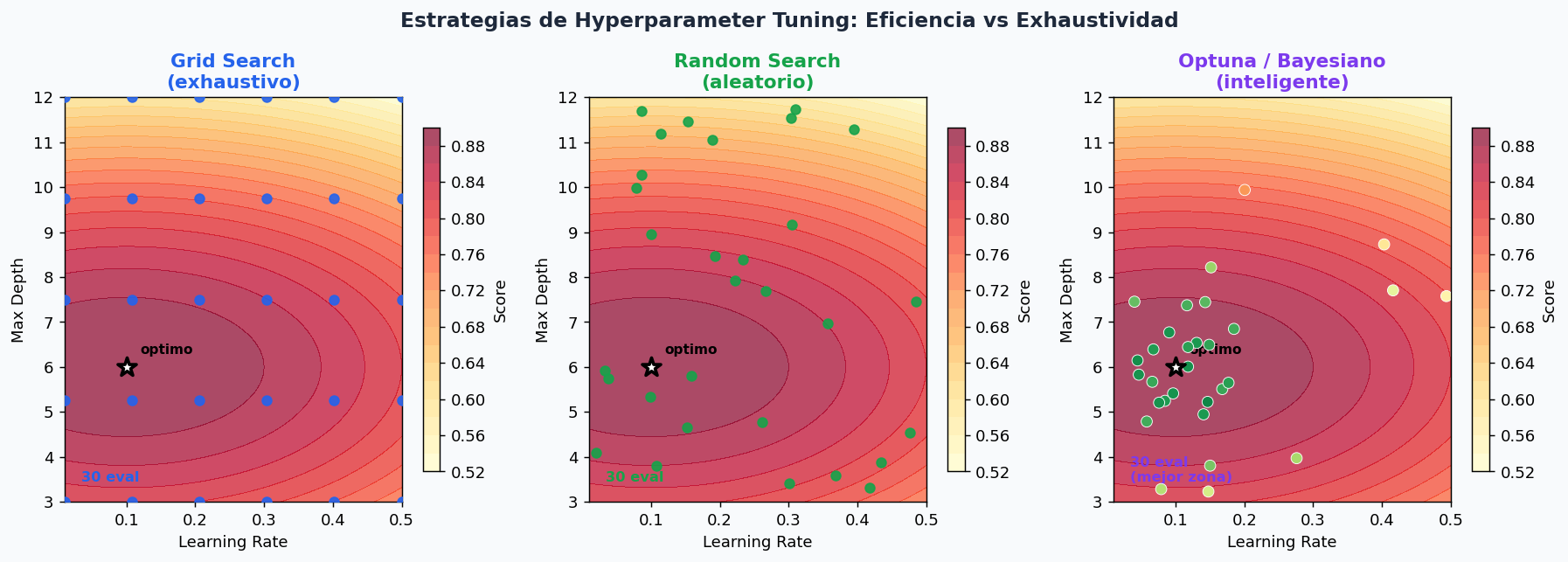
8. Hyperparameter Tuning eficiente
No hagas grid search ciego. La secuencia correcta: primero features, despues modelo, al final tuning.
import optuna
optuna.logging.set_verbosity(optuna.logging.WARNING)
from lightgbm import LGBMClassifier
from sklearn.model_selection import StratifiedKFold, cross_val_score
import numpy as np
def tune_lgbm_optuna(X_train, y_train, n_trials=50, cv_folds=5):
"""
Tuning bayesiano de LGBM con Optuna.
Mucho mas eficiente que GridSearch en espacios grandes.
"""
cv = StratifiedKFold(n_splits=cv_folds, shuffle=True, random_state=42)
def objective(trial):
params = {
"n_estimators": trial.suggest_int("n_estimators", 100, 1000),
"learning_rate": trial.suggest_float("learning_rate", 0.01, 0.3, log=True),
"num_leaves": trial.suggest_int("num_leaves", 15, 127),
"max_depth": trial.suggest_int("max_depth", 3, 10),
"min_child_samples": trial.suggest_int("min_child_samples", 5, 100),
"subsample": trial.suggest_float("subsample", 0.5, 1.0),
"colsample_bytree": trial.suggest_float("colsample_bytree", 0.5, 1.0),
"reg_alpha": trial.suggest_float("reg_alpha", 1e-4, 10.0, log=True),
"reg_lambda": trial.suggest_float("reg_lambda", 1e-4, 10.0, log=True),
"random_state": 42, "verbose": -1,
}
modelo = LGBMClassifier(**params)
scores = cross_val_score(modelo, X_train, y_train, cv=cv,
scoring="f1_macro", n_jobs=-1)
return scores.mean()
study = optuna.create_study(direction="maximize",
sampler=optuna.samplers.TPESampler(seed=42))
study.optimize(objective, n_trials=n_trials, show_progress_bar=True)
print(f"\nMejor CV F1: {study.best_value:.4f}")
print(f"Mejores params: {study.best_params}")
return study.best_params, study
# ── Alternativa: RandomizedSearchCV (sin instalar Optuna) ────────────────────
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint, uniform
def tune_lgbm_random(X_train, y_train, n_iter=50):
param_dist = {
"n_estimators": randint(100, 1000),
"learning_rate": uniform(0.01, 0.29),
"num_leaves": randint(15, 127),
"max_depth": randint(3, 10),
"min_child_samples": randint(5, 100),
"subsample": uniform(0.5, 0.5),
"colsample_bytree": uniform(0.5, 0.5),
}
modelo = LGBMClassifier(random_state=42, verbose=-1)
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
search = RandomizedSearchCV(
modelo, param_dist, n_iter=n_iter, cv=cv,
scoring="f1_macro", n_jobs=-1, random_state=42, refit=True,
)
search.fit(X_train, y_train)
print(f"Mejor CV F1: {search.best_score_:.4f}")
print(f"Mejores params: {search.best_params_}")
return search.best_estimator_, search
Dashboard resumen
Recursos recomendados
- Kaggle Learn — Feature Engineering: tecnicas practicas de transformacion de variables para datos tabulares
- Kaggle — Soluciones y write-ups de ganadores: aprende de los mejores consultando sus decisiones tecnicas justificadas
- Optuna — Documentacion oficial: tuning bayesiano eficiente, soporte nativo para sklearn, LightGBM y PyTorch
- MLflow — Getting Started: tracking de experimentos, parametros y modelos con una interfaz web local
- Weights & Biases: plataforma de seguimiento y visualizacion de experimentos con colaboracion en equipo
Navegacion
← 15. Embeddings y Transformers | 17. Etica y IA Responsable →