4. Visualizacion de Datos
Teoria
La visualizacion es parte central del analisis exploratorio (EDA):
- Matplotlib para graficos base.
- Seaborn para visualizaciones estadisticas rapidas.
- Histogramas para distribuciones.
- Scatter plots para relaciones entre variables.
- Heatmaps de correlacion.
- Analisis de distribucion y asimetria.
- Deteccion de outliers con boxplots.
Objetivo principal: entender el dataset antes de entrenar.
Guia visual extensa con ejemplos (Matplotlib + Seaborn)
En esta parte aprenderas no solo a “hacer graficos”, sino a elegir el grafico correcto para cada pregunta de competencia.
Setup recomendado para notebooks
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid", context="notebook")
plt.rcParams["figure.figsize"] = (10, 5)
plt.rcParams["axes.titlesize"] = 13
plt.rcParams["axes.labelsize"] = 11
1) Cargar y entender rapidamente un dataset
df = pd.read_csv("train.csv")
print(df.shape)
print(df.head())
print(df.info())
print(df.describe(include="all").T.head(15))
print(df.isna().sum().sort_values(ascending=False).head(10))
Antes de graficar, define preguntas:
- Como se distribuye la variable objetivo?
- Hay sesgo fuerte u outliers?
- Que variables parecen utiles?
- Existen subgrupos con comportamiento distinto?
2) Histogramas y distribucion
Uso: entender forma de la distribucion, asimetria y posibles transformaciones.
target_col = "SalePrice"
fig, ax = plt.subplots(1, 2, figsize=(14, 5))
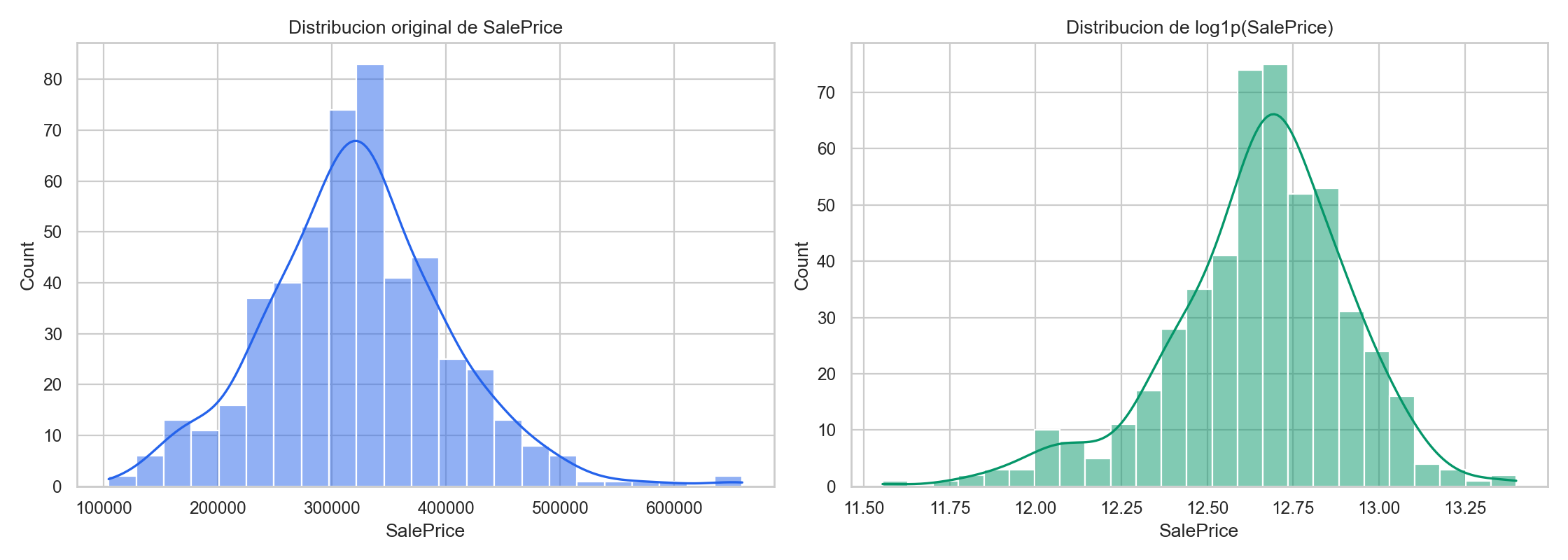
sns.histplot(df[target_col].dropna(), kde=True, ax=ax[0], color="#2563eb")
ax[0].set_title("Distribucion original de SalePrice")
sns.histplot(np.log1p(df[target_col].dropna()), kde=True, ax=ax[1], color="#059669")
ax[1].set_title("Distribucion de log1p(SalePrice)")
plt.tight_layout()
plt.show()
Interpretacion tipica:
- Si la cola derecha es muy larga,
log1ppuede ayudar. - Si hay varios picos, puede haber segmentos diferentes en los datos.
Ejemplo visual:
3) Boxplot para detectar outliers
Uso: detectar valores extremos y comparar distribuciones entre grupos.
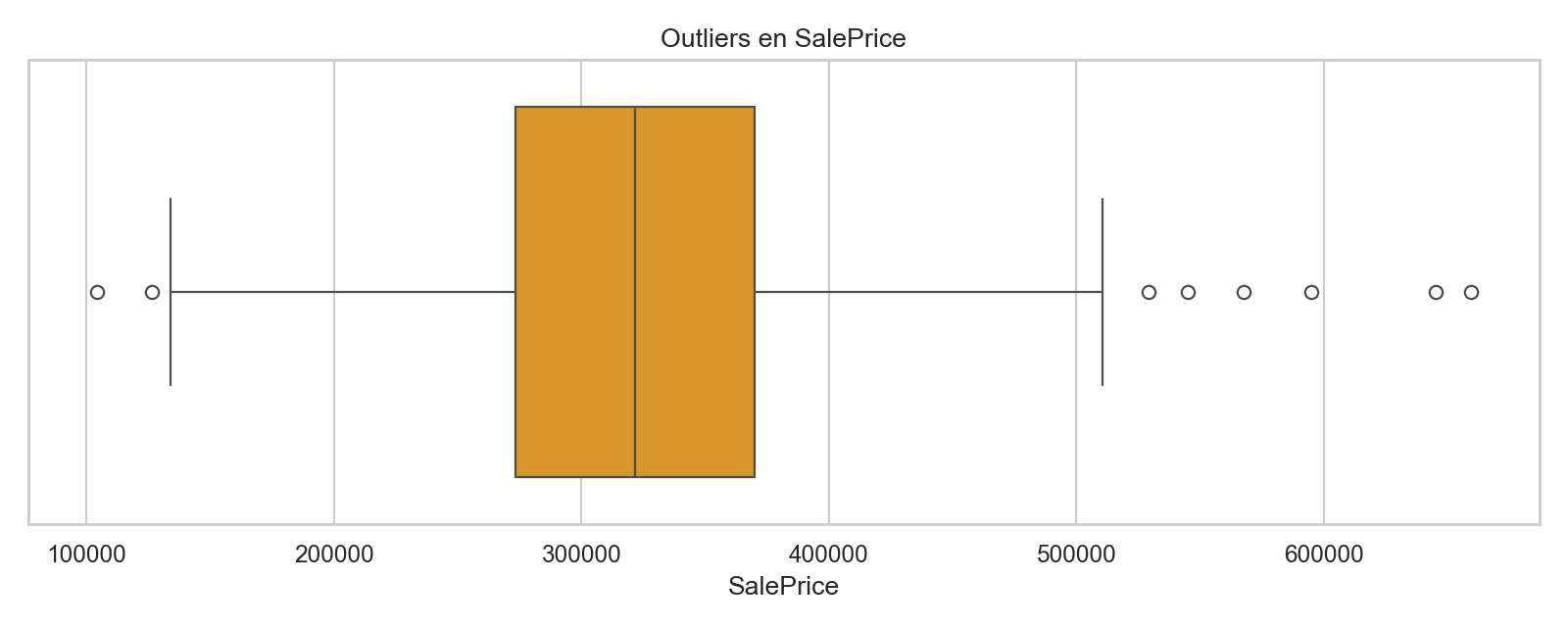
plt.figure(figsize=(10, 4))
sns.boxplot(x=df[target_col], color="#f59e0b")
plt.title("Outliers en SalePrice")
plt.xlabel("SalePrice")
plt.show()
Ejemplo visual:
Por categoria:
top_neighborhoods = (
df["Neighborhood"].value_counts().head(8).index
)
sub = df[df["Neighborhood"].isin(top_neighborhoods)]
plt.figure(figsize=(12, 5))
sns.boxplot(data=sub, x="Neighborhood", y=target_col)
plt.xticks(rotation=30)
plt.title("SalePrice por Neighborhood (top 8)")
plt.show()
4) Scatter plot para relaciones entre variables
Uso: ver tendencia, dispersion y posibles relaciones no lineales.
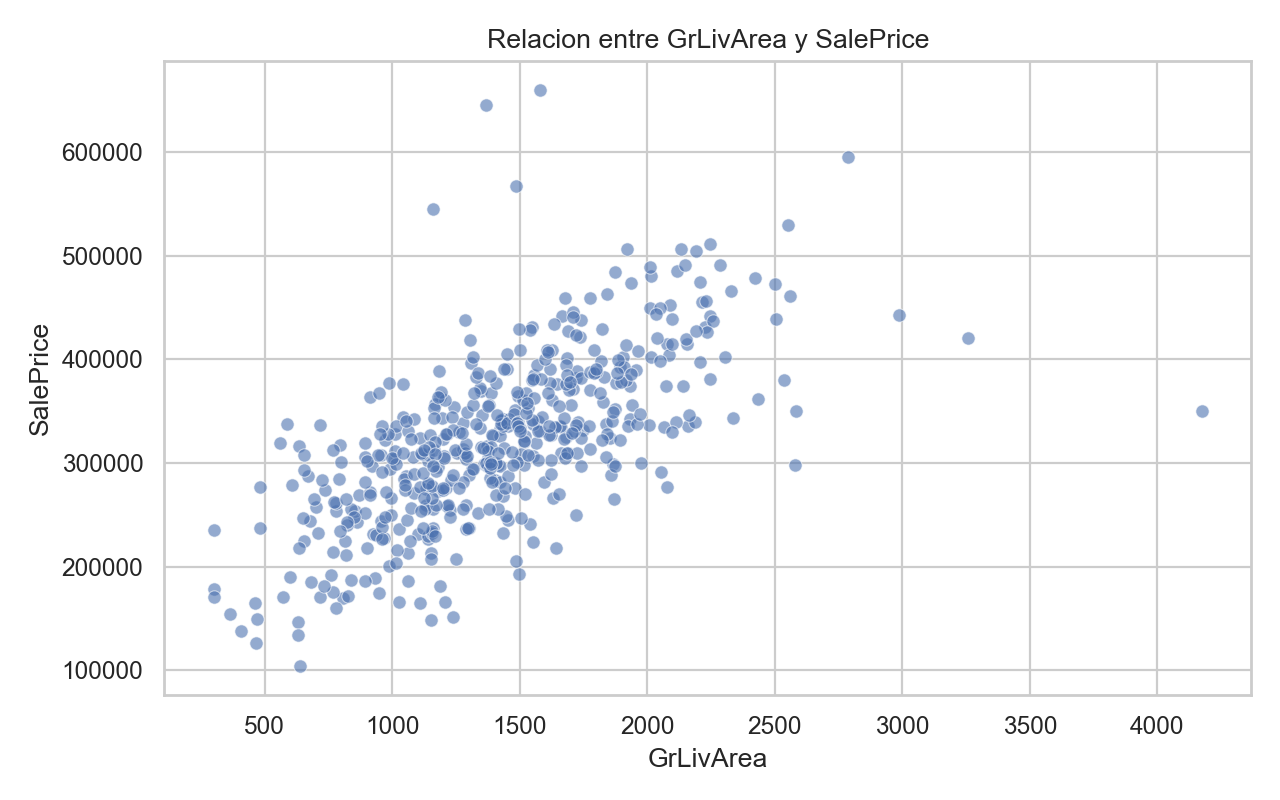
plt.figure(figsize=(8, 5))
sns.scatterplot(data=df, x="GrLivArea", y=target_col, alpha=0.6)
plt.title("Relacion entre GrLivArea y SalePrice")
plt.show()
Ejemplo visual:
Con linea de tendencia:
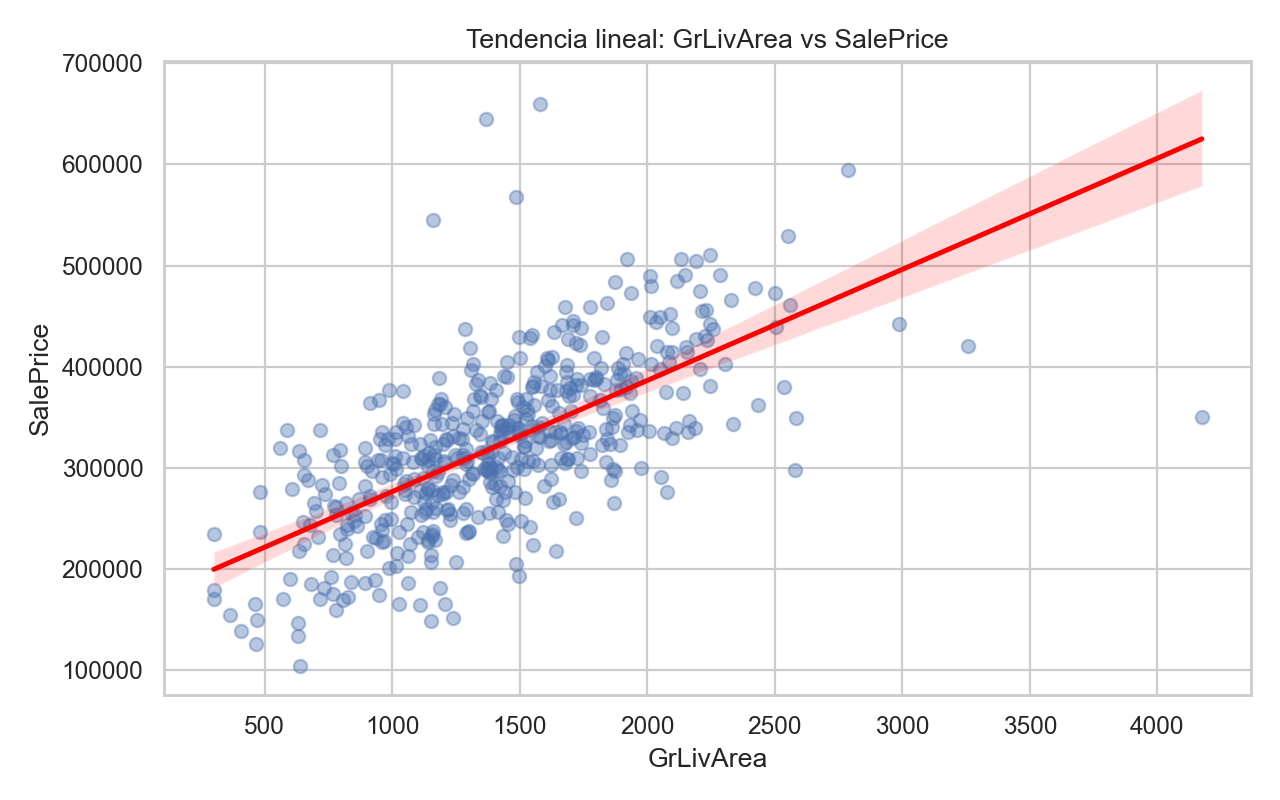
plt.figure(figsize=(8, 5))
sns.regplot(data=df, x="GrLivArea", y=target_col,
scatter_kws={"alpha": 0.4}, line_kws={"color": "red"})
plt.title("Tendencia lineal: GrLivArea vs SalePrice")
plt.show()
Ejemplo visual:
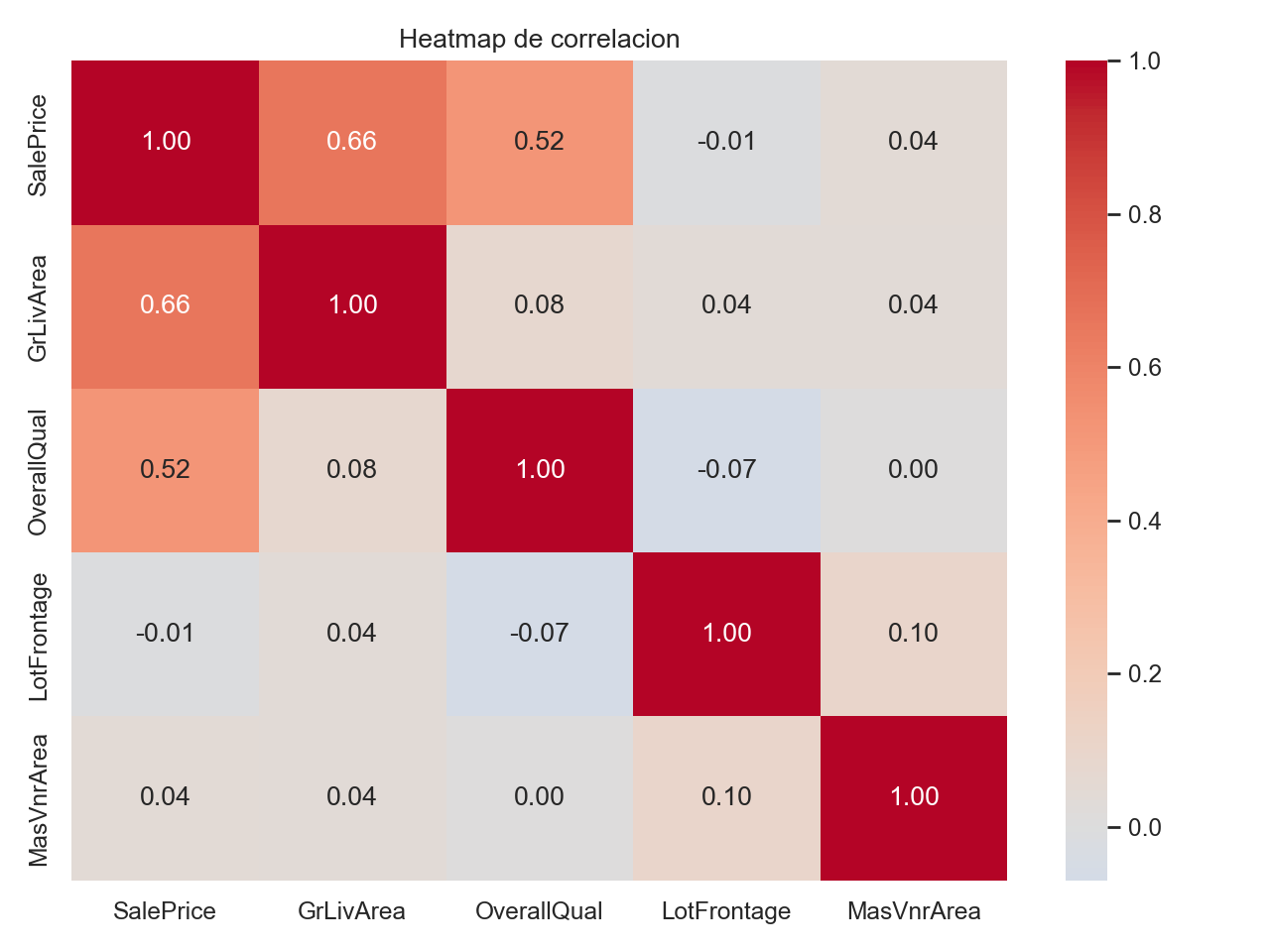
5) Correlaciones y heatmap
Uso: identificar columnas potencialmente utiles/redundantes.
num_df = df.select_dtypes(include=["number"])
corr = num_df.corr(numeric_only=True)
# Top 12 variables mas correlacionadas con el target
top_cols = corr[target_col].abs().sort_values(ascending=False).head(12).index
plt.figure(figsize=(10, 8))
sns.heatmap(corr.loc[top_cols, top_cols], annot=True, fmt=".2f", cmap="coolwarm", center=0)
plt.title("Heatmap de correlacion (top variables)")
plt.show()
Importante: correlacion alta no implica causalidad.
Ejemplo visual:
6) Graficos categoricos utiles
Uso: comparar medias/medianas por categoria y tamaño de muestra.
mean_price = (
df.groupby("Neighborhood")[target_col]
.mean()
.sort_values(ascending=False)
.head(10)
.reset_index()
)
plt.figure(figsize=(12, 5))
sns.barplot(data=mean_price, x="Neighborhood", y=target_col, color="#3b82f6")
plt.xticks(rotation=30)
plt.title("Top 10 Neighborhood por precio promedio")
plt.show()
Ejemplo visual:
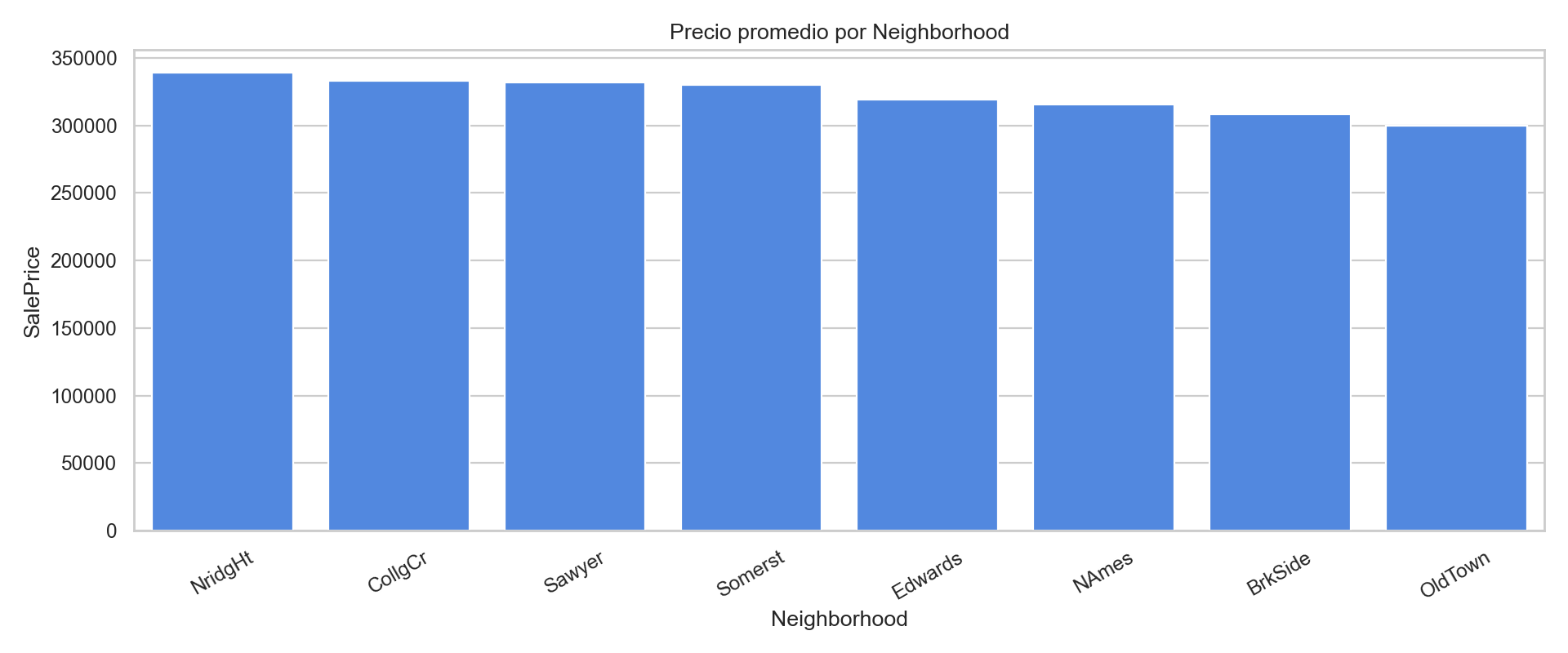
Grafico de conteo:
plt.figure(figsize=(12, 5))
sns.countplot(data=df, x="OverallQual", color="#14b8a6")
plt.title("Frecuencia de OverallQual")
plt.show()
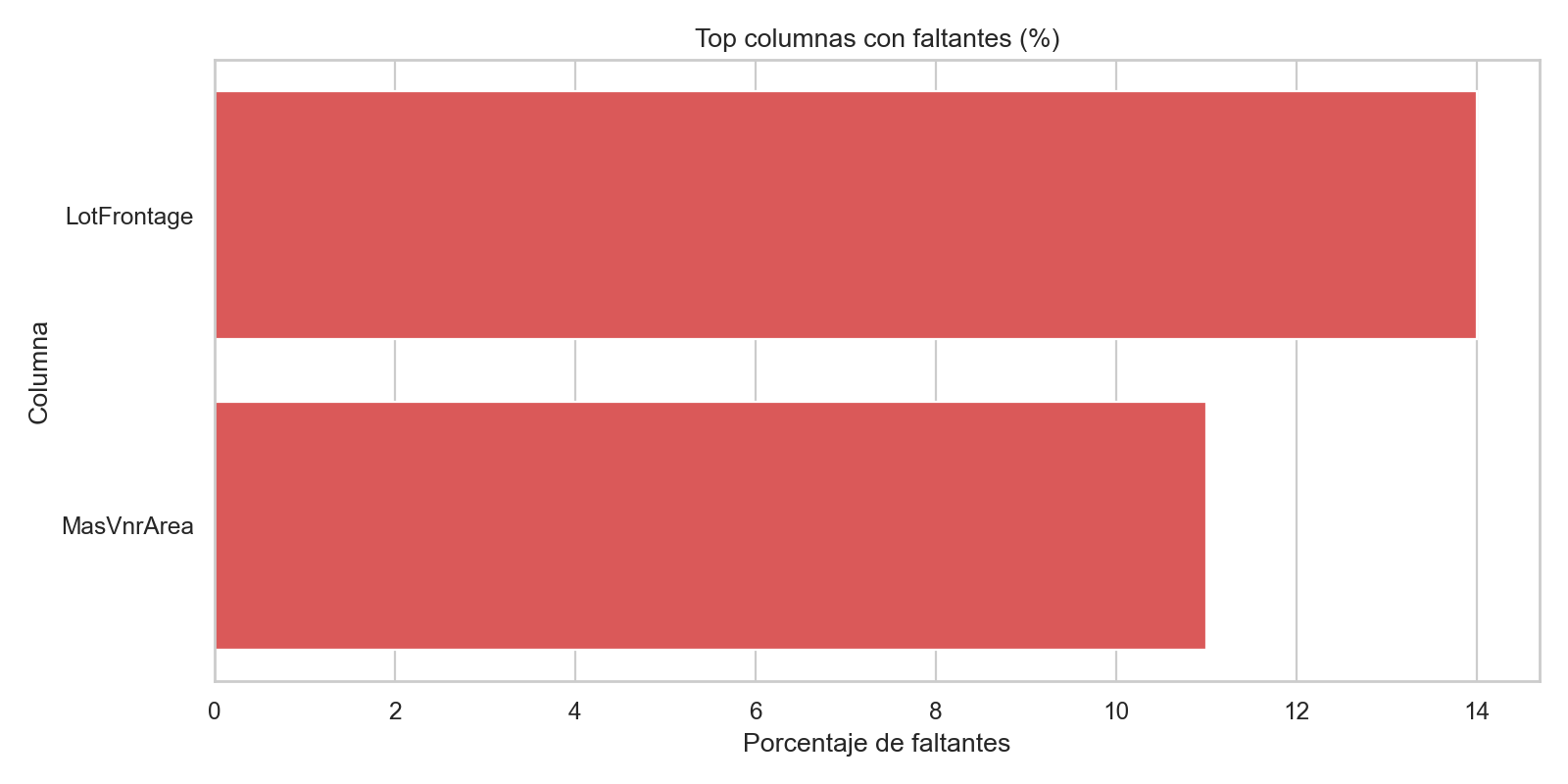
7) Missing values visuales
Uso: detectar rapido columnas con muchos faltantes.
missing_pct = (df.isna().mean() * 100).sort_values(ascending=False)
missing_pct = missing_pct[missing_pct > 0].head(20)
plt.figure(figsize=(10, 6))
sns.barplot(x=missing_pct.values, y=missing_pct.index, color="#ef4444")
plt.title("Top columnas con faltantes (%)")
plt.xlabel("Porcentaje de faltantes")
plt.ylabel("Columna")
plt.show()
Ejemplo visual:
8) Deteccion visual de leakage o problemas de split
Idea: comparar distribuciones entre train y test para encontrar drift sospechoso.
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
col = "GrLivArea"
plt.figure(figsize=(10, 5))
sns.kdeplot(train[col].dropna(), label="train", fill=True, alpha=0.3)
sns.kdeplot(test[col].dropna(), label="test", fill=True, alpha=0.3)
plt.title(f"Comparacion de distribucion en {col}")
plt.legend()
plt.show()
Si las curvas son muy diferentes, revisa split, muestreo y robustez de features.
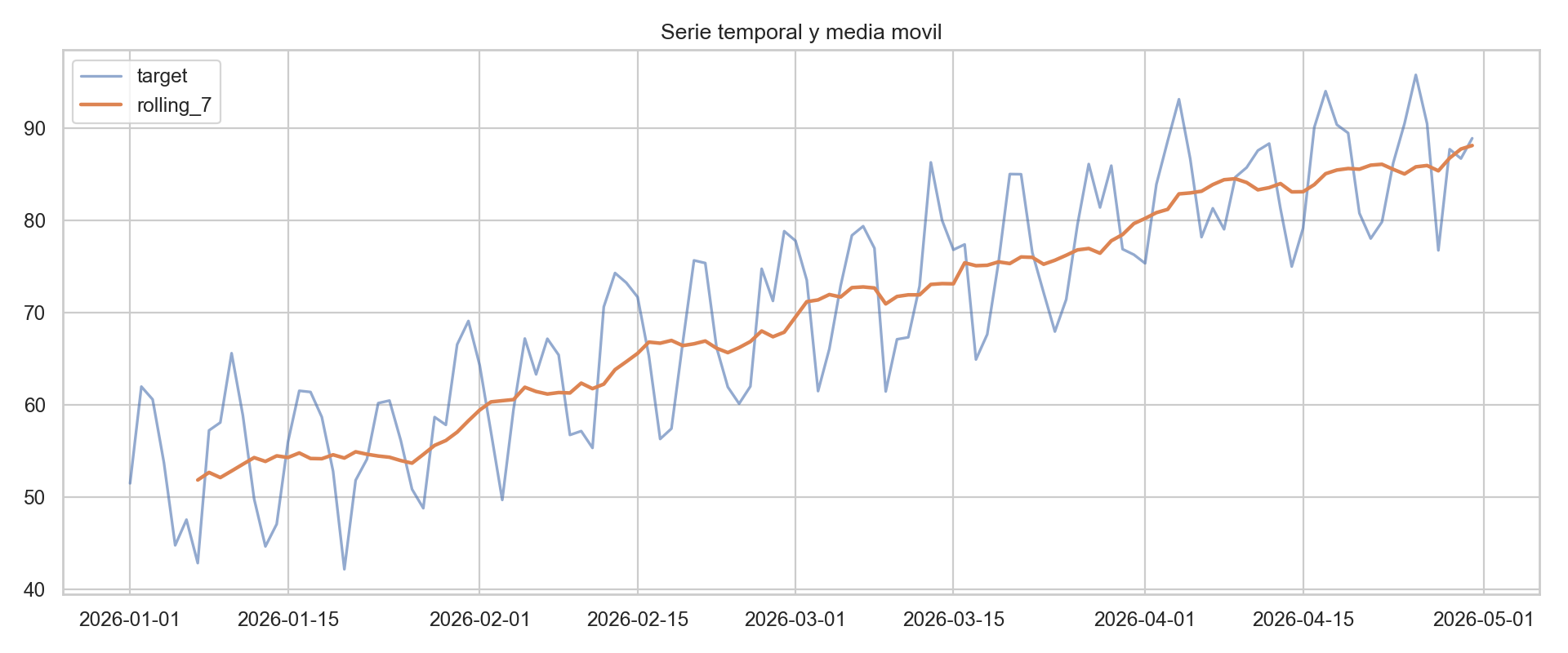
9) Series temporales basicas
ts = pd.read_csv("time_series.csv")
ts["date"] = pd.to_datetime(ts["date"])
ts = ts.sort_values("date")
ts["rolling_7"] = ts["target"].rolling(7).mean()
plt.figure(figsize=(12, 5))
plt.plot(ts["date"], ts["target"], label="target", alpha=0.6)
plt.plot(ts["date"], ts["rolling_7"], label="rolling_7", linewidth=2)
plt.title("Serie temporal y media movil")
plt.legend()
plt.show()
Ejemplo visual:
10) Mini-dashboard EDA en una sola figura
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
sns.histplot(df[target_col].dropna(), kde=True, ax=axes[0, 0], color="#2563eb")
axes[0, 0].set_title("Distribucion objetivo")
sns.scatterplot(data=df, x="GrLivArea", y=target_col, alpha=0.5, ax=axes[0, 1])
axes[0, 1].set_title("Relacion area-precio")
sns.boxplot(y=df[target_col], ax=axes[1, 0], color="#f59e0b")
axes[1, 0].set_title("Outliers objetivo")
top_missing = (df.isna().mean() * 100).sort_values(ascending=False).head(10)
sns.barplot(x=top_missing.values, y=top_missing.index, ax=axes[1, 1], color="#ef4444")
axes[1, 1].set_title("Top faltantes (%)")
plt.tight_layout()
plt.show()
Este tipo de dashboard sirve para tomar decisiones rapidas antes del primer baseline.
Ejemplo visual:
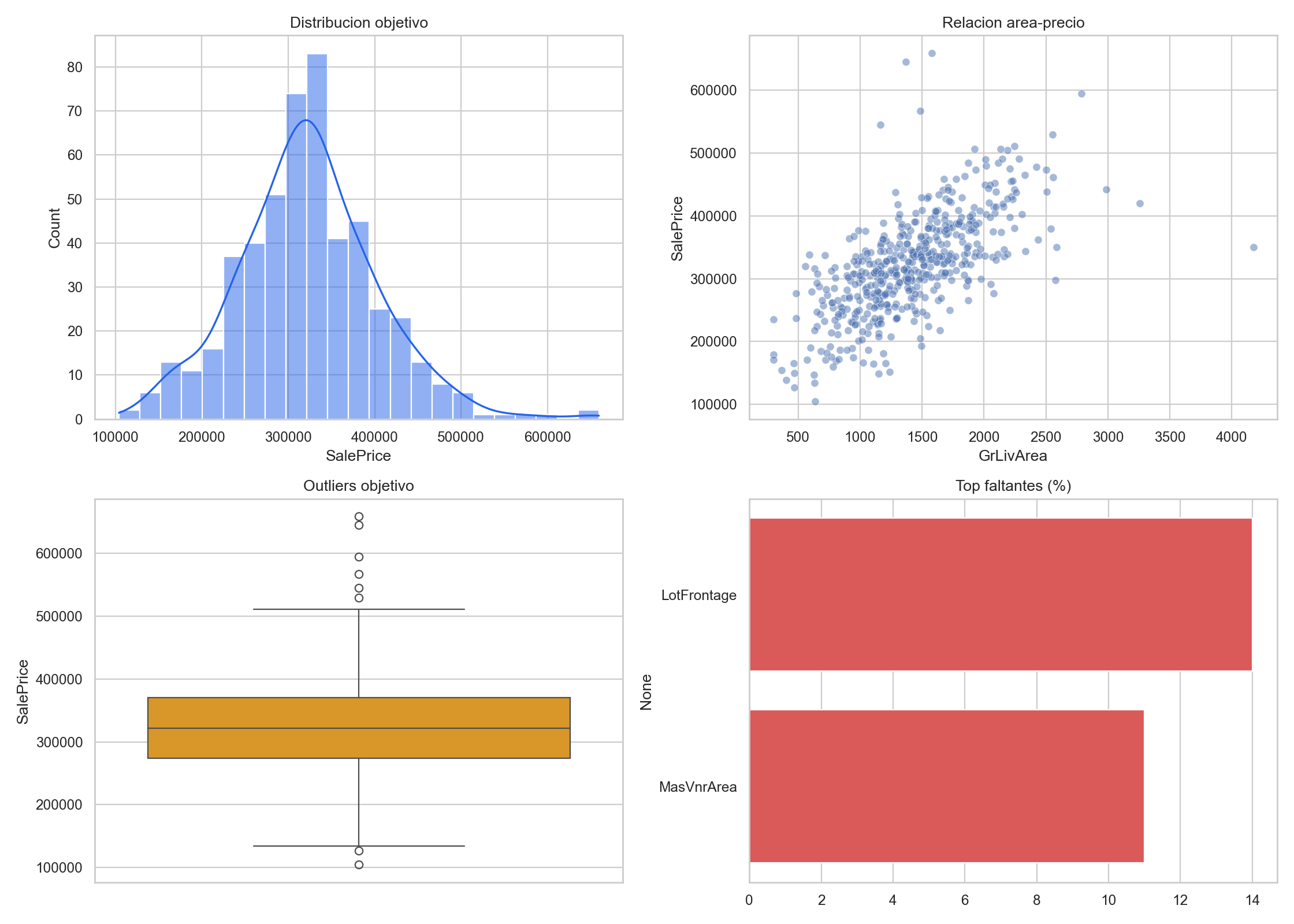
11) Que grafico usar segun la pregunta
- Distribucion de una variable: histograma + KDE.
- Outliers de una variable: boxplot.
- Relacion entre dos numericas: scatter / regplot.
- Comparar categoria vs numerica: boxplot/violin/barplot de agregados.
- Correlaciones entre muchas numericas: heatmap.
- Faltantes por columna: barplot horizontal.
- Evolucion temporal: lineplot.
12) Recomendaciones de competencia
- Empieza por 5 graficos de alto valor, no 50 graficos sin conclusion.
- Cada grafico debe responder una pregunta concreta.
- Guarda conclusiones en texto debajo de cada figura.
- Traduce hallazgos en acciones de modelado:
- transformaciones (
log1p, escalado) - limpieza de outliers
- nuevas features
- exclusion de columnas no utiles
- transformaciones (
Codigo de plantilla EDA reutilizable
def eda_report(df: pd.DataFrame, target_col: str):
print("Shape:", df.shape)
print("Missing top 10:\n", df.isna().sum().sort_values(ascending=False).head(10))
fig, axes = plt.subplots(1, 3, figsize=(18, 5))
sns.histplot(df[target_col].dropna(), kde=True, ax=axes[0], color="#2563eb")
axes[0].set_title("Target distribution")
num_cols = df.select_dtypes(include=["number"]).columns
if len(num_cols) > 1:
x_col = [c for c in num_cols if c != target_col][0]
sns.scatterplot(data=df, x=x_col, y=target_col, alpha=0.5, ax=axes[1])
axes[1].set_title(f"{x_col} vs {target_col}")
missing_pct = (df.isna().mean() * 100).sort_values(ascending=False).head(10)
sns.barplot(x=missing_pct.values, y=missing_pct.index, ax=axes[2], color="#ef4444")
axes[2].set_title("Missing (%)")
plt.tight_layout()
plt.show()
Por que importa en competencias de IA
Permite detectar leakage, columnas inutiles, sesgos de muestreo y transformaciones necesarias.
Recursos recomendados
- Documentacion de Matplotlib: referencia completa con galeria de ejemplos
- Documentacion de Seaborn: visualizaciones estadisticas con menos codigo
- Kaggle Learn — Data Visualization: curso interactivo con Seaborn
- From Data to Viz: guia de decision sobre que grafico usar segun tipo de datos
- Kaggle — House Prices: excelente dataset para practicar EDA y visualizacion
Ejercicios practicos
- Generar dashboard EDA de un dataset tabular.
- Identificar variables altamente correlacionadas.
- Detectar outliers y justificar su tratamiento.
Mini-proyectos
- Reporte EDA reproducible (notebook + conclusiones) para una competencia.
Como resolver el mini-proyecto (resumen practico)
Objetivo: crear un EDA claro, breve y accionable para iniciar modelado con ventaja.
Pasos sugeridos:
- Cargar dataset y documentar dimensiones, tipos y faltantes.
- Graficar distribucion de target (original y transformada si aplica).
- Identificar variables numericas mas correlacionadas con target.
- Analizar al menos 2 variables categoricas relevantes.
- Detectar outliers y definir criterio de tratamiento.
- Cerrar con lista de acciones para el pipeline de modelado.
Entregable recomendado:
- Notebook limpio y ejecutable de principio a fin.
- Seccion final “Hallazgos y decisiones”:
- transformaciones
- features propuestas
- columnas a eliminar
- riesgos detectados (leakage, drift, faltantes)
Ejemplo de cierre de reporte:
1) SalePrice presenta sesgo positivo, se recomienda log1p.
2) GrLivArea y OverallQual tienen alta relacion con target.
3) LotFrontage tiene faltantes altos, imputar mediana + flag de faltante.
4) Se detectan outliers extremos en GrLivArea, revisar criterio de recorte.
Errores comunes
- Graficar por rutina, sin preguntas concretas.
- Ignorar escalas y normalizacion visual.
- Sacar conclusiones causales de simples correlaciones.
Seccion avanzada (opcional)
Construye visualizaciones interactivas con Plotly para comunicar hallazgos al equipo.
Ruta sugerida
- Histogramas y boxplots.
- Correlaciones y scatter matrices.
- Reporte de hallazgos accionables para modelado.
Desarrollo extendido para estudio profundo
Que debes comprender de verdad
No basta con leer definiciones. En este tema debes llegar a tres niveles de dominio:
- Nivel conceptual: explicar el tema sin mirar apuntes.
- Nivel tecnico: implementar lo aprendido en codigo o en ejercicios formales.
- Nivel estrategico: decidir cuando usar esta herramienta en una competencia.
Una forma util de estudiar es la secuencia “leer -> resumir -> implementar -> explicar”. Si no puedes explicar una idea con palabras simples, todavia no la dominaste.
Aplicacion paso a paso en un entorno de competencia
- Define objetivo y metrica antes de tocar el modelo.
- Prepara un baseline pequeno y completamente reproducible.
- Evalua con separacion correcta de datos.
- Registra decisiones y resultados por experimento.
- Repite solo cambios pequenos para aislar el impacto.
Este flujo te entrena para competir bajo presion sin perder rigor metodologico.
Checklist de dominio minimo
- Puedo describir el concepto central del tema con mis palabras.
- Puedo resolver un ejercicio basico sin ayuda externa.
- Puedo identificar al menos dos errores frecuentes del tema.
- Puedo conectar este tema con uno anterior de la ruta.
- Puedo escribir una implementacion limpia y comentada.
Autoevaluacion sugerida
Responde por escrito:
- Cual es la idea principal del tema y por que importa.
- Que decisiones tomarias al aplicarlo en un problema real.
- Que senales te indican que estas aplicando mal el enfoque.
- Como validarias que tu solucion funciona de verdad.
Plan de practica de 7 dias
- Dia 1: lectura completa + resumen personal.
- Dia 2: ejercicios basicos.
- Dia 3: ejercicios intermedios.
- Dia 4: mini-proyecto parte 1.
- Dia 5: mini-proyecto parte 2.
- Dia 6: analisis de errores + refactor.
- Dia 7: presentacion breve de resultados.
Navegacion
← 3. Manejo de Datos con NumPy y Pandas | 5. Introduccion a Machine Learning →