12. Tecnicas de Entrenamiento en Deep Learning
Por que el entrenamiento importa tanto como la arquitectura
En Deep Learning existe una trampa comun: creer que con una arquitectura mas grande o mas capas los resultados mejoran solos. La realidad es que una red identica entrenada con tecnicas diferentes puede tener diferencias de 10-20% en accuracy final, o no converger del todo.
Las tecnicas de entrenamiento responden preguntas criticas:
- Como actualizar los pesos de forma eficiente? → Optimizadores
- A que velocidad aprender y como ajustarla? → Learning rate scheduling
- Como evitar que la red memorice el train set? → Dropout y regularizacion
- Como estabilizar y acelerar el entrenamiento? → Batch Normalization
- Cuando parar de entrenar? → Early stopping
- Como comenzar con pesos razonables? → Inicializacion
- Como evitar gradientes que explotan? → Gradient clipping
Este tema te da las herramientas para diagnosticar problemas de entrenamiento y aplicar soluciones precisas, no al azar.
1. Optimizadores
Descenso de gradiente: la base de todo
Todo optimizador de redes neuronales es una variante del descenso de gradiente. La idea central: si conoces la direccion en que la funcion de perdida crece (el gradiente), muevete en la direccion opuesta.
Donde η es el learning rate y ∇L es el gradiente de la perdida respecto a los parametros.
La diferencia entre variantes es como se calcula ese paso de actualizacion.
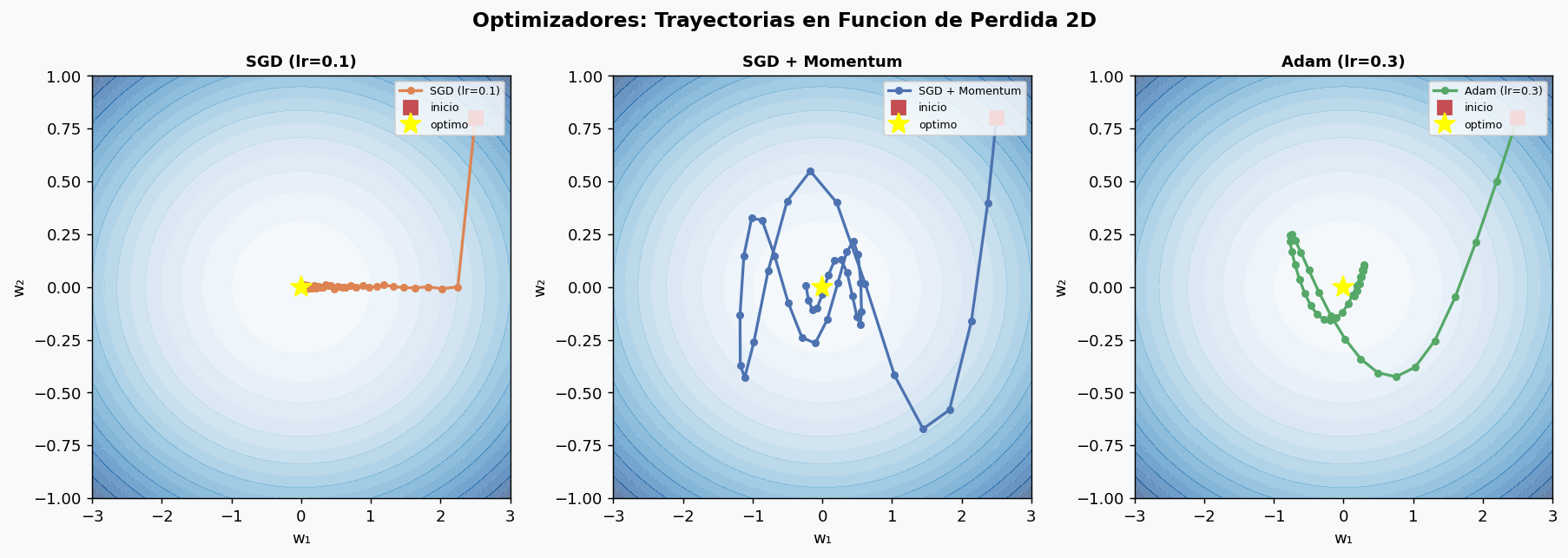
SGD puro y sus variantes
SGD (Stochastic Gradient Descent) calcula el gradiente sobre un mini-batch:
import torch
import torch.nn as nn
model = nn.Linear(10, 1)
# SGD puro
optimizer_sgd = torch.optim.SGD(model.parameters(), lr=0.01)
# SGD con momentum (mucho mejor)
optimizer_sgd_m = torch.optim.SGD(
model.parameters(),
lr=0.01,
momentum=0.9, # acumula gradientes pasados
weight_decay=1e-4 # L2 regularization
)
Momentum acumula un promedio exponencial de gradientes pasados, lo que suaviza la trayectoria y acelera en direcciones consistentes:
Con μ=0.9 (tipico), la actualizacion efectiva es ~10x el gradiente actual.
Adam: gradiente adaptativo por parametro
Adam (Adaptive Moment Estimation) mantiene tasas de aprendizaje individuales por parametro, basadas en estimaciones del primer y segundo momento del gradiente:
- m_t: media movil del gradiente (primer momento, “direccion”)
- v_t: media movil del gradiente al cuadrado (segundo momento, “magnitud”)
- β₁=0.9, β₂=0.999: hiperparametros estandar
- ε=1e-8: evita division por cero
# Adam: default moderno para la mayoria de problemas DL
optimizer_adam = torch.optim.Adam(
model.parameters(),
lr=1e-3,
betas=(0.9, 0.999),
eps=1e-8
)
# AdamW: Adam con weight decay desacoplado (RECOMENDADO)
# En Adam clasico, weight decay interactua mal con la normalizacion adaptativa
# AdamW los desacopla, lo que mejora regularizacion
optimizer_adamw = torch.optim.AdamW(
model.parameters(),
lr=1e-3,
weight_decay=1e-2 # regularizacion L2 desacoplada
)
Comparativa de optimizadores
| Optimizador | Velocidad de convergencia | Generalizacion | Cuando usar |
|---|---|---|---|
| SGD puro | Lenta | Excelente | Raramente (solo benchmarks) |
| SGD + Momentum | Moderada | Muy buena | Cuando quieres maxima generalizacion |
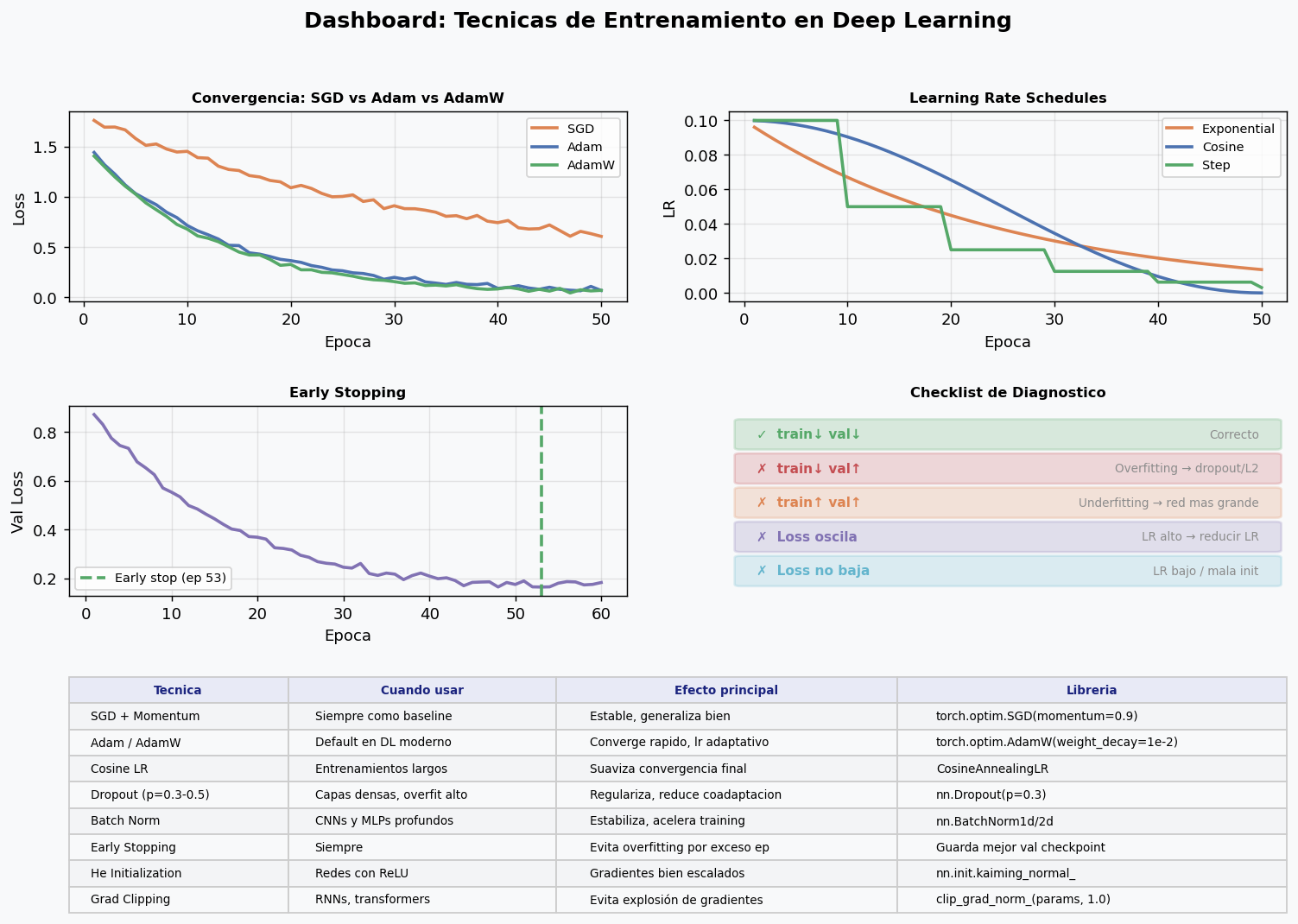
| Adam | Rapida | Buena | Default para experimentar |
| AdamW | Rapida | Muy buena | Default recomendado en produccion |
Regla practica: usa AdamW para experimentar rapido. Si necesitas exprimir el ultimo punto de accuracy, prueba SGD + momentum con LR schedule cuidadoso.
Bucle de entrenamiento completo con AdamW
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
# Datos de ejemplo
X = torch.randn(1000, 20)
y = (X[:, 0] + X[:, 1] > 0).float()
dataset = TensorDataset(X, y)
loader = DataLoader(dataset, batch_size=64, shuffle=True)
# Modelo
model = nn.Sequential(
nn.Linear(20, 128), nn.ReLU(),
nn.Linear(128, 64), nn.ReLU(),
nn.Linear(64, 1), nn.Sigmoid()
)
criterion = nn.BCELoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3, weight_decay=1e-2)
history = {"train_loss": [], "val_loss": []}
for epoch in range(50):
model.train()
batch_losses = []
for X_b, y_b in loader:
optimizer.zero_grad() # 1. Limpiar gradientes anteriores
pred = model(X_b).squeeze() # 2. Forward pass
loss = criterion(pred, y_b) # 3. Calcular perdida
loss.backward() # 4. Backpropagation
optimizer.step() # 5. Actualizar pesos
batch_losses.append(loss.item())
history["train_loss"].append(sum(batch_losses)/len(batch_losses))
print(f"Perdida final: {history['train_loss'][-1]:.4f}")
2. Learning Rate Scheduling
El learning rate es el hiperparametro mas critico del entrenamiento. Un LR fijo raramente es optimo: demasiado alto causa inestabilidad, demasiado bajo hace lento el aprendizaje.
Los schedulers adaptan el LR durante el entrenamiento.
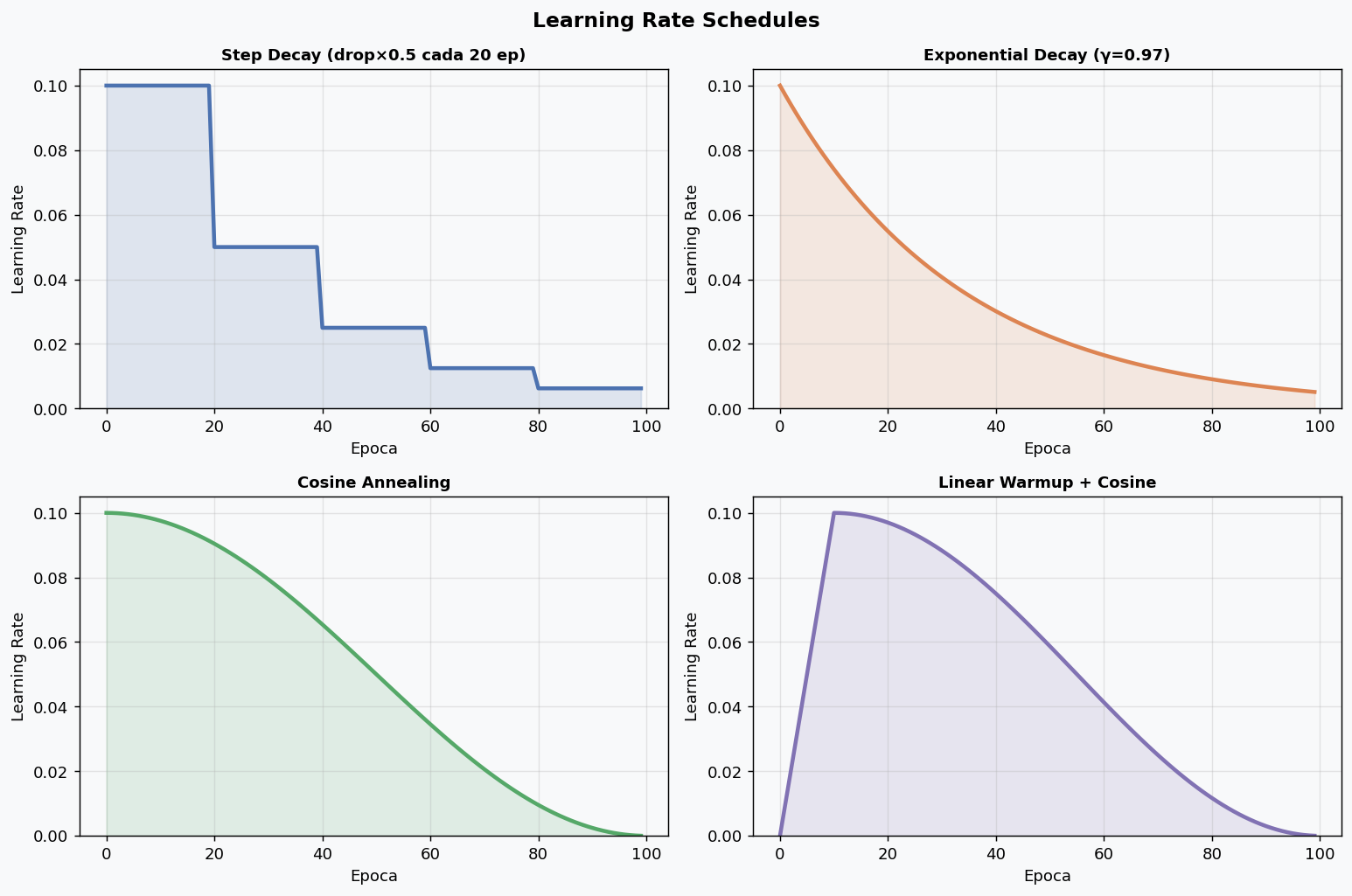
Tipos principales de schedulers
from torch.optim.lr_scheduler import (
StepLR, ExponentialLR, CosineAnnealingLR,
OneCycleLR, ReduceLROnPlateau
)
optimizer = torch.optim.AdamW(model.parameters(), lr=0.1)
# 1. Step Decay: reduce LR por factor cada N epocas
# Simple, predecible, funciona bien como baseline
scheduler_step = StepLR(optimizer, step_size=20, gamma=0.5)
# LR: 0.1 → 0.05 (ep 20) → 0.025 (ep 40) → ...
# 2. Exponential Decay: reduccion continua
scheduler_exp = ExponentialLR(optimizer, gamma=0.97)
# Cada epoca: LR *= 0.97
# 3. Cosine Annealing: suaviza convergencia final (MUY USADO)
scheduler_cos = CosineAnnealingLR(optimizer, T_max=100, eta_min=1e-6)
# 4. OneCycleLR: warmup + cosine en un ciclo (estado del arte)
scheduler_one = OneCycleLR(
optimizer,
max_lr=0.1,
steps_per_epoch=len(loader),
epochs=50,
pct_start=0.3, # 30% del tiempo en warmup
anneal_strategy="cos"
)
# 5. ReduceLROnPlateau: reduce LR cuando val_loss se estanca
scheduler_plateau = ReduceLROnPlateau(
optimizer,
mode="min",
factor=0.5,
patience=5,
verbose=True
)
# Como integrar en el bucle:
for epoch in range(n_epochs):
train_one_epoch(model, loader, optimizer)
val_loss = evaluate(model, val_loader)
# Para schedulers basados en metrica:
scheduler_plateau.step(val_loss)
# Para schedulers basados en epoca:
# scheduler_cos.step()
Linear Warmup: la clave en transformers
En modelos grandes (transformers, BERT), comenzar con LR alto es inestable. El warmup incrementa el LR linealmente durante las primeras N epocas:
from torch.optim.lr_scheduler import LinearLR, SequentialLR
# Warmup: LR va de 0 → lr_max en 10 epocas
warmup = LinearLR(optimizer, start_factor=0.01, end_factor=1.0, total_iters=10)
# Cosine despues del warmup
cosine = CosineAnnealingLR(optimizer, T_max=90, eta_min=1e-6)
# Combinar: warmup primero, luego cosine
scheduler = SequentialLR(optimizer, schedulers=[warmup, cosine], milestones=[10])
Regla practica: para CNNs usa cosine o step. Para transformers, siempre warmup + cosine.
3. Regularizacion: Dropout y Weight Decay
Dropout
Dropout “apaga” aleatoriamente neuronas durante el entrenamiento (las pone a 0 con probabilidad p). Esto fuerza a que la red no dependa de neuronas especificas y aprenda representaciones mas robustas.
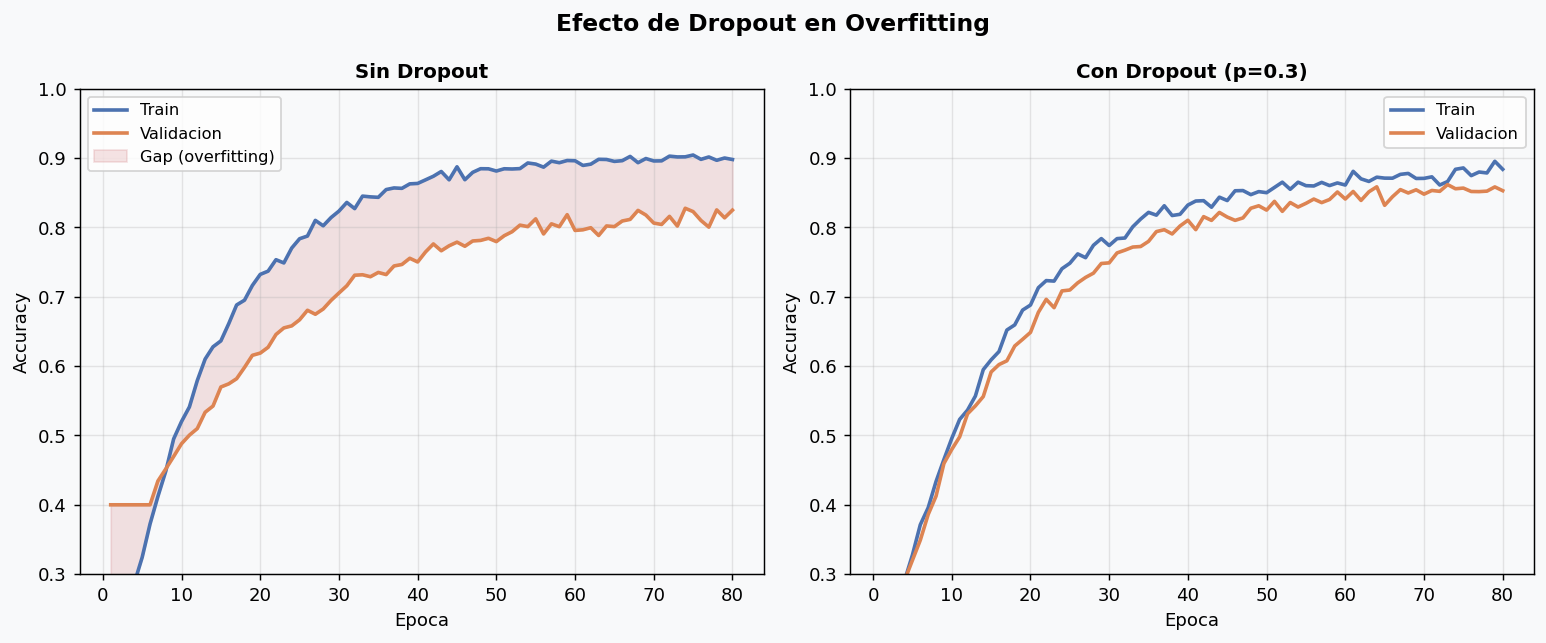
Durante inferencia, dropout se desactiva y todos los pesos se escalan por (1-p) para compensar.
import torch.nn as nn
# Modelo con dropout
class MLPConDropout(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, dropout_p=0.3):
super().__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Dropout(p=dropout_p), # apaga 30% de neuronas en train
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Dropout(p=dropout_p),
nn.Linear(hidden_dim, output_dim)
)
def forward(self, x):
return self.net(x)
model = MLPConDropout(20, 256, 10, dropout_p=0.4)
# IMPORTANTE: activar/desactivar dropout segun modo
model.train() # dropout activo
model.eval() # dropout desactivado (siempre para inferencia/evaluacion)
Guia de valores de p:
| Contexto | p recomendado |
|---|---|
| Capas densas en CNN | 0.3 – 0.5 |
| Transformers (attention dropout) | 0.1 |
| Redes pequeñas / datasets pequenos | 0.1 – 0.2 |
| Dropout espacial (CNNs, DropBlock) | 0.1 – 0.3 |
Truco de diagnostico: si accuracy de train baja mucho al agregar dropout pero val no mejora, el dropout es demasiado agresivo.
Weight Decay (L2 Regularization)
Penaliza pesos grandes añadiendo un termino a la perdida:
# En AdamW, weight_decay esta desacoplado (correcto)
optimizer = torch.optim.AdamW(
model.parameters(),
lr=1e-3,
weight_decay=1e-2 # λ = 0.01, tipico
)
# En SGD, se implementa igual pero es equivalente a L2 en este caso
optimizer_sgd = torch.optim.SGD(
model.parameters(),
lr=0.01,
momentum=0.9,
weight_decay=1e-4
)
4. Batch Normalization
Batch Normalization (BN) normaliza las activaciones de cada capa dentro de un mini-batch, manteniendolas con media ~0 y varianza ~1. Esto resuelve el problema de internal covariate shift: el cambio en la distribucion de activaciones a medida que los pesos se actualizan.
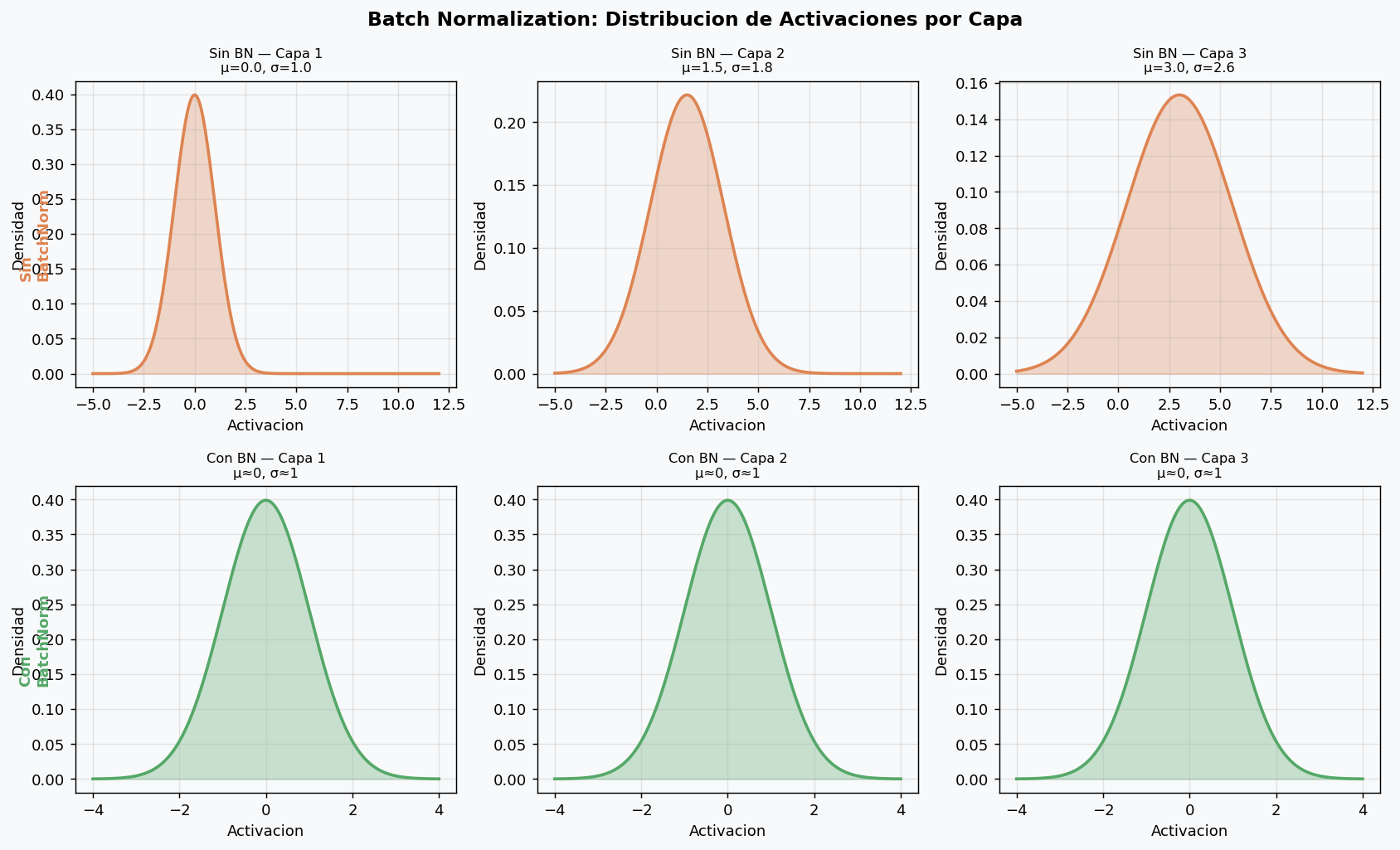
La matematica de BN
Para un mini-batch de activaciones {x₁, …, xₘ}:
γ y β son parametros aprendibles que permiten que la red “deshaga” la normalizacion si es necesario.
class MLPConBN(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.BatchNorm1d(hidden_dim), # ANTES de la activacion (debate: antes o despues)
nn.ReLU(),
nn.Dropout(p=0.2),
nn.Linear(hidden_dim, hidden_dim),
nn.BatchNorm1d(hidden_dim),
nn.ReLU(),
nn.Dropout(p=0.2),
nn.Linear(hidden_dim, output_dim)
)
def forward(self, x):
return self.net(x)
# Para CNNs: BatchNorm2d
cnn_block = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
)
Cuando usar BN:
- CNNs: casi siempre despues de cada convolucion
- MLPs profundos: si hay mas de 3-4 capas
- No usar con batch size < 8 (la estimacion de media/varianza es mala)
- Alternativa para batch sizes pequenos: Layer Normalization (usada en transformers)
5. Early Stopping
Entrenar demasiadas epocas lleva a overfitting. Early stopping monitorea la perdida de validacion y detiene el entrenamiento cuando deja de mejorar.
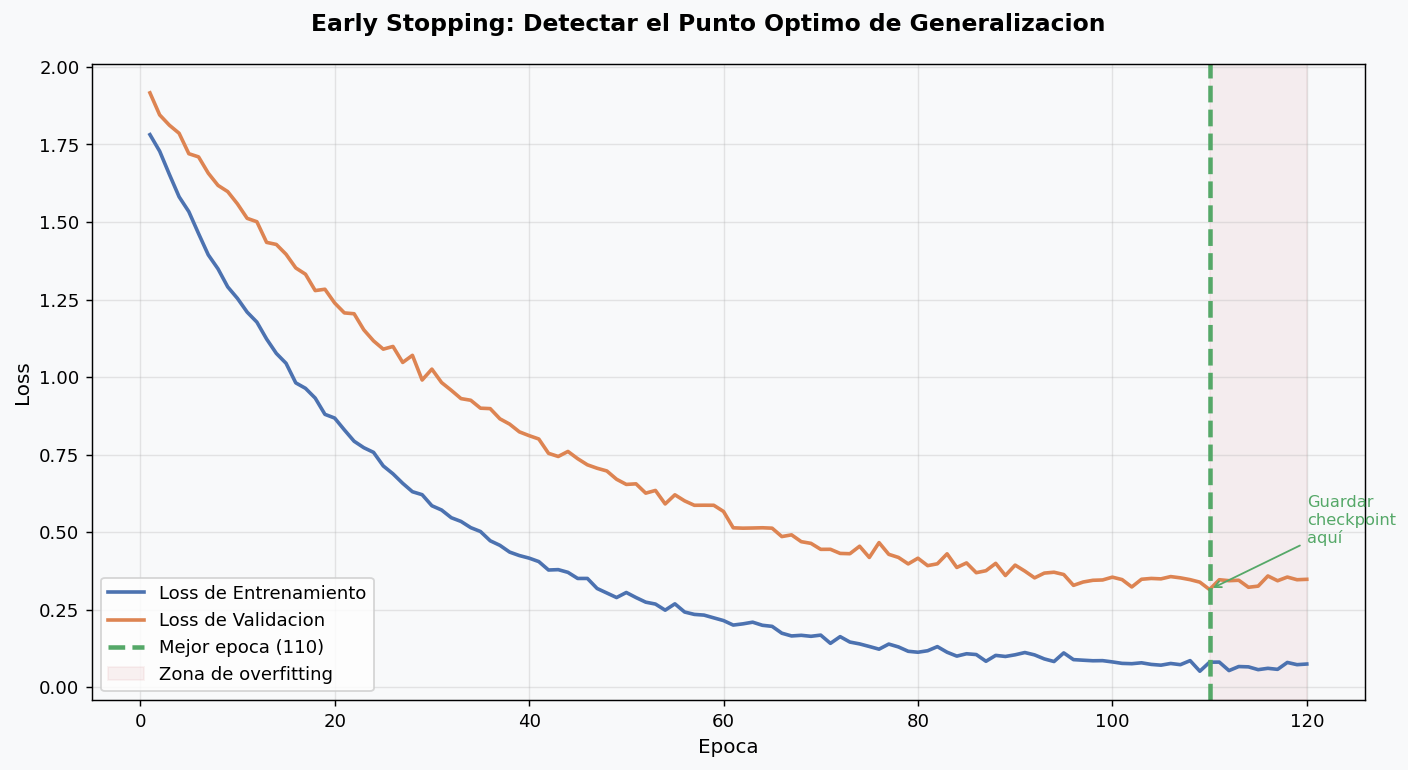
class EarlyStopping:
"""
Para entrenamiento cuando val_loss no mejora en `patience` epocas.
Guarda el mejor modelo automaticamente.
"""
def __init__(self, patience=10, min_delta=1e-4, path="best_model.pt"):
self.patience = patience
self.min_delta = min_delta
self.path = path
self.best_loss = float("inf")
self.counter = 0
self.stopped = False
def __call__(self, val_loss, model):
if val_loss < self.best_loss - self.min_delta:
self.best_loss = val_loss
self.counter = 0
torch.save(model.state_dict(), self.path) # guarda mejor checkpoint
else:
self.counter += 1
if self.counter >= self.patience:
self.stopped = True
# Uso en el bucle de entrenamiento
early_stop = EarlyStopping(patience=15, path="mejor_modelo.pt")
for epoch in range(200):
train_loss = train_epoch(model, train_loader, optimizer)
val_loss = evaluate(model, val_loader)
scheduler.step(val_loss) # opcional: ReduceLROnPlateau
early_stop(val_loss, model)
if early_stop.stopped:
print(f"Early stop en epoca {epoch+1}. Mejor val_loss: {early_stop.best_loss:.4f}")
break
# Cargar el mejor checkpoint al final
model.load_state_dict(torch.load("mejor_modelo.pt"))
Regla practica: patience=10-20 epocas suele ser adecuado. Con LR scheduling, patience puede ser mayor porque el LR puede bajar antes de que mejore.
6. Inicializacion de pesos
Si los pesos iniciales son muy grandes, las activaciones saturan desde el inicio. Si son muy pequenos, los gradientes desaparecen. Una buena inicializacion es critica para que la red empiece a aprender desde el principio.
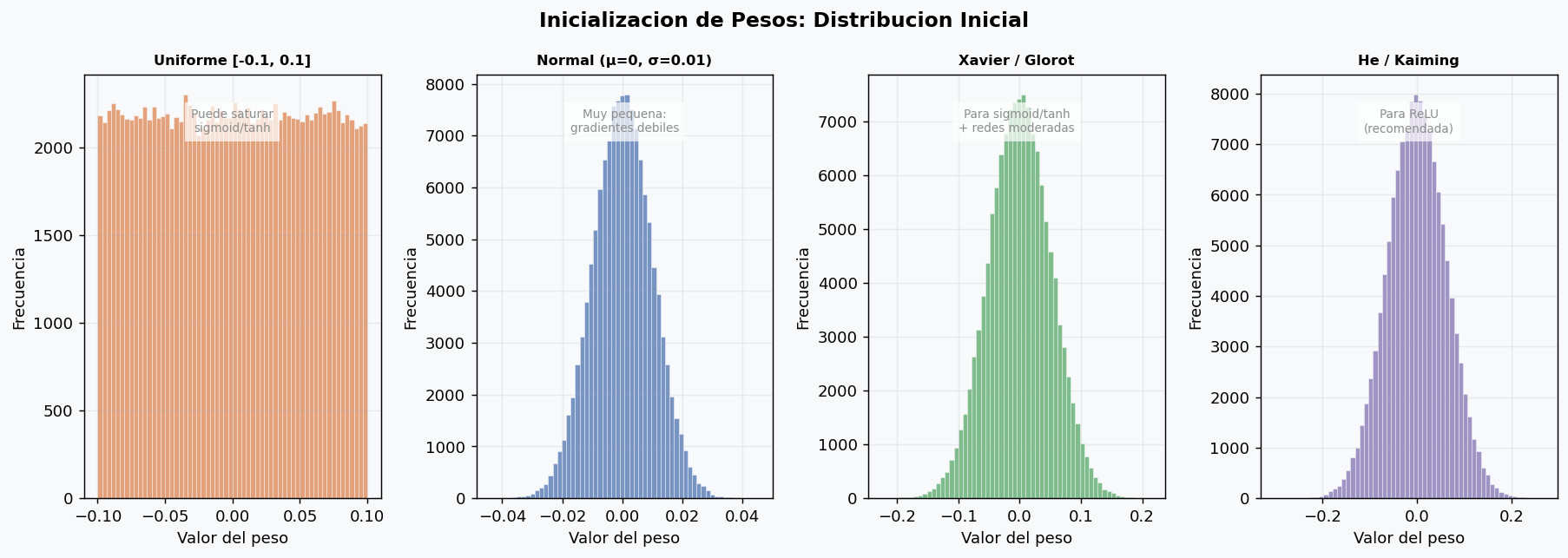
Xavier / Glorot: para sigmoid y tanh
Diseñada para mantener la varianza de activaciones y gradientes constante a traves de capas:
He / Kaiming: para ReLU
ReLU descarta la mitad de las neuronas (las negativas), por lo que necesita mas varianza inicial:
import torch.nn as nn
def init_weights(module):
if isinstance(module, nn.Linear):
# He (Kaiming): para activaciones ReLU
nn.init.kaiming_normal_(module.weight, mode="fan_in", nonlinearity="relu")
nn.init.zeros_(module.bias)
elif isinstance(module, nn.Conv2d):
nn.init.kaiming_normal_(module.weight, mode="fan_out", nonlinearity="relu")
if module.bias is not None:
nn.init.zeros_(module.bias)
elif isinstance(module, nn.BatchNorm1d) or isinstance(module, nn.BatchNorm2d):
nn.init.ones_(module.weight) # gamma = 1
nn.init.zeros_(module.bias) # beta = 0
# Aplicar inicializacion al modelo
model = MLPConBN(20, 256, 10)
model.apply(init_weights)
# Verificar: las activaciones iniciales deben tener varianza ~1
with torch.no_grad():
x = torch.randn(64, 20)
h = model.net[:3](x) # salida de primera capa + BN + ReLU
print(f"Media: {h.mean():.3f}, Std: {h.std():.3f}") # esperar: ~0, ~1
Regla rapida:
| Activacion | Inicializacion recomendada |
|---|---|
| ReLU, Leaky ReLU | He (Kaiming) normal |
| Sigmoid, Tanh | Xavier (Glorot) |
| Ninguna (salida lineal) | Xavier o He segun contexto |
| Transformers | Normal(0, 0.02) tipicamente |
7. Gradient Clipping
En RNNs, LSTMs y transformers, los gradientes pueden crecer exponencialmente (problema de gradientes explosivos), causando que los pesos se actualicen con pasos enormes y desestabilicen el entrenamiento.
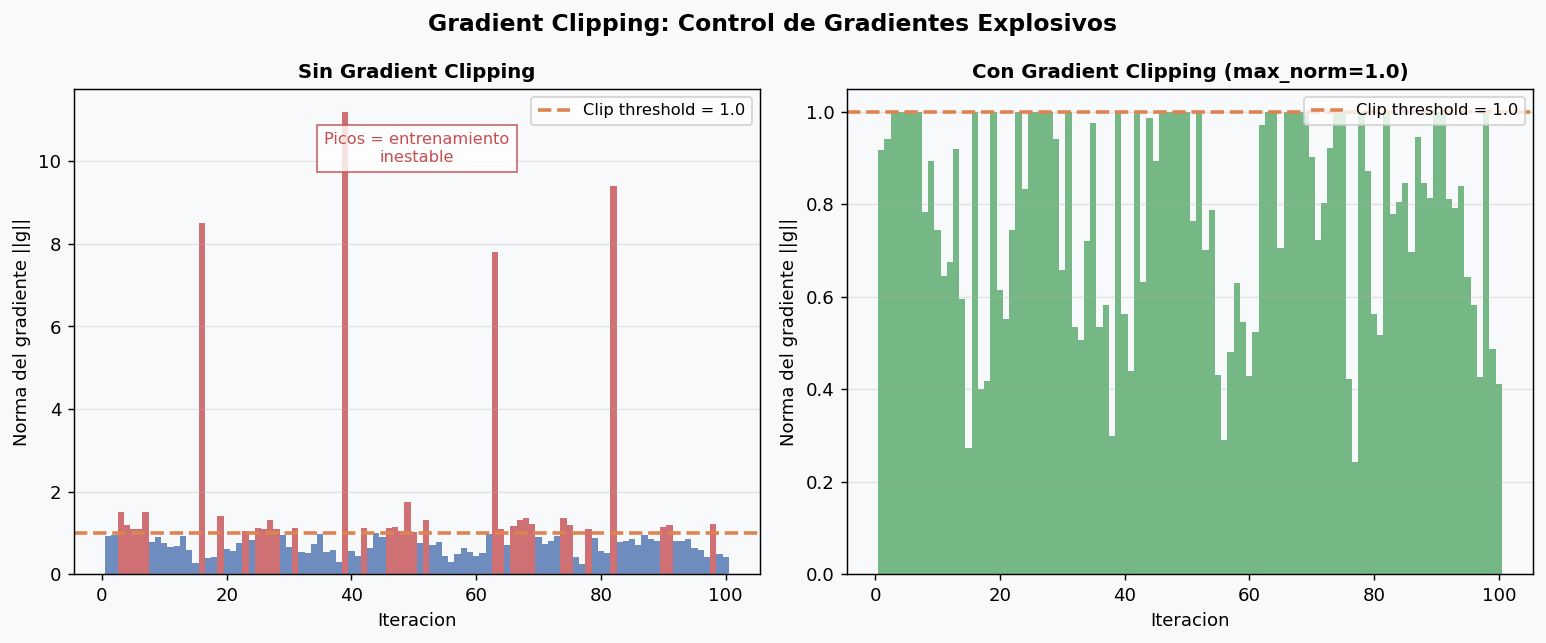
Gradient clipping limita la norma L2 del vector de gradientes:
for epoch in range(n_epochs):
for X_b, y_b in loader:
optimizer.zero_grad()
loss = criterion(model(X_b), y_b)
loss.backward()
# Aplicar gradient clipping ANTES de optimizer.step()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
# Monitorear norma de gradientes (util para diagnostico)
def get_grad_norm(model):
total_norm = 0
for p in model.parameters():
if p.grad is not None:
total_norm += p.grad.data.norm(2).item() ** 2
return total_norm ** 0.5
# En el bucle:
grad_norm = get_grad_norm(model)
print(f"Norma del gradiente: {grad_norm:.4f}")
Cuando usar: siempre en RNNs/LSTMs. En CNNs y MLPs es menos critico pero no hace daño. En transformers, max_norm=1.0 es el valor estandar.
8. Diagnostico de problemas de entrenamiento
Saber que tecnica aplicar requiere primero identificar el problema. Las curvas de entrenamiento son tu principal herramienta de diagnostico.
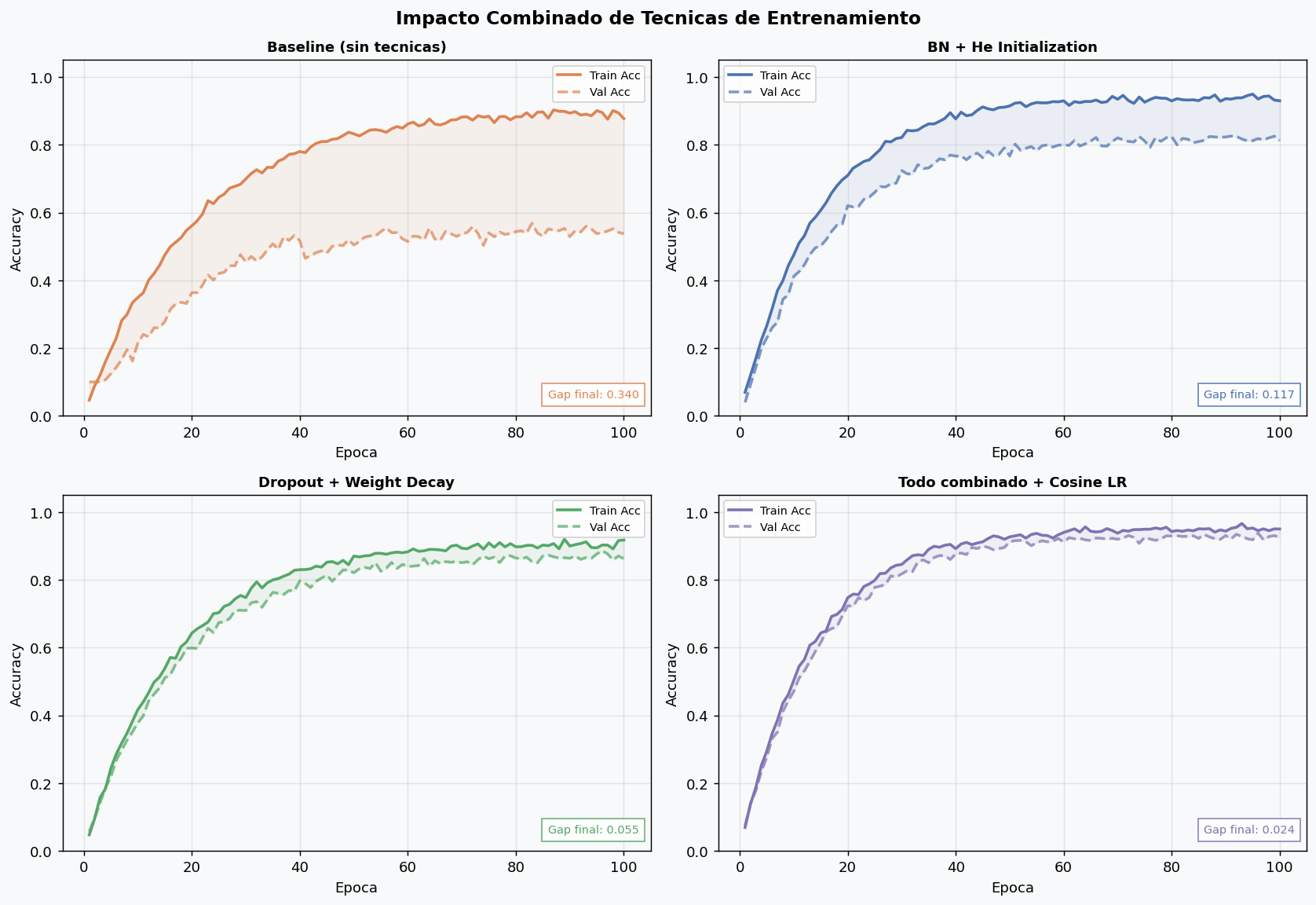
El mapa de diagnostico
Curva train Curva validacion Diagnostico Solucion
────────────── ───────────────── ──────────────────── ─────────────────────
↓ baja ↓ baja Entrenamiento correcto Seguir o afinar
↓ baja ↑ sube Overfitting Dropout / weight decay / menos epocas
↑ alta ↑ alta Underfitting Red mas grande / mas epocas / mejor LR
↕ oscila ↕ oscila LR muy alto Bajar LR / gradient clipping
→ plana rapido → plana rapido LR muy bajo Subir LR / cambiar scheduler
↓ muy lenta ↓ muy lenta Mala inicializacion He/Xavier / revisar BN
import matplotlib.pyplot as plt
def diagnostico_entrenamiento(history):
"""
Grafica curvas de entrenamiento y muestra diagnostico automatico.
history: dict con listas "train_loss" y "val_loss"
"""
train = history["train_loss"]
val = history["val_loss"]
ep = range(1, len(train)+1)
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
# Curvas de perdida
axes[0].plot(ep, train, label="Train", color="#4C72B0")
axes[0].plot(ep, val, label="Val", color="#DD8452")
axes[0].set_title("Curvas de Perdida")
axes[0].set_xlabel("Epoca")
axes[0].set_ylabel("Loss")
axes[0].legend()
# Gap train-val (diagnostico de overfitting)
gap = [t - v for t, v in zip(train, val)]
axes[1].plot(ep, gap, color="#C44E52")
axes[1].axhline(0, ls="--", color="gray", alpha=0.5)
axes[1].fill_between(ep, gap, 0,
where=[g > 0 for g in gap],
alpha=0.2, color="#C44E52", label="Overfitting")
axes[1].fill_between(ep, gap, 0,
where=[g <= 0 for g in gap],
alpha=0.2, color="#55A868", label="Underfitting")
axes[1].set_title("Gap Train - Val (positivo = overfitting)")
axes[1].set_xlabel("Epoca")
axes[1].set_ylabel("Train Loss - Val Loss")
axes[1].legend()
plt.tight_layout()
plt.savefig("diagnostico.png", dpi=120, bbox_inches="tight")
plt.show()
# Diagnostico automatico simple
final_gap = train[-1] - val[-1]
if val[-1] > val[max(0, len(val)-10)]:
print("ALERTA: val loss aumenta en las ultimas epocas → posible overfitting")
elif final_gap > 0.1:
print(f"ALERTA: gap train-val = {final_gap:.3f} → considera mas regularizacion")
else:
print(f"OK: gap train-val = {final_gap:.3f}, entrenamiento estable")
9. Receta completa de entrenamiento
Integrando todo en un pipeline reproducible:
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
def entrenar_modelo(
model, train_loader, val_loader,
n_epochs=100,
lr=1e-3,
weight_decay=1e-2,
patience=15,
clip_norm=1.0,
device="cpu"
):
"""
Bucle de entrenamiento completo con:
- AdamW + Cosine LR Scheduler
- Gradient Clipping
- Early Stopping con checkpoint del mejor modelo
- Registro de historial
"""
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(
model.parameters(), lr=lr, weight_decay=weight_decay
)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
optimizer, T_max=n_epochs, eta_min=lr*0.01
)
early_stop = EarlyStopping(patience=patience, path="checkpoint.pt")
history = {"train_loss": [], "val_loss": [], "lr": []}
for epoch in range(n_epochs):
# ── Entrenamiento ──────────────────────────────────────────
model.train()
train_losses = []
for X_b, y_b in train_loader:
X_b, y_b = X_b.to(device), y_b.to(device)
optimizer.zero_grad()
loss = criterion(model(X_b), y_b)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip_norm)
optimizer.step()
train_losses.append(loss.item())
# ── Validacion ─────────────────────────────────────────────
model.eval()
val_losses = []
with torch.no_grad():
for X_b, y_b in val_loader:
X_b, y_b = X_b.to(device), y_b.to(device)
val_losses.append(criterion(model(X_b), y_b).item())
train_loss = sum(train_losses) / len(train_losses)
val_loss = sum(val_losses) / len(val_losses)
current_lr = optimizer.param_groups[0]["lr"]
history["train_loss"].append(train_loss)
history["val_loss"].append(val_loss)
history["lr"].append(current_lr)
scheduler.step()
early_stop(val_loss, model)
if (epoch + 1) % 10 == 0:
print(f"Ep {epoch+1:3d} | train={train_loss:.4f} | val={val_loss:.4f} | lr={current_lr:.2e}")
if early_stop.stopped:
print(f"\nEarly stop en epoca {epoch+1}")
break
# Restaurar el mejor modelo
model.load_state_dict(torch.load("checkpoint.pt"))
return model, history
Dashboard resumen
Recursos recomendados
- CS231n — Notas de entrenamiento de redes: guia detallada sobre optimizacion, diagnostico de curvas y ajuste de hiperparametros
- Documentacion de optimizadores PyTorch: referencia completa de SGD, Adam, AdamW y todos los schedulers
- Batch Normalization (Ioffe & Szegedy, 2015): el paper original que introdujo BN — lectura obligatoria
- Dropout (Srivastava et al., 2014): paper original de dropout con analisis teorico y empirico
- Decoupled Weight Decay (AdamW): por que AdamW supera a Adam regularizado con L2
Navegacion
← 11. Fundamentos de PyTorch | 13. Redes Convolucionales (CNNs) →