11. Fundamentos de PyTorch
Por que PyTorch es el framework de referencia
PyTorch es el framework de deep learning mas usado en investigacion y es parte del temario oficial de la IOAI (International Olympiad in Artificial Intelligence). Su diseno de grafos computacionales dinamicos (define-by-run) lo hace mas intuitivo que los frameworks de grafo estatico: el codigo Python es el modelo, y puedes usar print, pdb, e if/for normalmente dentro del forward pass.
Ademas, PyTorch es la base de Hugging Face Transformers, Lightning, Detectron2, y practicamente todo el ecosistema moderno de DL. Invertir tiempo en dominarlo a fondo paga dividendos en todos los temas siguientes.
1. Tensores: la estructura de datos fundamental
Un tensor es la generalizacion de un array multidimensional. Es el equivalente en PyTorch de np.ndarray, pero con capacidades adicionales: puede vivir en GPU y puede rastrear gradientes.
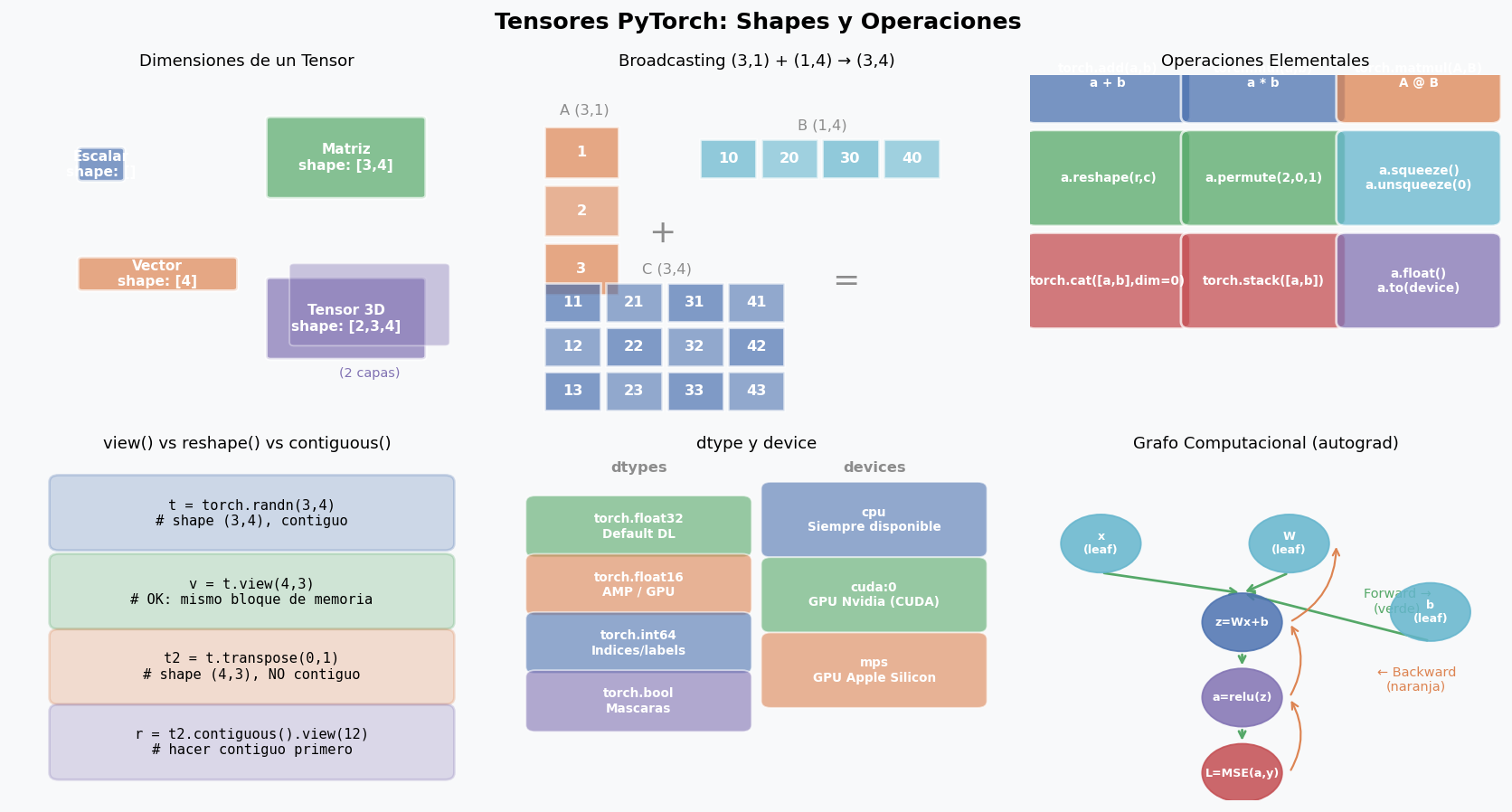
Creacion de tensores
import torch
import numpy as np
# Desde datos Python/NumPy
t1 = torch.tensor([1.0, 2.0, 3.0]) # shape [3], float32
t2 = torch.tensor([[1, 2], [3, 4]]) # shape [2,2], int64
t3 = torch.from_numpy(np.random.randn(4, 5)) # comparte memoria con NumPy
# Tensores especiales
zeros = torch.zeros(3, 4) # todo ceros
ones = torch.ones(2, 3) # todo unos
eye = torch.eye(5) # identidad
rand = torch.rand(3, 4) # uniforme [0,1)
randn = torch.randn(3, 4) # normal N(0,1)
arange = torch.arange(0, 10, 2) # [0,2,4,6,8]
linsp = torch.linspace(0, 1, 5) # [0.0, 0.25, 0.5, 0.75, 1.0]
# Como cierto tensor existente (mismos shape y dtype)
like_zeros = torch.zeros_like(t2.float())
like_rand = torch.rand_like(t2.float())
print(t1.shape) # torch.Size([3])
print(t2.dtype) # torch.int64
print(t3.device) # device(type='cpu')
Operaciones clave
A = torch.randn(3, 4)
B = torch.randn(4, 5)
# Operaciones elementales (broadcast automatico)
C = A + 1.0 # suma escalar
D = A * 2.0 # producto escalar
E = A + A # suma elemento a elemento
# Producto matricial
F = A @ B # shape (3, 5) — equivalente a torch.matmul(A, B)
G = torch.matmul(A, B)
# Reduccion
total = A.sum()
fila = A.sum(dim=1) # suma por filas → shape (3,)
media = A.mean(dim=0) # media por columnas → shape (4,)
maximo = A.max()
idx = A.argmax(dim=1) # indice del maximo por fila
# Reshape y reindexacion
t = torch.arange(24)
r = t.view(2, 3, 4) # reshape (comparte memoria)
r2 = t.reshape(4, 6) # reshape seguro
r3 = r.permute(2, 0, 1) # transponer ejes: (2,3,4) → (4,2,3)
r4 = r.unsqueeze(0) # agregar dim: (2,3,4) → (1,2,3,4)
r5 = r4.squeeze(0) # eliminar dim de tamano 1
# Indexacion
fila0 = r[0] # primer "batch"
cols = r[:, :, 1:3] # columnas 1 y 2
mascara = A > 0 # tensor bool
pos = A[mascara] # elementos positivos
# Concatenacion
cat_0 = torch.cat([A, A], dim=0) # apilar en dim 0: (6,4)
cat_1 = torch.cat([A, A], dim=1) # apilar en dim 1: (3,8)
stk = torch.stack([A, A], dim=0) # nueva dim: (2,3,4)
dtype y device
# Tipos comunes
x_float32 = torch.randn(3, 4) # default DL
x_float16 = x_float32.half() # AMP / ahorro memoria GPU
x_int64 = torch.arange(10) # indices, labels
x_bool = x_float32 > 0 # mascaras
# Conversion de device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
x_gpu = x_float32.to(device) # mover a GPU
x_cpu = x_gpu.cpu() # volver a CPU
# IMPORTANTE: numpy() solo funciona en tensores CPU
arr = x_cpu.numpy() # comparte memoria — NO copiar
arr2 = x_cpu.detach().numpy() # si tiene requires_grad
# Conversion de dtype
x64 = x_float32.double() # float64
x32 = x64.float() # float32
xi = x64.long() # int64
Broadcasting: operaciones entre shapes distintas
# Broadcasting sigue las reglas de NumPy:
# 1. Se alinean shapes desde la derecha
# 2. Las dims de tamano 1 se "expanden" para coincidir
A = torch.randn(3, 1) # shape (3, 1)
B = torch.randn(1, 4) # shape (1, 4)
C = A + B # shape (3, 4) — NO se copia memoria
# Casos utiles en DL
# Normalizar cada feature:
X = torch.randn(100, 32) # 100 muestras, 32 features
mean = X.mean(dim=0, keepdim=True) # shape (1, 32)
std = X.std(dim=0, keepdim=True) # shape (1, 32)
X_norm = (X - mean) / (std + 1e-8) # broadcasting: (100,32) - (1,32)
2. Autograd: gradientes automaticos
Autograd es el motor de diferenciacion automatica de PyTorch. Cada vez que haces una operacion sobre tensores con requires_grad=True, PyTorch construye un grafo computacional que registra como computar los gradientes usando la regla de la cadena.
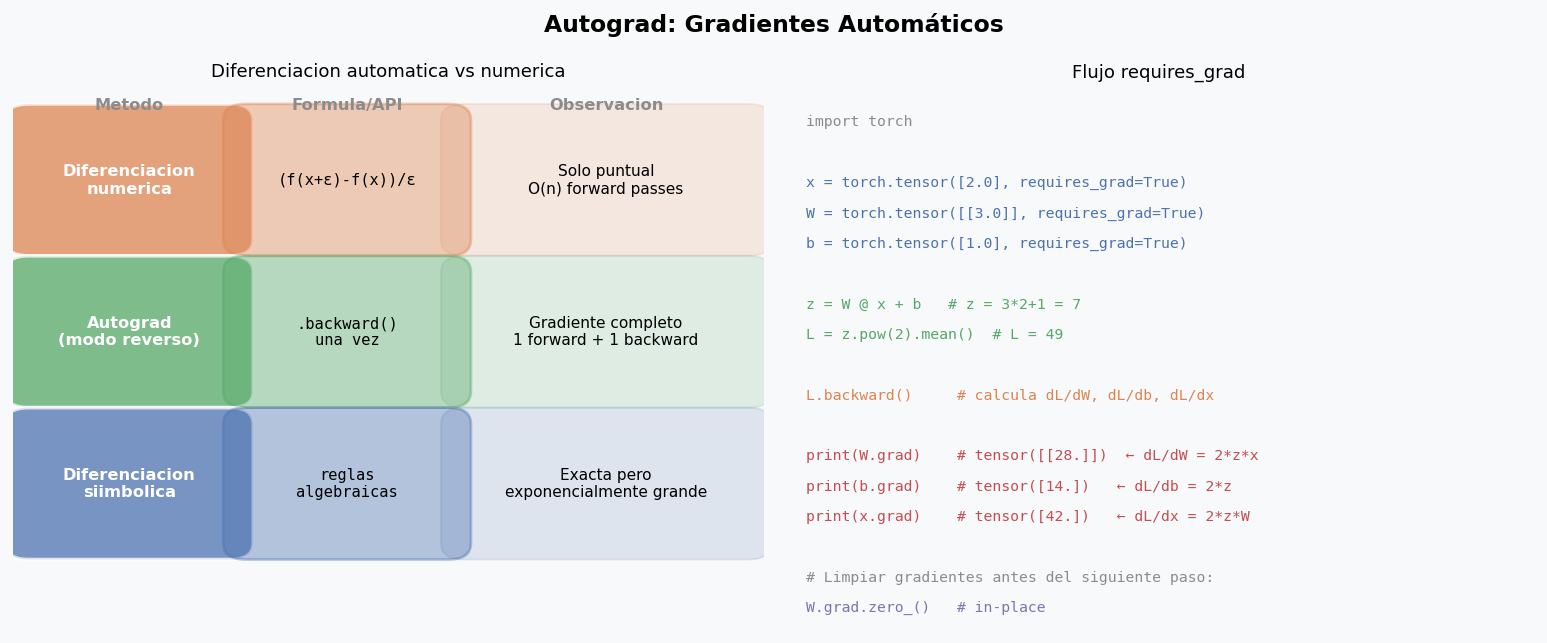
requires_grad y .backward()
import torch
# Tensores con gradiente habilitado
x = torch.tensor([2.0], requires_grad=True)
W = torch.tensor([[3.0]], requires_grad=True)
b = torch.tensor([1.0], requires_grad=True)
# Forward pass — se construye el grafo
z = W @ x + b # z = 3*2 + 1 = 7
L = z.pow(2).mean() # L = 49
# Backward pass — calcula todos los gradientes en un paso
L.backward()
# Acceder a gradientes
print(W.grad) # tensor([[28.]]) — dL/dW = 2*z*x = 2*7*2 = 28
print(b.grad) # tensor([14.]) — dL/db = 2*z = 14
print(x.grad) # tensor([42.]) — dL/dx = 2*z*W = 2*7*3 = 42
# CRITICO: limpiar gradientes antes del siguiente paso
# (PyTorch ACUMULA gradientes por defecto)
W.grad.zero_()
b.grad.zero_()
x.grad.zero_()
# En practica: optimizer.zero_grad() hace esto por todos los params
Controlar el tracking de gradientes
# Durante inferencia/validacion: desactivar tracking
# (ahorra memoria y computo ~2x)
with torch.no_grad():
output = model(X_val) # no construye grafo
loss = criterion(output, y_val)
# loss.backward() lanzaria error aqui
# Desconectar un tensor del grafo
z_detached = z.detach() # nuevo tensor sin gradiente, mismos datos
arr = z_detached.numpy() # ahora si se puede convertir
# Gradientes solo para ciertos parametros
for param in model.parameters():
param.requires_grad = True # activar (default)
# Congelar capas (transfer learning):
for param in model.backbone.parameters():
param.requires_grad = False # no actualizar backbone
Gradiente de funciones personalizadas
# Para operaciones que no soporta autograd directamente
class MyReLU(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
ctx.save_for_backward(x) # guardar para el backward
return x.clamp(min=0)
@staticmethod
def backward(ctx, grad_output):
x, = ctx.saved_tensors
# derivada de ReLU: 1 si x>0, 0 si x<=0
return grad_output * (x > 0).float()
x = torch.randn(3, requires_grad=True)
y = MyReLU.apply(x)
y.sum().backward()
print(x.grad) # 1.0 donde x>0, 0.0 donde x<=0
3. Definir modelos con nn.Module
PyTorch organiza los modelos como subclases de nn.Module. Esto permite parametros aprendibles, capas anidadas, guardado/carga y mucho mas.

nn.Sequential para modelos lineales
import torch.nn as nn
import torch.nn.functional as F
# Para arquitecturas simples y lineales:
model = nn.Sequential(
nn.Linear(784, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(256, 128),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(128, 10),
)
# Inspeccionar modelo
print(model)
total_params = sum(p.numel() for p in model.parameters())
trainable = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Parametros totales: {total_params:,}")
print(f"Entrenables: {trainable:,}")
nn.Module para logica compleja
class MLPClassifier(nn.Module):
def __init__(self, input_dim, hidden_dims, output_dim, dropout=0.3):
super().__init__()
# Construir capas dinamicamente
layers = []
prev = input_dim
for h in hidden_dims:
layers.extend([
nn.Linear(prev, h),
nn.BatchNorm1d(h),
nn.ReLU(),
nn.Dropout(dropout),
])
prev = h
layers.append(nn.Linear(prev, output_dim))
self.network = nn.Sequential(*layers)
def forward(self, x):
return self.network(x) # logits (sin softmax)
# Instanciar
model = MLPClassifier(
input_dim=784,
hidden_dims=[256, 128, 64],
output_dim=10,
dropout=0.3,
)
print(model)
# Ejemplo de forward pass
x_sample = torch.randn(32, 784) # batch de 32
logits = model(x_sample)
print(f"Logits shape: {logits.shape}") # (32, 10)
probs = logits.softmax(dim=1)
preds = logits.argmax(dim=1)
Capas mas comunes en nn
# Capas lineales
nn.Linear(in, out, bias=True) # y = Wx + b
nn.Bilinear(in1, in2, out) # y = x1^T A x2 + b
# Activaciones
nn.ReLU(), nn.LeakyReLU(0.1), nn.ELU()
nn.Sigmoid(), nn.Tanh()
nn.GELU() # Transformers
nn.Softmax(dim=1) # solo en salida
# Regularizacion
nn.Dropout(p=0.5) # p = prob de desactivar
nn.BatchNorm1d(features) # para datos 1D/tabular
nn.BatchNorm2d(channels) # para imagenes
nn.LayerNorm(normalized_shape) # Transformers
# Capas convolucionales (adelanto tema 13)
nn.Conv2d(in_ch, out_ch, kernel_size, stride, padding)
nn.MaxPool2d(kernel_size, stride)
nn.AdaptiveAvgPool2d((1,1)) # Global Average Pooling
# Recurrentes (adelanto tema 14)
nn.LSTM(input_size, hidden_size, num_layers)
nn.GRU(input_size, hidden_size, num_layers)
4. Dataset y DataLoader
El manejo eficiente de datos es tan critico como el modelo. PyTorch provee una abstraccion limpia: Dataset define como acceder a los datos, DataLoader los sirve en batches paralelamente.
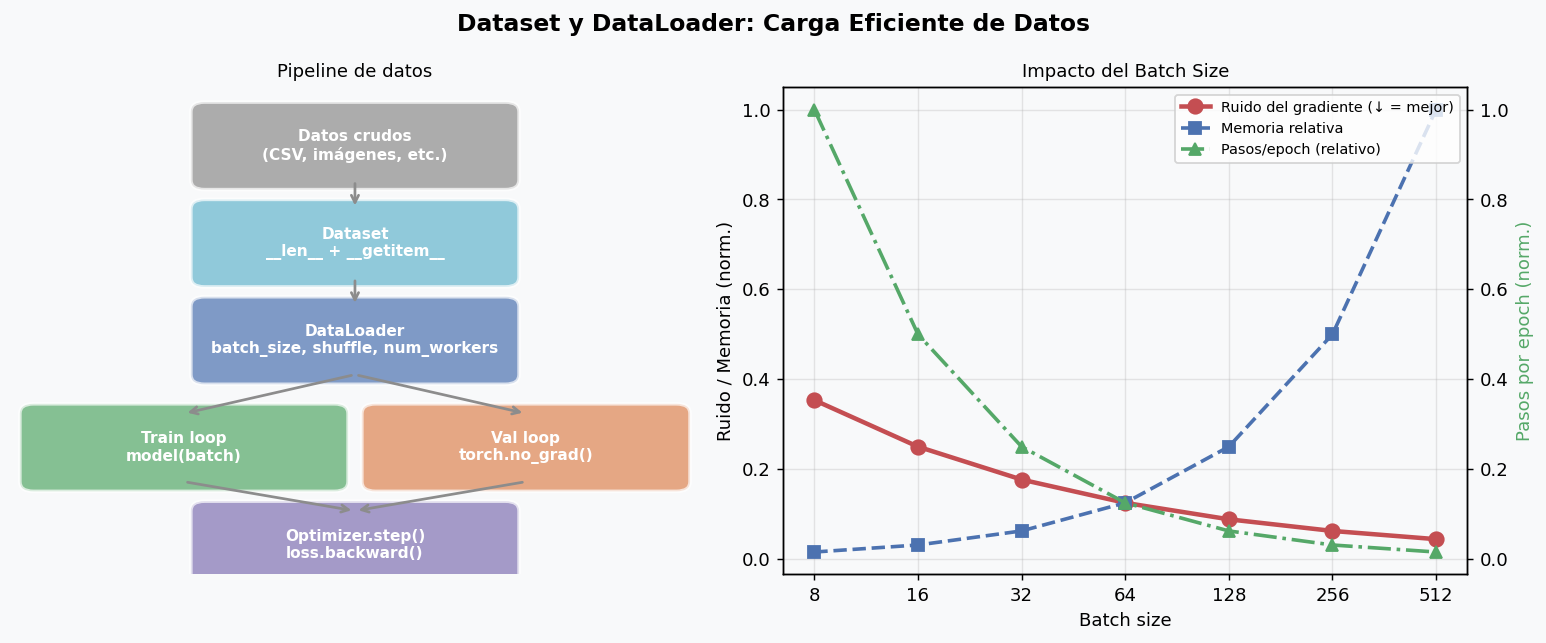
Dataset personalizado
from torch.utils.data import Dataset, DataLoader
import pandas as pd
class TabularDataset(Dataset):
"""Dataset generico para datos tabulares (CSV, DataFrame)."""
def __init__(self, X, y, transform=None):
# X y y deben ser arrays NumPy o tensores
self.X = torch.tensor(X, dtype=torch.float32)
self.y = torch.tensor(y, dtype=torch.long) # long para CrossEntropyLoss
self.transform = transform
def __len__(self):
return len(self.y)
def __getitem__(self, idx):
x, y = self.X[idx], self.y[idx]
if self.transform:
x = self.transform(x)
return x, y
# Dataset de imagenes (ejemplo)
from pathlib import Path
from PIL import Image
import torchvision.transforms as T
class ImageDataset(Dataset):
def __init__(self, root_dir, transform=None):
self.files = list(Path(root_dir).glob("**/*.jpg"))
self.labels = [f.parent.name for f in self.files]
self.class2idx = {c: i for i, c in enumerate(sorted(set(self.labels)))}
self.transform = transform or T.Compose([
T.Resize((224, 224)),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], # ImageNet stats
std=[0.229, 0.224, 0.225]),
])
def __len__(self):
return len(self.files)
def __getitem__(self, idx):
img = Image.open(self.files[idx]).convert("RGB")
x = self.transform(img)
y = self.class2idx[self.labels[idx]]
return x, torch.tensor(y, dtype=torch.long)
DataLoader: opciones importantes
import numpy as np
from sklearn.model_selection import train_test_split
# Crear datasets de train/val
X = np.random.randn(1000, 20).astype(np.float32)
y = (X[:, 0] + X[:, 1] > 0).astype(np.int64)
X_tr, X_val, y_tr, y_val = train_test_split(X, y, test_size=0.2, stratify=y)
train_ds = TabularDataset(X_tr, y_tr)
val_ds = TabularDataset(X_val, y_val)
train_loader = DataLoader(
train_ds,
batch_size=64,
shuffle=True, # mezclar en cada epoch
num_workers=0, # hilos de carga (0=main thread, 4-8 para GPU)
pin_memory=True, # acelera transferencia CPU→GPU
drop_last=True, # descartar ultimo batch incompleto
)
val_loader = DataLoader(
val_ds,
batch_size=128, # batch mas grande en val (sin gradientes)
shuffle=False, # NO mezclar en validacion
num_workers=0,
pin_memory=True,
)
# Verificar un batch
X_batch, y_batch = next(iter(train_loader))
print(f"X batch: {X_batch.shape}, dtype={X_batch.dtype}") # (64, 20)
print(f"y batch: {y_batch.shape}, dtype={y_batch.dtype}") # (64,)
5. Training loop completo
El training loop de PyTorch es explicito — cada paso es visible. Esto hace mas facil depurar y personalizar.
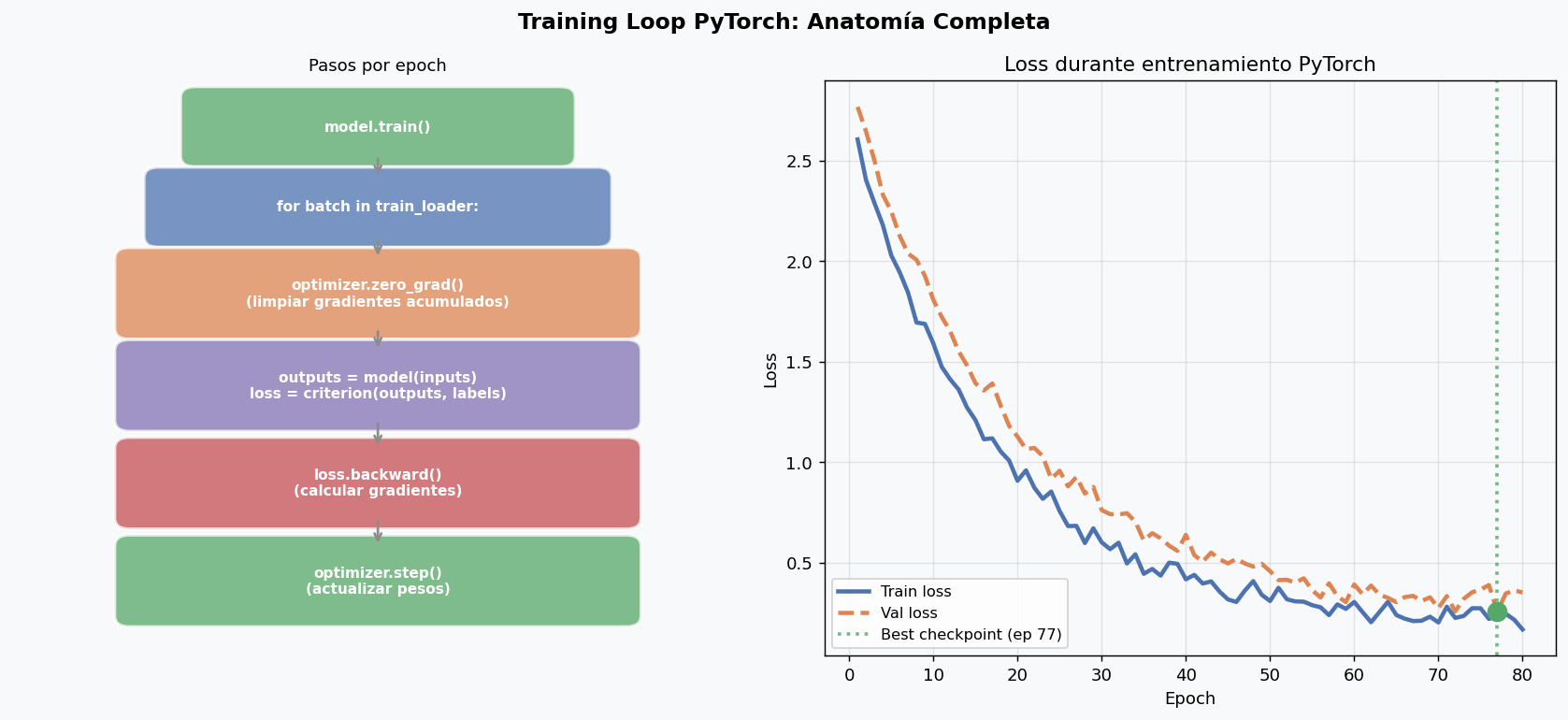
Loop basico pero completo
import torch
import torch.nn as nn
from torch.optim import Adam
from torch.optim.lr_scheduler import CosineAnnealingLR
def train_one_epoch(model, loader, optimizer, criterion, device):
model.train() # activar dropout y batchnorm en modo train
total_loss = 0.0
correct = 0
total = 0
for X_batch, y_batch in loader:
X_batch = X_batch.to(device) # mover a GPU si disponible
y_batch = y_batch.to(device)
# 1. Limpiar gradientes acumulados del paso anterior
optimizer.zero_grad()
# 2. Forward pass
logits = model(X_batch) # (batch, n_classes)
loss = criterion(logits, y_batch)
# 3. Backward pass — calcula gradientes
loss.backward()
# 4. (Opcional) Gradient clipping — evita gradientes explosivos
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
# 5. Actualizar pesos
optimizer.step()
# Acumular metricas
total_loss += loss.item() * len(y_batch)
preds = logits.argmax(dim=1)
correct += (preds == y_batch).sum().item()
total += len(y_batch)
return total_loss / total, correct / total
@torch.no_grad() # decorator equivalente a with torch.no_grad()
def evaluate(model, loader, criterion, device):
model.eval() # desactivar dropout, batchnorm en modo eval
total_loss = 0.0
correct = 0
total = 0
for X_batch, y_batch in loader:
X_batch = X_batch.to(device)
y_batch = y_batch.to(device)
logits = model(X_batch)
loss = criterion(logits, y_batch)
total_loss += loss.item() * len(y_batch)
preds = logits.argmax(dim=1)
correct += (preds == y_batch).sum().item()
total += len(y_batch)
return total_loss / total, correct / total
# Configurar entrenamiento
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = MLPClassifier(20, [128, 64], 2, dropout=0.3).to(device)
optimizer = Adam(model.parameters(), lr=1e-3, weight_decay=1e-4)
criterion = nn.CrossEntropyLoss()
scheduler = CosineAnnealingLR(optimizer, T_max=50, eta_min=1e-5)
# Training loop
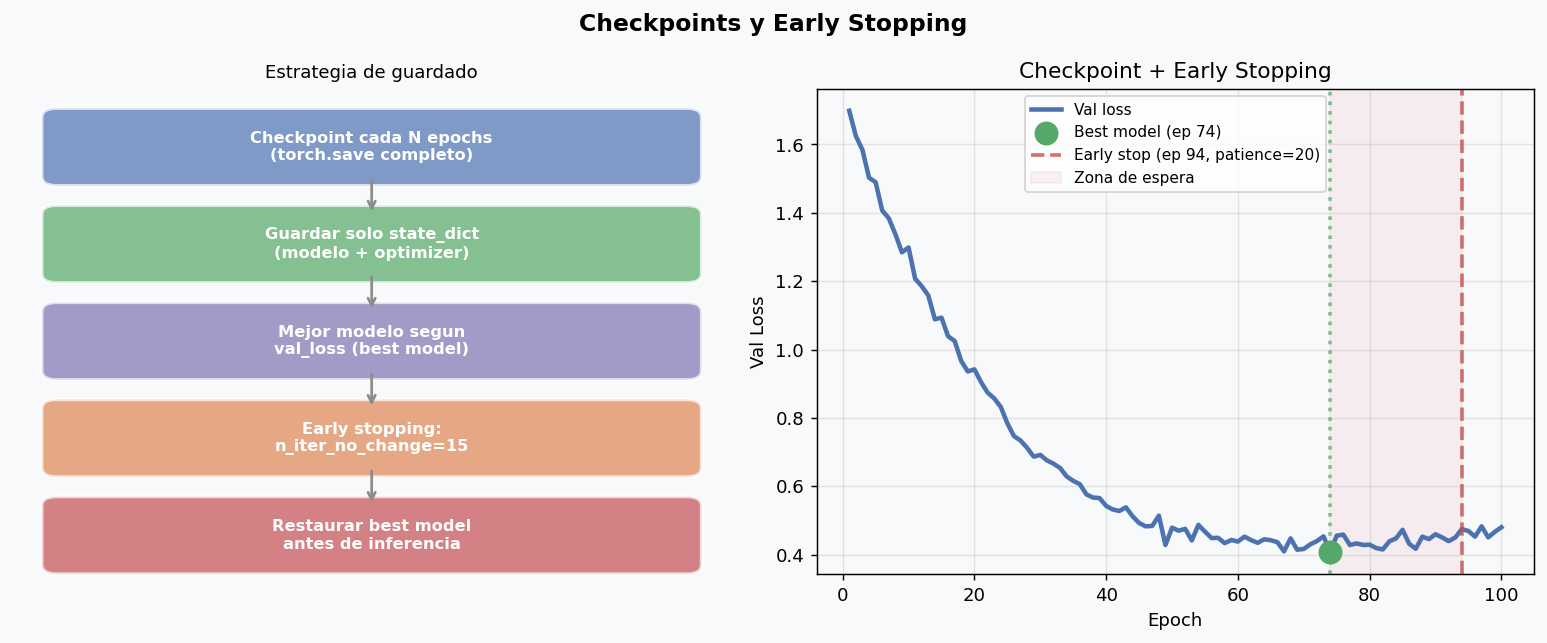
history = {"train_loss": [], "val_loss": [], "train_acc": [], "val_acc": []}
best_val_loss = float("inf")
patience_counter = 0
PATIENCE = 15
for epoch in range(1, 101):
tr_loss, tr_acc = train_one_epoch(model, train_loader, optimizer, criterion, device)
va_loss, va_acc = evaluate(model, val_loader, criterion, device)
scheduler.step()
history["train_loss"].append(tr_loss)
history["val_loss"].append(va_loss)
history["train_acc"].append(tr_acc)
history["val_acc"].append(va_acc)
# Guardar mejor modelo
if va_loss < best_val_loss:
best_val_loss = va_loss
torch.save(model.state_dict(), "best_model.pt")
patience_counter = 0
else:
patience_counter += 1
if epoch % 10 == 0:
print(f"Ep {epoch:3d} | "
f"train loss={tr_loss:.4f} acc={tr_acc:.3f} | "
f"val loss={va_loss:.4f} acc={va_acc:.3f} | "
f"LR={scheduler.get_last_lr()[0]:.6f}")
# Early stopping
if patience_counter >= PATIENCE:
print(f"Early stopping en epoch {epoch}")
break
# Restaurar mejor modelo para inferencia
model.load_state_dict(torch.load("best_model.pt", map_location=device))
model.eval()
6. Learning rate schedulers
El learning rate es el hiperparametro mas critico. Un scheduler lo adapta a lo largo del entrenamiento.
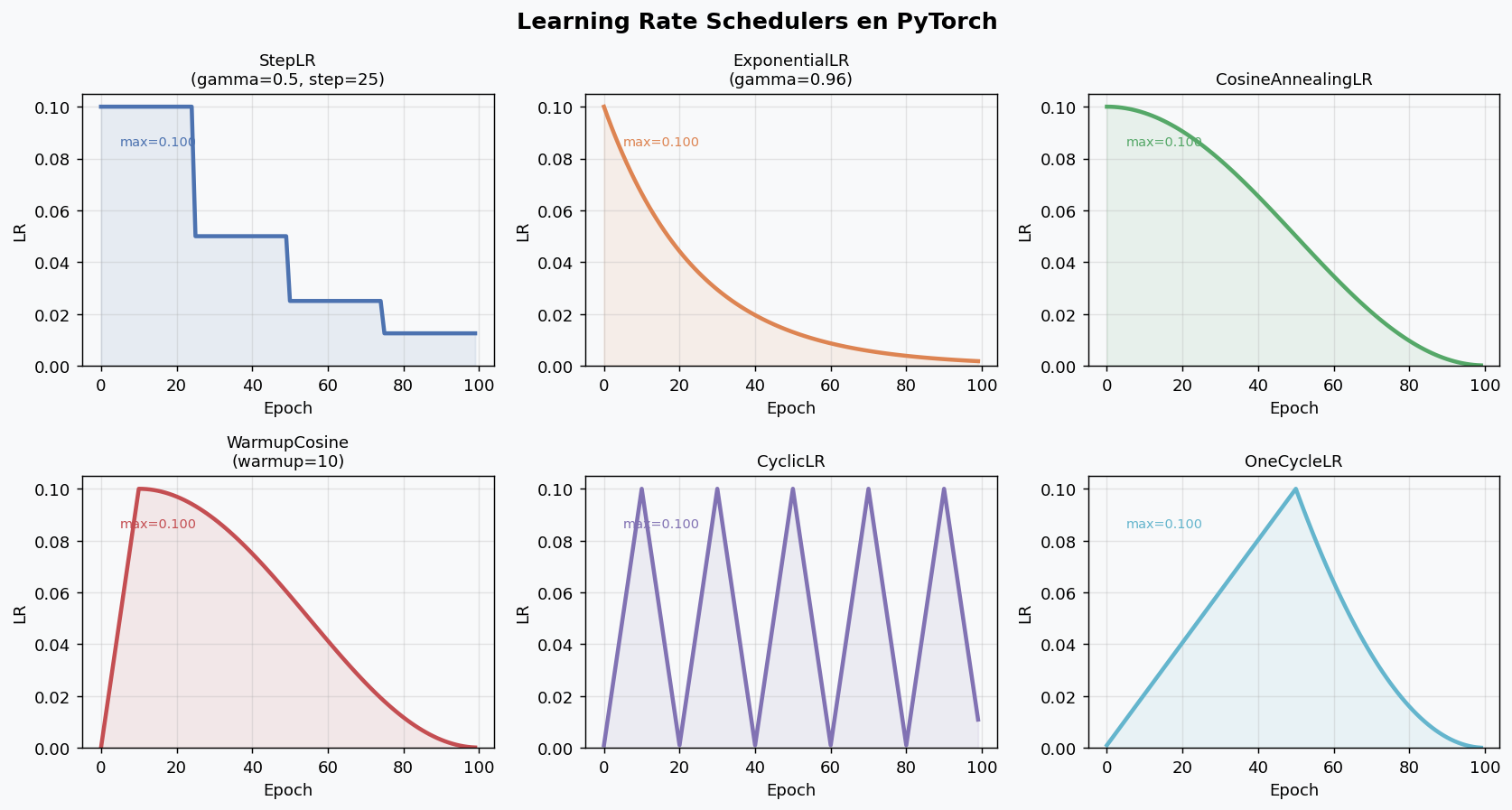
from torch.optim.lr_scheduler import (
StepLR,
ExponentialLR,
CosineAnnealingLR,
OneCycleLR,
ReduceLROnPlateau,
CyclicLR,
)
optimizer = Adam(model.parameters(), lr=0.001)
# StepLR: divide por gamma cada step_size epochs
sched1 = StepLR(optimizer, step_size=25, gamma=0.5)
# lr: 0.001 → 0.0005 (ep25) → 0.00025 (ep50) → ...
# ExponentialLR: decae exponencialmente
sched2 = ExponentialLR(optimizer, gamma=0.96)
# lr *= 0.96 cada epoch
# CosineAnnealingLR: ciclo coseno suave (recomendado)
sched3 = CosineAnnealingLR(optimizer, T_max=100, eta_min=1e-5)
# OneCycleLR: warmup + cosine en 1 ciclo (muy efectivo)
sched4 = OneCycleLR(
optimizer,
max_lr=0.01,
steps_per_epoch=len(train_loader),
epochs=50,
pct_start=0.3, # 30% warmup
div_factor=25, # lr_inicial = max_lr/25
final_div_factor=1e4, # lr_final = max_lr/1e4
)
# NOTA: OneCycleLR se llama por STEP, no por epoch:
# for batch in loader: ... sched4.step()
# ReduceLROnPlateau: reduce cuando la metrica se estanca
sched5 = ReduceLROnPlateau(
optimizer, mode="min", factor=0.5,
patience=10, min_lr=1e-6, verbose=True
)
# Se llama con la metrica: sched5.step(val_loss)
# Regla practica:
# - OneCycleLR: mayor accuracy, especialmente con Adam
# - CosineAnnealingLR: robusto y facil de usar
# - ReduceLROnPlateau: util cuando no sabes cuantos epochs necesitas
7. GPU: cuando y como usarla
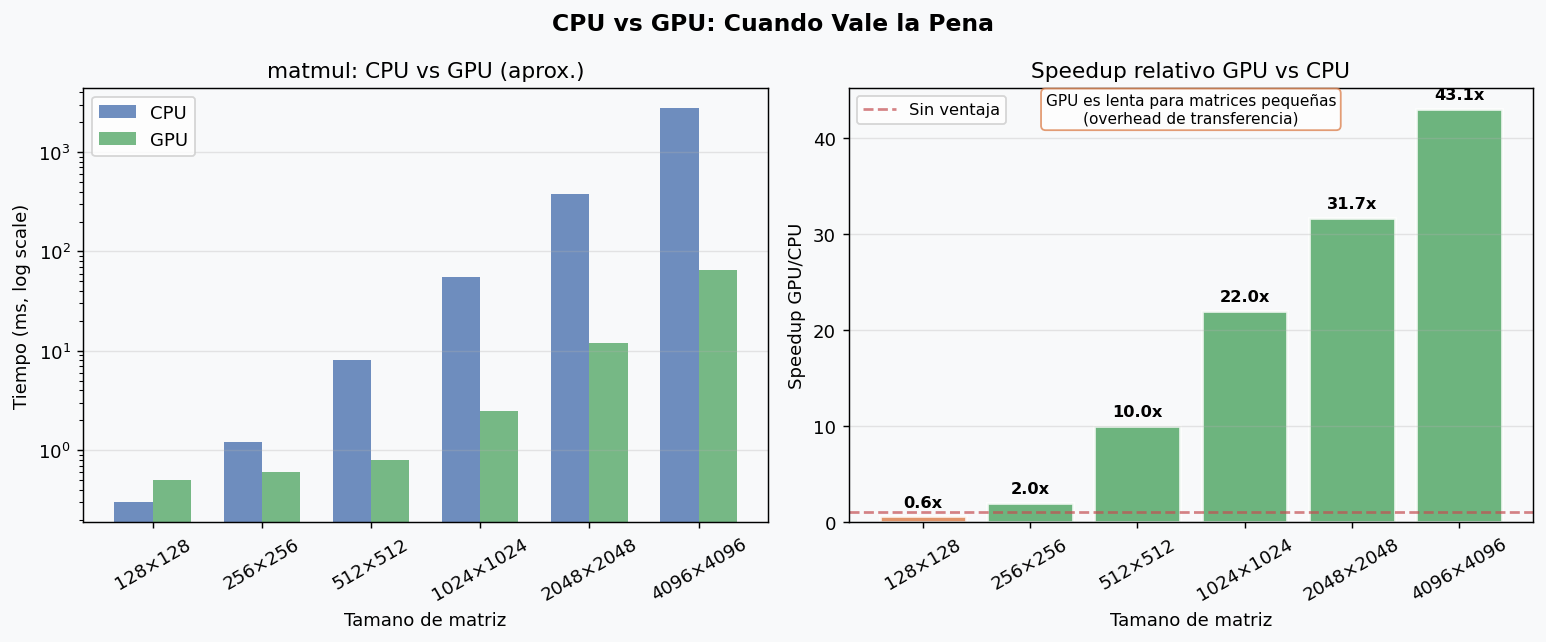
La GPU es mucho mas rapida para operaciones matriciales grandes. Pero para matrices pequenas, el overhead de transferencia CPU↔GPU la hace mas lenta. En deep learning, los modelos tipicos tienen matrices de cientos a miles de dimensiones — la GPU siempre vale la pena.
# Verificar disponibilidad
print(torch.cuda.is_available()) # True si hay GPU CUDA
print(torch.cuda.get_device_name(0)) # "NVIDIA RTX 4090" etc.
print(torch.cuda.memory_allocated() / 1e9) # GB usados
# Patron idiomatico — portable CPU/GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Usando: {device}")
# Mover modelo y datos al device
model = model.to(device) # o model.cuda()
X_batch = X_batch.to(device, non_blocking=True) # non_blocking con pin_memory
# Mixed precision (float16 en forward/backward, float32 en optimizer)
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler() # escala loss para evitar underflow en float16
for X_batch, y_batch in train_loader:
X_batch = X_batch.to(device)
y_batch = y_batch.to(device)
optimizer.zero_grad()
with autocast(): # todo en float16 automaticamente
logits = model(X_batch)
loss = criterion(logits, y_batch)
scaler.scale(loss).backward() # escalar loss antes de backward
scaler.unscale_(optimizer) # desescalar gradientes
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
scaler.step(optimizer) # actualizar pesos
scaler.update() # actualizar escala
# Ventaja AMP: ~2x velocidad, ~50% menos memoria GPU
8. Guardado y carga de modelos
# ── Guardar ───────────────────────────────────────────────────────────────
# Solo pesos del modelo (recomendado)
torch.save(model.state_dict(), "model_weights.pt")
# Checkpoint completo (para reanudar entrenamiento)
checkpoint = {
"epoch": epoch,
"model_state": model.state_dict(),
"optimizer_state": optimizer.state_dict(),
"scheduler_state": scheduler.state_dict(),
"val_loss": best_val_loss,
"config": { # guardar hiperparametros para reproducibilidad
"hidden_dims": [128, 64],
"dropout": 0.3,
"lr": 1e-3,
}
}
torch.save(checkpoint, "checkpoint_ep50.pt")
# ── Cargar ────────────────────────────────────────────────────────────────
# Solo pesos (requiere crear el modelo antes)
model = MLPClassifier(20, [128, 64], 2).to(device)
model.load_state_dict(torch.load("model_weights.pt", map_location=device))
model.eval()
# Checkpoint completo (para continuar entrenamiento)
ckpt = torch.load("checkpoint_ep50.pt", map_location=device)
model.load_state_dict(ckpt["model_state"])
optimizer.load_state_dict(ckpt["optimizer_state"])
scheduler.load_state_dict(ckpt["scheduler_state"])
start_epoch = ckpt["epoch"] + 1
print(f"Reanudando desde epoch {start_epoch}, val_loss={ckpt['val_loss']:.4f}")
# ── Inferencia ────────────────────────────────────────────────────────────
model.eval()
with torch.no_grad():
X_test = torch.tensor(X_val, dtype=torch.float32).to(device)
logits = model(X_test)
probs = logits.softmax(dim=1) # probabilidades
preds = logits.argmax(dim=1) # clase predicha
conf = probs.max(dim=1).values # confianza maxima
# Volver a NumPy para sklearn metrics
preds_np = preds.cpu().numpy()
probs_np = probs.cpu().numpy()
9. Mini-proyecto: pipeline completo PyTorch
Construye un clasificador completo para el dataset Iris (tabular) usando el flujo profesional de PyTorch.
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader, random_split
from torch.optim import AdamW
from torch.optim.lr_scheduler import OneCycleLR
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report
import numpy as np
# ── 1. Datos ────────────────────────────────────────────────────────────────
def set_seed(seed=42):
torch.manual_seed(seed)
np.random.seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
set_seed(42)
iris = load_iris()
X_raw, y_raw = iris.data.astype(np.float32), iris.target.astype(np.int64)
sc = StandardScaler()
X_scaled = sc.fit_transform(X_raw)
class IrisDataset(Dataset):
def __init__(self, X, y):
self.X = torch.tensor(X)
self.y = torch.tensor(y)
def __len__(self): return len(self.y)
def __getitem__(self, i): return self.X[i], self.y[i]
full_ds = IrisDataset(X_scaled, y_raw)
n_train = int(0.8 * len(full_ds))
n_val = len(full_ds) - n_train
train_ds, val_ds = random_split(full_ds, [n_train, n_val],
generator=torch.Generator().manual_seed(42))
train_loader = DataLoader(train_ds, batch_size=16, shuffle=True)
val_loader = DataLoader(val_ds, batch_size=32, shuffle=False)
# ── 2. Modelo ────────────────────────────────────────────────────────────────
class IrisNet(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(4, 32), nn.BatchNorm1d(32), nn.ReLU(), nn.Dropout(0.2),
nn.Linear(32, 16), nn.ReLU(),
nn.Linear(16, 3),
)
def forward(self, x): return self.net(x)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = IrisNet().to(device)
# ── 3. Entrenamiento ─────────────────────────────────────────────────────────
optimizer = AdamW(model.parameters(), lr=1e-3, weight_decay=1e-3)
criterion = nn.CrossEntropyLoss()
scheduler = OneCycleLR(optimizer, max_lr=1e-2,
steps_per_epoch=len(train_loader), epochs=80)
best_val_acc = 0.0
for epoch in range(1, 81):
model.train()
for xb, yb in train_loader:
xb, yb = xb.to(device), yb.to(device)
optimizer.zero_grad()
loss = criterion(model(xb), yb)
loss.backward()
optimizer.step()
scheduler.step()
model.eval()
correct = total = 0
with torch.no_grad():
for xb, yb in val_loader:
xb, yb = xb.to(device), yb.to(device)
preds = model(xb).argmax(dim=1)
correct += (preds == yb).sum().item()
total += len(yb)
val_acc = correct / total
if val_acc > best_val_acc:
best_val_acc = val_acc
torch.save(model.state_dict(), "iris_best.pt")
# ── 4. Evaluacion final ───────────────────────────────────────────────────────
model.load_state_dict(torch.load("iris_best.pt", map_location=device))
model.eval()
all_preds, all_true = [], []
with torch.no_grad():
for xb, yb in val_loader:
xb = xb.to(device)
preds = model(xb).argmax(dim=1).cpu().numpy()
all_preds.extend(preds)
all_true.extend(yb.numpy())
print(f"Mejor val accuracy: {best_val_acc:.3f}")
print(classification_report(all_true, all_preds,
target_names=iris.target_names))
10. Semillas y reproducibilidad
import torch
import numpy as np
import random
import os
def set_seed(seed: int = 42):
"""Fija todas las semillas para reproducibilidad completa."""
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
# Determinismo en convoluciones (puede ser mas lento)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
os.environ["PYTHONHASHSEED"] = str(seed)
set_seed(42)
Errores comunes y como evitarlos
| Error | Sintoma | Solucion |
|---|---|---|
Olvidar model.train() | Dropout/BN no funcionan en entrenamiento | Llamar antes del loop de train |
Olvidar model.eval() | Dropout activo en validacion, resultados ruidosos | Llamar antes de cada eval |
No usar torch.no_grad() | Memoria GPU crece durante validacion | Siempre en eval/inferencia |
| Gradientes acumulados | Loss parece converger pero diverge en practica | optimizer.zero_grad() al inicio del loop |
| No mover datos al device | RuntimeError: expected device cuda, got cpu | .to(device) en X_batch y y_batch |
loss.item() en el loop | Problema de memoria (retiene grafo computacional) | Solo usar .item() para loggear |
Fuga de .numpy() con requires_grad | Error al convertir tensor a array | .detach().cpu().numpy() |
pin_memory=True sin GPU | Advertencia o degradacion | Usar solo cuando device == "cuda" |
| Semillas no fijadas | Resultados irreproducibles | set_seed(42) antes de todo |
Dashboard resumen
Recursos recomendados
- Tutorial oficial PyTorch: empieza por “Learn the Basics” — cubre tensores, autograd, training loop con ejemplos ejecutables
- Fast.ai Practical Deep Learning: enfoque top-down; ideal para ver PyTorch en proyectos reales desde el inicio
- PyTorch Lightning: abstraccion sobre PyTorch que elimina boilerplate manteniendo flexibilidad total
- “Deep Learning with PyTorch” (Eli Stevens et al.): libro oficial de Manning, cubre desde tensores hasta GANs
- Papers With Code: implementaciones de papers en PyTorch con resultados replicables
Navegacion
← 10. Introduccion a Redes Neuronales | 12. Tecnicas de Entrenamiento en Deep Learning →