13. Redes Convolucionales (CNNs)
Por que las CNNs dominan la vision por computadora
Los MLPs densos tienen un problema fundamental con imagenes: si una imagen es de 224×224×3 pixeles, la primera capa necesitaria 224×224×3 = 150,528 pesos por neurona. Una capa de 1000 neuronas requeriria ~150 millones de parametros solo en la primera capa, sin contar que no aprovecha la estructura espacial de los datos.
Las Redes Convolucionales resuelven esto con tres ideas clave:
- Localidad: cada neurona mira solo una region pequena de la imagen (campo receptivo local)
- Comparticion de pesos: el mismo filtro se aplica en toda la imagen (invariancia traslacional)
- Jerarquia: capas tempranas detectan bordes, capas medias detectan formas, capas profundas detectan objetos completos
El resultado: mucho menos parametros, mucho mejor rendimiento en imagen.
1. Imagenes como tensores
Antes de entender las CNNs, es fundamental entender como se representa una imagen en memoria.
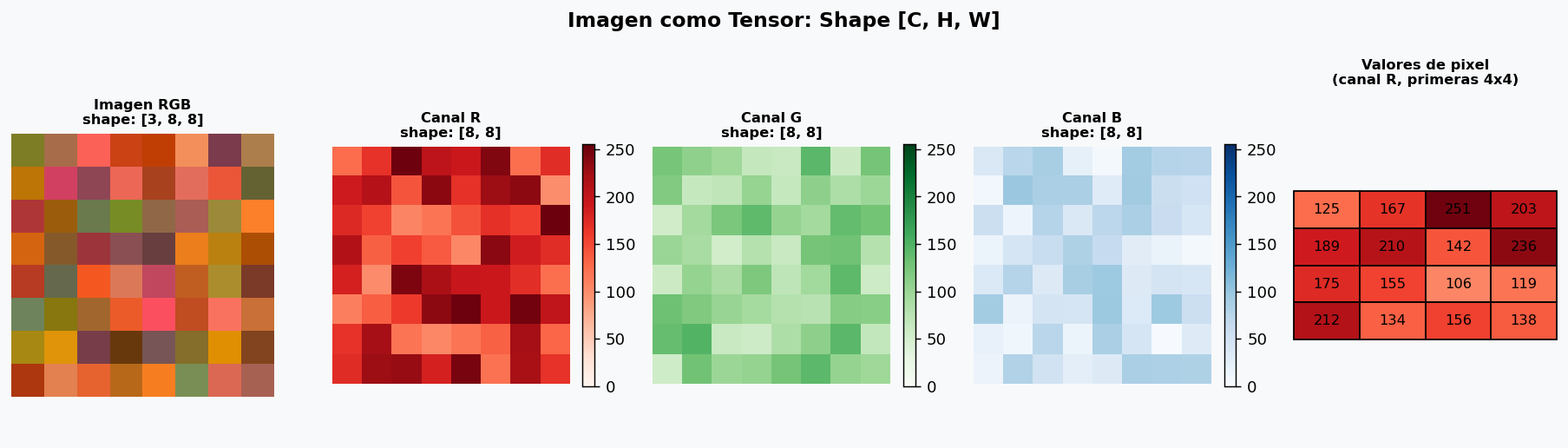
Una imagen de color tiene forma [C, H, W] en PyTorch (o [H, W, C] en NumPy/PIL):
- C: canales (3 para RGB, 1 para escala de grises)
- H: altura en pixeles
- W: ancho en pixeles
Un mini-batch de imagenes tiene forma [B, C, H, W] donde B es el batch size.
import torch
from PIL import Image
import numpy as np
# Abrir imagen y convertir a tensor
img_pil = Image.open("foto.jpg").convert("RGB")
img_np = np.array(img_pil) # shape: (H, W, 3), uint8, valores 0-255
img_t = torch.from_numpy(img_np) # shape: (H, W, 3)
# Transponer a formato PyTorch [C, H, W]
img_t = img_t.permute(2, 0, 1) # shape: (3, H, W)
# Normalizar a [0, 1] o con media/std de ImageNet
img_float = img_t.float() / 255.0
# Normalizacion ImageNet (SIEMPRE para transfer learning)
mean = torch.tensor([0.485, 0.456, 0.406]).view(3, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).view(3, 1, 1)
img_norm = (img_float - mean) / std
# Agregar dimension de batch: [1, C, H, W]
img_batch = img_norm.unsqueeze(0)
print(img_batch.shape) # torch.Size([1, 3, H, W])
Inspeccion de datos de imagen con torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# Transformaciones de preprocessing
transform_train = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
transform_val = transforms.Compose([
transforms.Resize((256, 256)),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# Dataset CIFAR-10 como ejemplo
train_ds = datasets.CIFAR10(root="data/", train=True, transform=transform_train, download=True)
val_ds = datasets.CIFAR10(root="data/", train=False, transform=transform_val, download=True)
train_loader = DataLoader(train_ds, batch_size=64, shuffle=True, num_workers=2)
val_loader = DataLoader(val_ds, batch_size=64, shuffle=False, num_workers=2)
# Verificar forma de un batch
X, y = next(iter(train_loader))
print(f"Batch shape: {X.shape}") # [64, 3, 32, 32]
print(f"Labels: {y[:8]}") # tensor([...])
print(f"Clases: {train_ds.classes}")
2. La operacion de convolucion
La convolución es el nucleo de las CNNs. Un kernel (filtro) de tamaño k×k se desliza sobre la imagen, calculando el producto punto entre el kernel y cada region de la imagen.
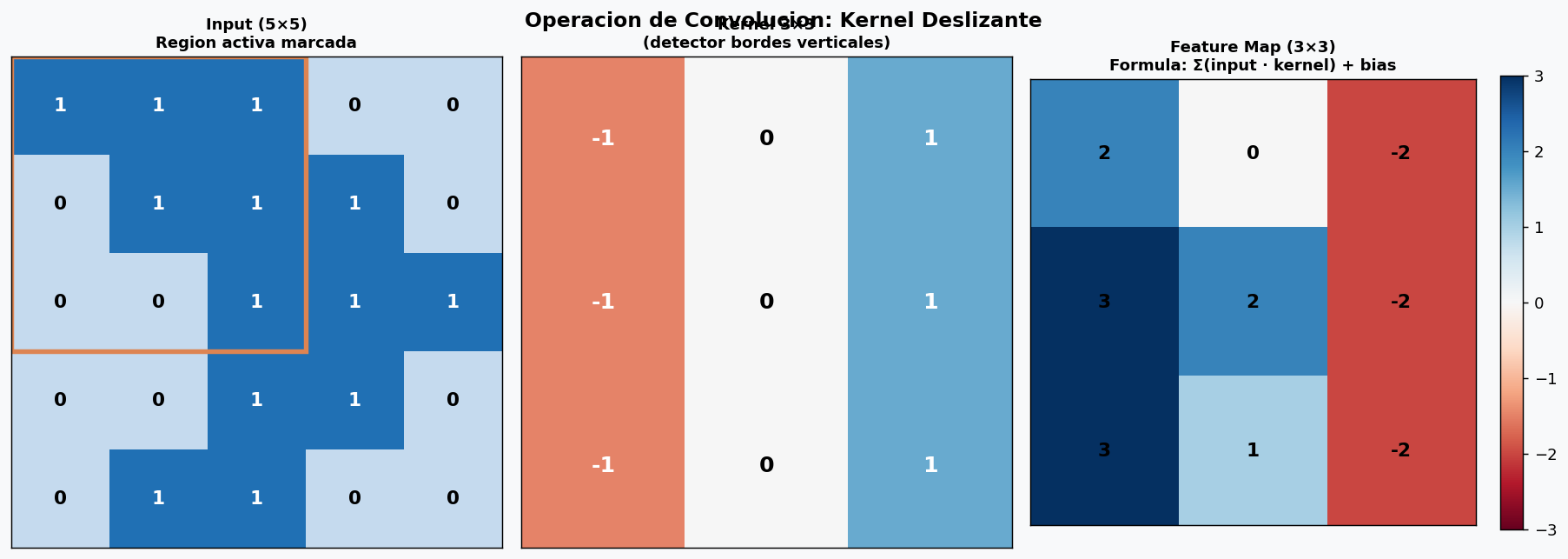
La matematica
Para una imagen I y kernel K de tamaño k×k:
El tamaño del feature map resultante con padding P y stride S es:
Padding “same” (P = k//2) preserva las dimensiones espaciales con stride=1.
import torch.nn as nn
# Ejemplos de capas convolucionales con diferentes configuraciones
conv_basica = nn.Conv2d(
in_channels=3, # canales de entrada (RGB)
out_channels=32, # numero de filtros (feature maps)
kernel_size=3, # tamano del kernel: 3×3
stride=1, # cuantos pixeles avanza el kernel
padding=1, # padding para mantener dimensiones
bias=True # sesgo por canal de salida
)
# Input: [B, 3, H, W]
# Output: [B, 32, H, W] (mismo H, W por padding=1)
# Calculo de parametros de esta capa:
# kernel: 3x3x3 (entrada) x 32 (filtros) = 864
# bias: 32
# Total: 896 parametros
# Convolucion 1x1: mezcla canales sin cambiar dimensiones espaciales
conv_1x1 = nn.Conv2d(256, 128, kernel_size=1) # reduce canales a la mitad
# Convolucion depthwise separable (MobileNet): mucho mas eficiente
depthwise = nn.Conv2d(32, 32, 3, groups=32, padding=1) # un filtro por canal
pointwise = nn.Conv2d(32, 64, 1) # mezcla canales
# Calcular output size manualmente
def conv_output_size(H_in, kernel, stride=1, padding=0):
return (H_in + 2*padding - kernel) // stride + 1
print(conv_output_size(32, kernel=3, stride=1, padding=1)) # 32 (same)
print(conv_output_size(32, kernel=3, stride=2, padding=1)) # 16 (reduce a mitad)
Que aprenden los filtros
Los kernels no se disenan a mano: la red los aprende. Pero es util saber que aprenden tipicamente:
- Capas tempranas: bordes horizontales, verticales, diagonales; texturas de baja frecuencia
- Capas medias: esquinas, curvas, patrones de textura mas complejos
- Capas profundas: partes de objetos (ruedas, ojos, ventanas), hasta objetos completos

3. Capas de Pooling
El pooling reduce las dimensiones espaciales del feature map, lo que:
- Disminuye el numero de parametros y computo en capas siguientes
- Introduce invariancia traslacional (el feature sigue detectandose aunque se mueva levemente)
- Aumenta el campo receptivo efectivo de capas posteriores
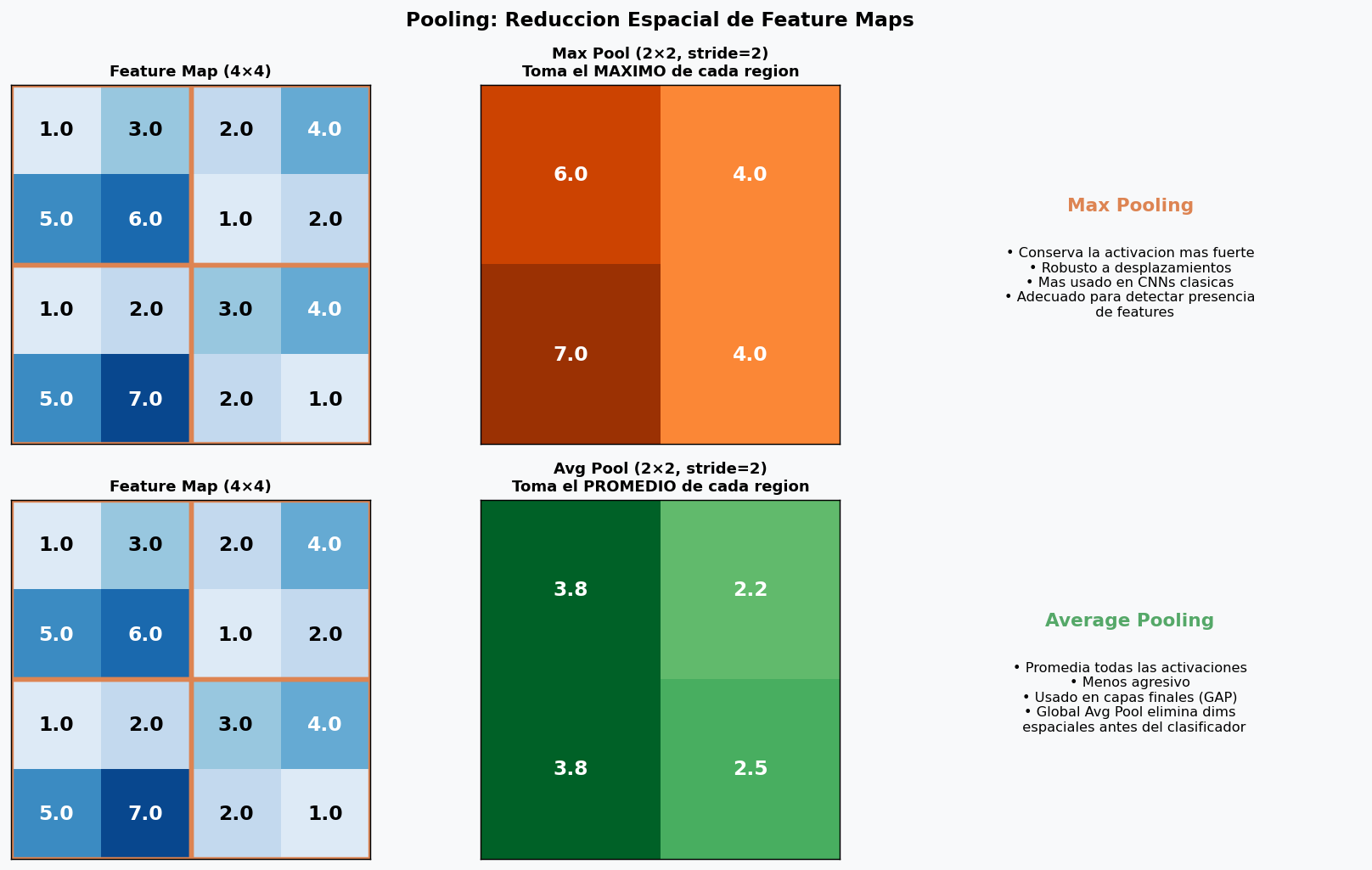
import torch.nn as nn
# MaxPool2d: toma el maximo en cada ventana (el mas comun en CNNs)
maxpool = nn.MaxPool2d(kernel_size=2, stride=2)
# Input: [B, C, H, W]
# Output: [B, C, H//2, W//2]
# AvgPool2d: promedia la ventana
avgpool = nn.AvgPool2d(kernel_size=2, stride=2)
# Global Average Pooling (GAP): colapsa toda la dimension espacial a 1x1
# Usado al final de CNNs modernas en vez de Flatten + FC grande
gap = nn.AdaptiveAvgPool2d(output_size=(1, 1))
# Input: [B, C, H, W] (cualquier H, W)
# Output: [B, C, 1, 1] → flatten → [B, C]
# Verificacion de shapes
import torch
x = torch.randn(4, 64, 28, 28)
print(maxpool(x).shape) # [4, 64, 14, 14]
print(gap(x).shape) # [4, 64, 1, 1]
print(gap(x).flatten(1).shape) # [4, 64]
4. Arquitectura CNN completa
Una CNN tipica alterna bloques de Conv+ReLU+BN con Pooling, y termina con capas densas para clasificacion.
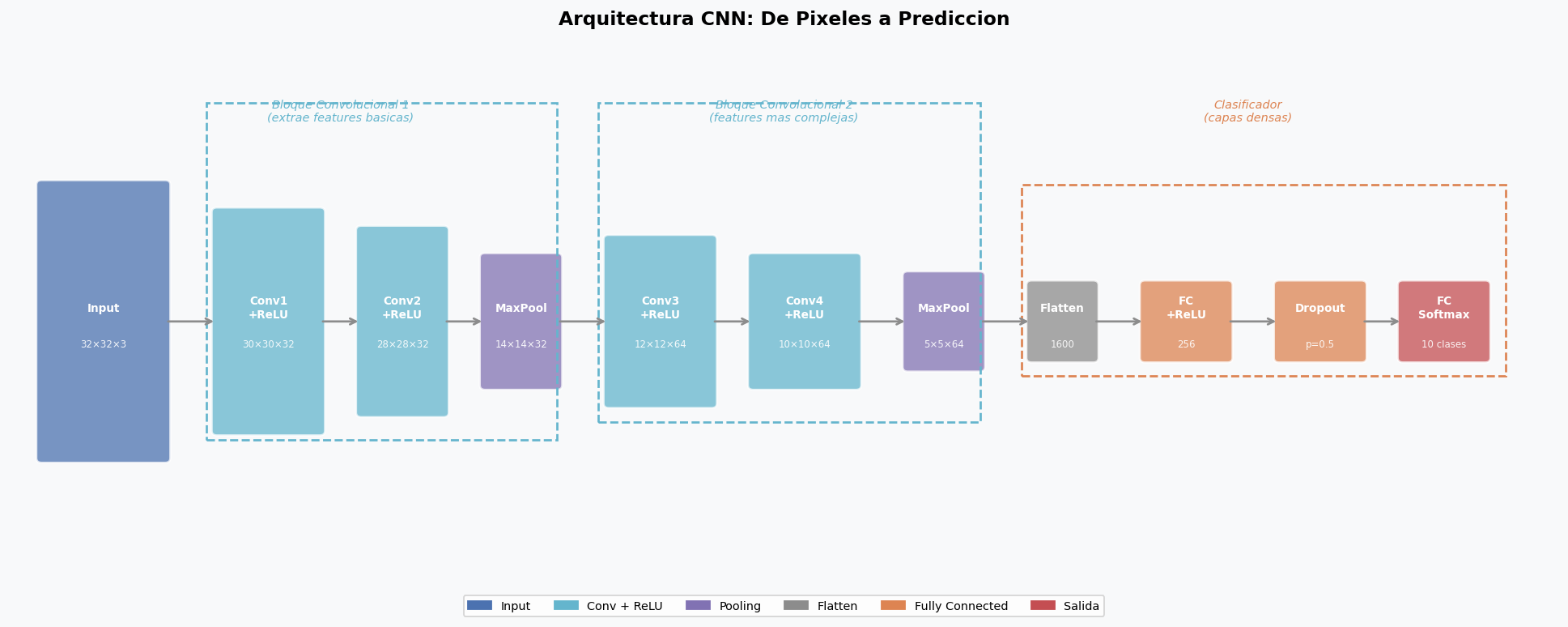
CNN desde cero para CIFAR-10
import torch
import torch.nn as nn
class CIFAR10CNN(nn.Module):
"""
CNN moderada para CIFAR-10 (10 clases, imagenes 32x32x3).
Sigue el patron: [Conv-BN-ReLU] x N → Pool → repeat → GAP → FC
"""
def __init__(self, num_classes=10, dropout_p=0.3):
super().__init__()
# Bloque 1: 3 → 64 canales, dimensiones 32x32 → 16x16
self.block1 = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(2), # 32x32 → 16x16
nn.Dropout2d(p=0.1), # Dropout espacial
)
# Bloque 2: 64 → 128 canales, dimensiones 16x16 → 8x8
self.block2 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(2), # 16x16 → 8x8
nn.Dropout2d(p=0.1),
)
# Bloque 3: 128 → 256 canales, dimensiones 8x8 → 4x4
self.block3 = nn.Sequential(
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(2), # 8x8 → 4x4
)
# Clasificador: GAP + FC
self.classifier = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)), # [B, 256, 4, 4] → [B, 256, 1, 1]
nn.Flatten(), # [B, 256]
nn.Linear(256, 128),
nn.ReLU(inplace=True),
nn.Dropout(p=dropout_p),
nn.Linear(128, num_classes),
)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
return self.classifier(x)
# Verificar shapes en cada bloque
model = CIFAR10CNN()
x = torch.randn(4, 3, 32, 32)
with torch.no_grad():
b1 = model.block1(x)
b2 = model.block2(b1)
b3 = model.block3(b2)
out = model.classifier(b3)
print(f"Input: {x.shape}") # [4, 3, 32, 32]
print(f"Block1: {b1.shape}") # [4, 64, 16, 16]
print(f"Block2: {b2.shape}") # [4, 128, 8, 8]
print(f"Block3: {b3.shape}") # [4, 256, 4, 4]
print(f"Output: {out.shape}") # [4, 10]
# Contar parametros
total = sum(p.numel() for p in model.parameters())
trainable = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Total params: {total:,}")
print(f"Trainable params: {trainable:,}")
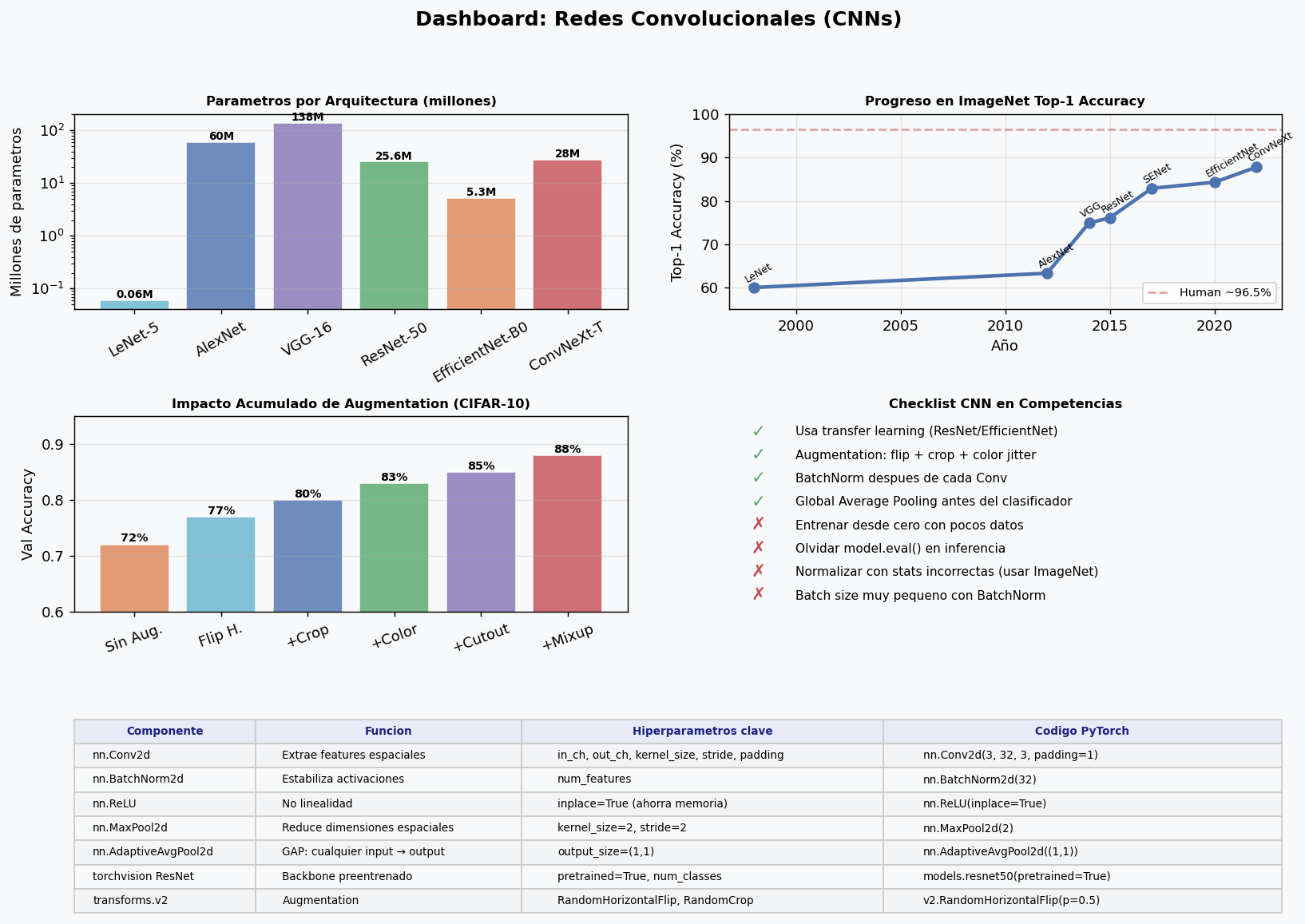
Arquitecturas clasicas (cronologia)
| Año | Arquitectura | Params | Top-1 ImageNet | Novedad clave |
|---|---|---|---|---|
| 1998 | LeNet-5 | 60K | — | Primera CNN practica |
| 2012 | AlexNet | 60M | 63.3% | ReLU, Dropout, GPU |
| 2014 | VGG-16 | 138M | 74.9% | Kernels 3×3 profundos |
| 2015 | ResNet-50 | 25M | 76.1% | Conexiones residuales (skip) |
| 2017 | SENet | 28M | 82.7% | Atencion de canales |
| 2019 | EfficientNet-B0 | 5.3M | 77.3% | Escalado compuesto |
| 2022 | ConvNeXt-T | 28M | 82.1% | CNN moderna tipo transformer |
5. ResNet: la arquitectura mas influyente
ResNet introdujo las conexiones residuales (skip connections), que permiten que el gradiente fluya directamente a capas anteriores, haciendo posible entrenar redes de 50, 101, 152 capas.
La idea es simple: en vez de aprender H(x), aprende F(x) = H(x) - x (el residuo):
import torch.nn as nn
class ResidualBlock(nn.Module):
"""Bloque residual basico de ResNet."""
def __init__(self, channels, stride=1):
super().__init__()
self.conv1 = nn.Conv2d(channels, channels, 3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(channels, channels, 3, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(channels)
# Skip connection: si stride > 1, necesita ajustar dimensiones
self.shortcut = nn.Sequential()
if stride != 1:
self.shortcut = nn.Sequential(
nn.Conv2d(channels, channels, 1, stride=stride, bias=False),
nn.BatchNorm2d(channels),
)
def forward(self, x):
out = self.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x) # sumar el residuo
return self.relu(out)
# Usar ResNet preentrenada de torchvision (la forma correcta en competencias)
import torchvision.models as models
resnet = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V2)
# Ver la arquitectura final
print(resnet.layer1) # 3 bloques residuales
print(resnet.fc) # Linear(2048, 1000)
6. Transfer Learning
La mayoria de problemas de vision en competencias tienen menos de 100k imagenes. Entrenar desde cero es sub-optimo. Transfer learning aprovecha pesos preentrenados en ImageNet (1.2M imagenes, 1000 clases).

Estrategia 1: Feature Extraction
Congela todos los pesos del backbone. Solo entrena el clasificador final. Ideal cuando:
- Dataset muy pequeno (< 1000 imagenes)
- Dominio similar a ImageNet (fotos naturales)
import torchvision.models as models
import torch.nn as nn
# Cargar ResNet50 preentrenada
backbone = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V2)
# Congelar TODOS los parametros
for param in backbone.parameters():
param.requires_grad = False
# Reemplazar el clasificador final por uno con nuestro numero de clases
in_features = backbone.fc.in_features # 2048 en ResNet50
backbone.fc = nn.Sequential(
nn.Dropout(p=0.3),
nn.Linear(in_features, 256),
nn.ReLU(),
nn.Linear(256, 10), # 10 clases CIFAR-10
)
# Solo los parametros del nuevo head son entrenables
trainable = sum(p.numel() for p in backbone.parameters() if p.requires_grad)
total = sum(p.numel() for p in backbone.parameters())
print(f"Trainable: {trainable:,} / {total:,} ({100*trainable/total:.1f}%)")
Estrategia 2: Fine-Tuning
Descongela las capas altas del backbone y las entrena con LR muy bajo. Mejor accuracy que feature extraction si tienes suficientes datos.
# Cargar modelo
model = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V2)
# Primero: feature extraction (entrenar solo el head)
for param in model.parameters():
param.requires_grad = False
in_features = model.fc.in_features
model.fc = nn.Linear(in_features, 10)
# Fase 1: entrenar solo el head (5-10 epocas)
optimizer_phase1 = torch.optim.AdamW(model.fc.parameters(), lr=1e-3)
# Fase 2: fine-tuning — descongelar layer3 y layer4
for param in model.layer3.parameters():
param.requires_grad = True
for param in model.layer4.parameters():
param.requires_grad = True
# LR diferencial: capas descongeladas con LR mucho menor que el head
optimizer_phase2 = torch.optim.AdamW([
{"params": model.layer3.parameters(), "lr": 1e-5}, # muy bajo
{"params": model.layer4.parameters(), "lr": 1e-5}, # muy bajo
{"params": model.fc.parameters(), "lr": 1e-3}, # normal
])
# Regla: LR del backbone = LR del head / 10 a / 100
Modelos preentrenados disponibles en torchvision
import torchvision.models as models
# Clasificacion de imagenes — ordenados por eficiencia
modelos = {
"ResNet-50": models.resnet50,
"EfficientNet-B0": models.efficientnet_b0, # excelente eficiencia
"EfficientNet-B4": models.efficientnet_b4, # mejor precision
"ConvNeXt-Tiny": models.convnext_tiny, # CNN moderna
"ViT-B/16": models.vit_b_16, # Vision Transformer
"Swin-T": models.swin_t, # Swin Transformer
}
# Cargar con pesos modernos
effnet = models.efficientnet_b0(
weights=models.EfficientNet_B0_Weights.IMAGENET1K_V1
)
# Inspeccionar el clasificador
print(effnet.classifier)
# Sequential: Dropout + Linear(1280, 1000)
# Reemplazar para nuestras clases
effnet.classifier = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(1280, 10),
)
7. Image Augmentation
Augmentation artificialmente agranda el dataset aplicando transformaciones aleatorias en cada epoch. La red ve “imagenes diferentes” en cada paso, lo que reduce overfitting.

from torchvision.transforms import v2
import torch
# Augmentation para entrenamiento (agresiva)
train_transform = v2.Compose([
v2.RandomResizedCrop(224, scale=(0.7, 1.0)), # recorte aleatorio
v2.RandomHorizontalFlip(p=0.5), # flip horizontal
v2.RandomVerticalFlip(p=0.1), # flip vertical (no siempre aplica)
v2.RandomRotation(degrees=15), # rotacion leve
v2.ColorJitter(
brightness=0.3, # variacion de brillo
contrast=0.3, # variacion de contraste
saturation=0.3, # variacion de saturacion
hue=0.1, # variacion de tono
),
v2.RandomGrayscale(p=0.05),
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True),
v2.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# Validacion: SOLO redimensionar y normalizar (SIN augmentation)
val_transform = v2.Compose([
v2.Resize(256),
v2.CenterCrop(224),
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True),
v2.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
Tecnicas avanzadas de augmentation
# Mixup: interpola dos imagenes y sus labels
def mixup(x, y, alpha=0.4):
lam = np.random.beta(alpha, alpha)
idx = torch.randperm(x.size(0))
x_mix = lam * x + (1 - lam) * x[idx]
y_a, y_b = y, y[idx]
return x_mix, y_a, y_b, lam
def mixup_criterion(criterion, pred, y_a, y_b, lam):
return lam * criterion(pred, y_a) + (1 - lam) * criterion(pred, y_b)
# CutMix: reemplaza una region de la imagen con otra imagen
def cutmix(x, y, alpha=1.0):
lam = np.random.beta(alpha, alpha)
rand_index = torch.randperm(x.size(0))
B, C, H, W = x.shape
cut_ratio = np.sqrt(1 - lam)
cut_h = int(H * cut_ratio)
cut_w = int(W * cut_ratio)
cx = np.random.randint(W)
cy = np.random.randint(H)
x1 = np.clip(cx - cut_w // 2, 0, W)
x2 = np.clip(cx + cut_w // 2, 0, W)
y1 = np.clip(cy - cut_h // 2, 0, H)
y2 = np.clip(cy + cut_h // 2, 0, H)
x_cutmix = x.clone()
x_cutmix[:, :, y1:y2, x1:x2] = x[rand_index, :, y1:y2, x1:x2]
lam_real = 1 - (x2-x1)*(y2-y1) / (H*W)
return x_cutmix, y, y[rand_index], lam_real
# Uso en el bucle de entrenamiento
USE_MIXUP = True
for X_b, y_b in train_loader:
optimizer.zero_grad()
if USE_MIXUP and np.random.rand() < 0.5:
X_b, y_a, y_b_mix, lam = mixup(X_b, y_b)
pred = model(X_b)
loss = mixup_criterion(criterion, pred, y_a, y_b_mix, lam)
else:
pred = model(X_b)
loss = criterion(pred, y_b)
loss.backward()
optimizer.step()
8. Pipeline completo: CIFAR-10 con Transfer Learning
import torch
import torch.nn as nn
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
import numpy as np
# ── Configuracion ─────────────────────────────────────────────────────────────
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
BATCH_SIZE = 64
N_EPOCHS = 30
LR = 1e-3
N_CLASSES = 10
# ── Datos ─────────────────────────────────────────────────────────────────────
train_tf = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, padding=4),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616)),
])
val_tf = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616)),
])
train_ds = datasets.CIFAR10("data/", train=True, transform=train_tf, download=True)
val_ds = datasets.CIFAR10("data/", train=False, transform=val_tf, download=True)
train_dl = DataLoader(train_ds, BATCH_SIZE, shuffle=True, num_workers=2, pin_memory=True)
val_dl = DataLoader(val_ds, BATCH_SIZE, shuffle=False, num_workers=2)
# ── Modelo: EfficientNet-B0 adaptado a CIFAR-10 ───────────────────────────────
model = models.efficientnet_b0(weights=models.EfficientNet_B0_Weights.IMAGENET1K_V1)
# Congelar backbone inicialmente
for param in model.features.parameters():
param.requires_grad = False
# Reemplazar clasificador
model.classifier = nn.Sequential(
nn.Dropout(p=0.3),
nn.Linear(1280, N_CLASSES),
)
model = model.to(DEVICE)
# ── Entrenamiento en 2 fases ──────────────────────────────────────────────────
def train_epoch(model, loader, optimizer, criterion):
model.train()
total_loss, correct, total = 0, 0, 0
for X, y in loader:
X, y = X.to(DEVICE), y.to(DEVICE)
optimizer.zero_grad()
pred = model(X)
loss = criterion(pred, y)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
total_loss += loss.item() * len(y)
correct += (pred.argmax(1) == y).sum().item()
total += len(y)
return total_loss/total, correct/total
@torch.no_grad()
def evaluate(model, loader, criterion):
model.eval()
total_loss, correct, total = 0, 0, 0
for X, y in loader:
X, y = X.to(DEVICE), y.to(DEVICE)
pred = model(X)
total_loss += criterion(pred, y).item() * len(y)
correct += (pred.argmax(1) == y).sum().item()
total += len(y)
return total_loss/total, correct/total
criterion = nn.CrossEntropyLoss(label_smoothing=0.1)
# FASE 1: entrenar solo el head (10 epocas)
print("=== Fase 1: Feature Extraction ===")
optimizer_p1 = torch.optim.AdamW(model.classifier.parameters(), lr=LR)
scheduler_p1 = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_p1, T_max=10)
best_val = 0
for ep in range(10):
tr_loss, tr_acc = train_epoch(model, train_dl, optimizer_p1, criterion)
vl_loss, vl_acc = evaluate(model, val_dl, criterion)
scheduler_p1.step()
if vl_acc > best_val:
best_val = vl_acc
torch.save(model.state_dict(), "cifar10_best.pt")
print(f"Ep {ep+1:2d} | tr={tr_acc:.3f} | val={vl_acc:.3f} | lr={scheduler_p1.get_last_lr()[0]:.2e}")
# FASE 2: fine-tuning — descongelar todo
print("\n=== Fase 2: Fine-Tuning ===")
for param in model.parameters():
param.requires_grad = True
optimizer_p2 = torch.optim.AdamW([
{"params": model.features.parameters(), "lr": 1e-5}, # backbone: LR muy bajo
{"params": model.classifier.parameters(), "lr": 1e-4}, # head: LR normal
], weight_decay=1e-2)
scheduler_p2 = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_p2, T_max=20)
for ep in range(20):
tr_loss, tr_acc = train_epoch(model, train_dl, optimizer_p2, criterion)
vl_loss, vl_acc = evaluate(model, val_dl, criterion)
scheduler_p2.step()
if vl_acc > best_val:
best_val = vl_acc
torch.save(model.state_dict(), "cifar10_best.pt")
print(f"Ep {ep+1:2d} | tr={tr_acc:.3f} | val={vl_acc:.3f}")
print(f"\nMejor val accuracy: {best_val:.4f}")
9. Analisis de errores y visualizacion
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
import seaborn as sns
CLASSES = ["airplane","automobile","bird","cat","deer",
"dog","frog","horse","ship","truck"]
@torch.no_grad()
def analizar_errores(model, loader, n_errores=16):
model.eval()
all_preds, all_labels, all_images = [], [], []
for X, y in loader:
X_dev = X.to(DEVICE)
preds = model(X_dev).argmax(1).cpu()
all_preds.append(preds)
all_labels.append(y)
all_images.append(X)
if len(all_preds)*loader.batch_size > 500:
break
preds = torch.cat(all_preds).numpy()
labels = torch.cat(all_labels).numpy()
images = torch.cat(all_images)
# ── 1. Matriz de confusion ───────────────────────────────────────────────
cm = confusion_matrix(labels, preds)
fig, ax = plt.subplots(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues",
xticklabels=CLASSES, yticklabels=CLASSES, ax=ax)
ax.set_title("Matriz de Confusion"); ax.set_xlabel("Prediccion"); ax.set_ylabel("Real")
plt.tight_layout(); plt.savefig("confusion_matrix.png", dpi=120); plt.show()
# ── 2. Imagenes mal clasificadas ─────────────────────────────────────────
wrong_idx = np.where(preds != labels)[0][:n_errores]
fig, axes = plt.subplots(4, 4, figsize=(10, 10))
mean = torch.tensor([0.4914, 0.4822, 0.4465]).view(3,1,1)
std = torch.tensor([0.2470, 0.2435, 0.2616]).view(3,1,1)
for ax, idx in zip(axes.flatten(), wrong_idx):
img = images[idx] * std + mean # desnormalizar
img = img.permute(1, 2, 0).clamp(0, 1).numpy()
ax.imshow(img)
ax.set_title(f"Real: {CLASSES[labels[idx]]}\nPred: {CLASSES[preds[idx]]}",
fontsize=7, color="red" if labels[idx] != preds[idx] else "green")
ax.axis("off")
plt.suptitle("Imagenes Mal Clasificadas")
plt.tight_layout(); plt.savefig("errores.png", dpi=120); plt.show()
# ── 3. Accuracy por clase ────────────────────────────────────────────────
acc_por_clase = {}
for i, cls in enumerate(CLASSES):
mask = labels == i
acc_por_clase[cls] = (preds[mask] == labels[mask]).mean()
print("\nAccuracy por clase:")
for cls, acc in sorted(acc_por_clase.items(), key=lambda x: x[1]):
bar = "█" * int(acc*20) + "░" * (20-int(acc*20))
print(f" {cls:12s}: {bar} {acc:.2%}")
Dashboard resumen
Recursos recomendados
- CS231n — Convolutional Neural Networks: la referencia mas completa sobre CNNs, con visualizaciones de convoluciones y pooling
- Tutorial de Transfer Learning en PyTorch: guia oficial paso a paso con ResNet en datos personalizados
- TorchVision — Modelos preentrenados: lista completa de modelos disponibles con pesos y metricas en ImageNet
- Papers With Code — Image Classification: estado del arte, benchmarks y codigo de los mejores modelos
- EfficientNet (Tan & Le, 2019): paper del modelo mas eficiente para competencias
Navegacion
← 12. Tecnicas de Entrenamiento en Deep Learning | 14. Fundamentos de NLP →