18. Series Temporales y Datos Secuenciales
Por que las series temporales son un caso especial
En un dataset tabular clasico, las filas son independientes entre si: el registro del cliente 500 no depende del 499. En una serie temporal, el orden importa: el valor de hoy depende del de ayer, y el de ayer depende del de anteayer. Ignorar esa dependencia produce modelos que parecen funcionar bien en entrenamiento pero fallan completamente en produccion.
El segundo error tipico es mas sutil: filtrar informacion del futuro al pasado (leakage temporal). Si normalizas toda la serie con la media total antes de hacer el split train/test, el modelo de entrenamiento ya “vio” valores futuros. El resultado es un score inflado que no se replica en el mundo real.
Las series temporales tienen sus propias reglas de juego: validacion temporal, features de lag, estacionariedad, y estrategias de forecasting multi-step. Este tema las cubre todas.
1. Componentes de una serie temporal
Toda serie temporal puede descomponerse en:
- T_t (Tendencia): la direccion a largo plazo. Puede ser lineal, exponencial, o cambiante.
- S_t (Estacionalidad): patrones que se repiten con una frecuencia fija. Puede haber multiples periodos (diario dentro de semanal dentro de anual).
- R_t (Residuo): lo que no explica ni la tendencia ni la estacionalidad.
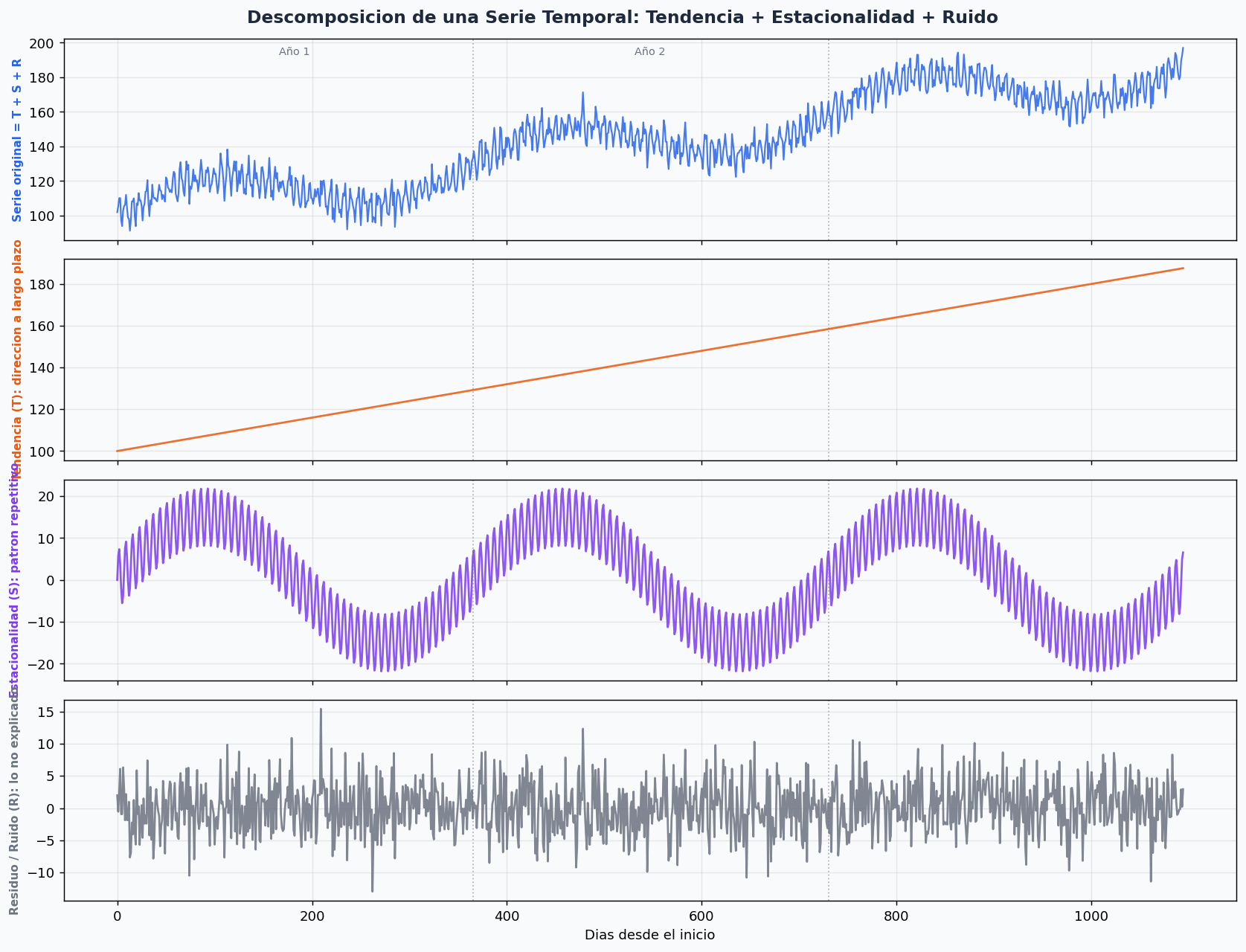
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.seasonal import STL, seasonal_decompose
# ── Descomposicion clasica (additive / multiplicative) ────────────────────────
# additive: y_t = T + S + R (cuando la amplitud de S es constante)
# multiplicative: y_t = T * S * R (cuando S crece con la tendencia)
serie = pd.read_csv("ventas_diarias.csv", index_col="fecha", parse_dates=True)["ventas"]
decomp = seasonal_decompose(serie, model="additive", period=365)
fig, axes = plt.subplots(4, 1, figsize=(12, 8), sharex=True)
for ax, data, titulo in zip(axes,
[serie, decomp.trend, decomp.seasonal, decomp.resid],
["Original", "Tendencia", "Estacionalidad", "Residuo"]):
ax.plot(data, lw=1.2)
ax.set_title(titulo)
plt.tight_layout()
# ── STL: descomposicion robusta (recomendada en competencias) ─────────────────
# STL = Seasonal and Trend decomposition using Loess
# Ventajas: maneja outliers, estacionalidad variable, mas flexible que seasonal_decompose
stl = STL(serie, period=365, robust=True)
resultado = stl.fit()
fig = resultado.plot()
# Acceder a los componentes por separado
tendencia = resultado.trend
estacional = resultado.seasonal
residuo = resultado.resid
# ── Test de estacionariedad (Augmented Dickey-Fuller) ─────────────────────────
from statsmodels.tsa.stattools import adfuller, kpss
def test_estacionariedad(serie, nombre="serie"):
"""
Aplica ADF y KPSS para determinar si la serie es estacionaria.
Interpretacion:
ADF: H0 = tiene raiz unitaria (NO estacionaria)
p < 0.05 => rechazar H0 => serie ES estacionaria
KPSS: H0 = estacionaria
p < 0.05 => rechazar H0 => serie NO ES estacionaria
"""
print(f"\nTest de Estacionariedad: {nombre}")
# ADF
adf_stat, adf_p, _, _, adf_vals, _ = adfuller(serie.dropna())
print(f" ADF statistic: {adf_stat:.4f} p-value: {adf_p:.4f}")
print(f" ADF Criticos: {adf_vals}")
print(f" ADF Conclusion: {'ESTACIONARIA' if adf_p < 0.05 else 'NO estacionaria'}")
# KPSS
kpss_stat, kpss_p, _, kpss_vals = kpss(serie.dropna(), regression="c")
print(f" KPSS statistic: {kpss_stat:.4f} p-value: {kpss_p:.4f}")
print(f" KPSS Conclusion: {'NO estacionaria' if kpss_p < 0.05 else 'ESTACIONARIA'}")
# Si no es estacionaria, aplicar diferenciacion
if adf_p >= 0.05:
print(f"\n Aplicar differencing:")
serie_diff = serie.diff().dropna()
test_estacionariedad(serie_diff, f"{nombre} (diff=1)")
# Ejemplo de uso
# test_estacionariedad(serie, "ventas_diarias")
2. La ventana deslizante: de serie a problema supervisado
El truco fundamental para usar cualquier modelo de ML en series temporales es transformar la serie en un dataset con features y target.
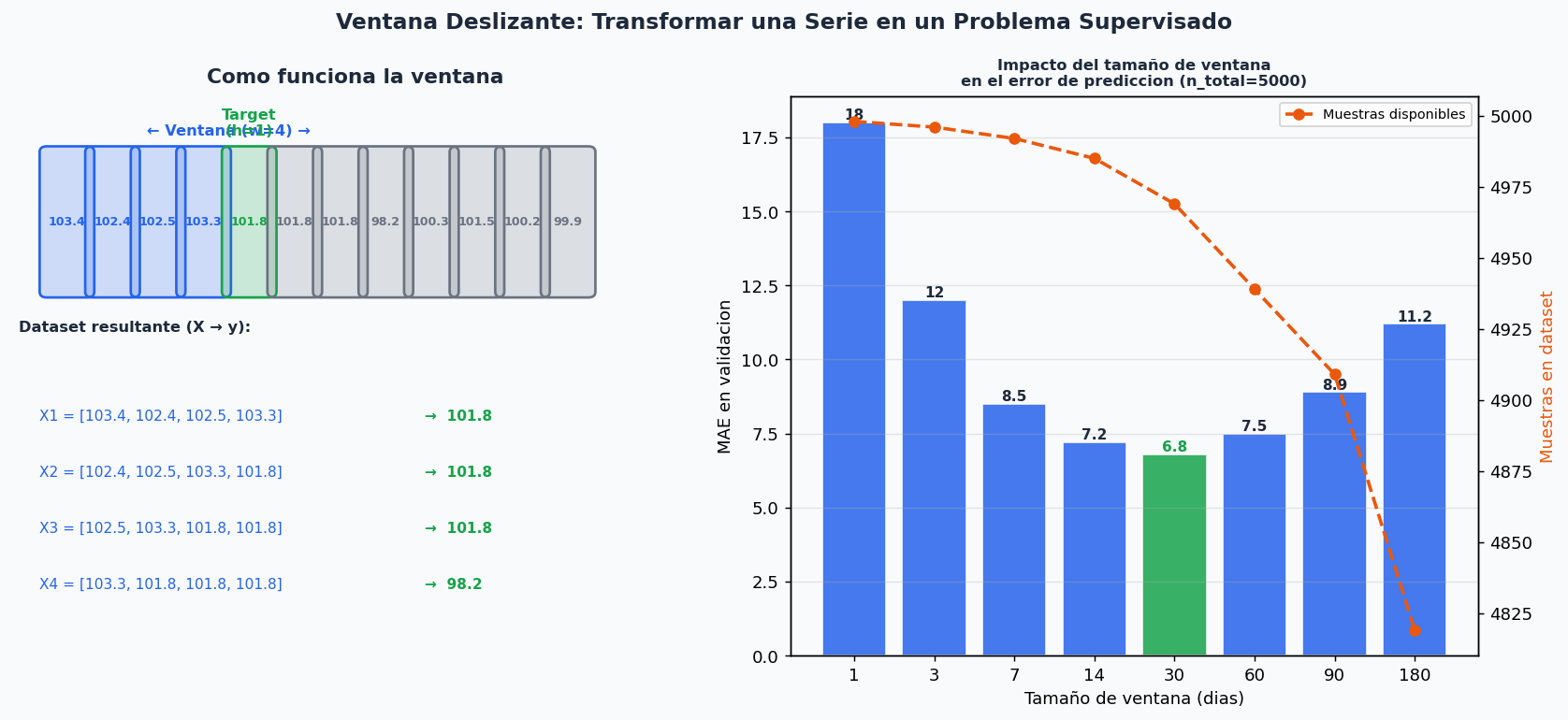
import numpy as np
import pandas as pd
from typing import Tuple
def crear_dataset_ventana(
serie: np.ndarray,
window: int,
horizonte: int = 1,
stride: int = 1,
) -> Tuple[np.ndarray, np.ndarray]:
"""
Convierte una serie 1D en un dataset supervisado con ventana deslizante.
Params:
serie: array 1D de valores temporales
window: numero de pasos pasados como features (X)
horizonte: numero de pasos futuros a predecir (y)
stride: paso entre ventanas (1 = todas las ventanas posibles)
Returns:
X: [n_muestras, window]
y: [n_muestras, horizonte]
Ejemplo:
serie = [1, 2, 3, 4, 5, 6, 7], window=3, horizonte=2
X = [[1,2,3], [2,3,4], [3,4,5]]
y = [[4,5], [5,6], [6,7]]
"""
X, y = [], []
n = len(serie)
for i in range(0, n - window - horizonte + 1, stride):
X.append(serie[i: i + window])
y.append(serie[i + window: i + window + horizonte])
return np.array(X), np.array(y)
def crear_dataset_multivariado(
df: pd.DataFrame,
target_col: str,
feature_cols: list,
window: int,
horizonte: int = 1,
) -> Tuple[np.ndarray, np.ndarray]:
"""
Dataset con ventana deslizante para series multivariadas.
X tiene forma [n_muestras, window, n_features]
y tiene forma [n_muestras, horizonte]
"""
n = len(df)
X, y = [], []
features = df[feature_cols].values
target = df[target_col].values
for i in range(n - window - horizonte + 1):
X.append(features[i: i + window])
y.append(target[i + window: i + window + horizonte])
return np.array(X), np.array(y) # X: [n, w, f], y: [n, h]
# Ejemplo de uso
np.random.seed(42)
serie_ejemplo = np.cumsum(np.random.randn(200)) + 100
X, y = crear_dataset_ventana(serie_ejemplo, window=30, horizonte=7)
print(f"X shape: {X.shape}") # [163, 30]
print(f"y shape: {y.shape}") # [163, 7]
# Separar train/test TEMPORALMENTE (nunca aleatorio)
split = int(len(X) * 0.8)
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]
print(f"Train: {X_train.shape}, Test: {X_test.shape}")
3. Validacion temporal correcta
La regla mas importante: el tiempo siempre fluye hacia adelante. Validar con un split aleatorio produce leakage temporal — el modelo aprende de datos futuros, su score es irreal.
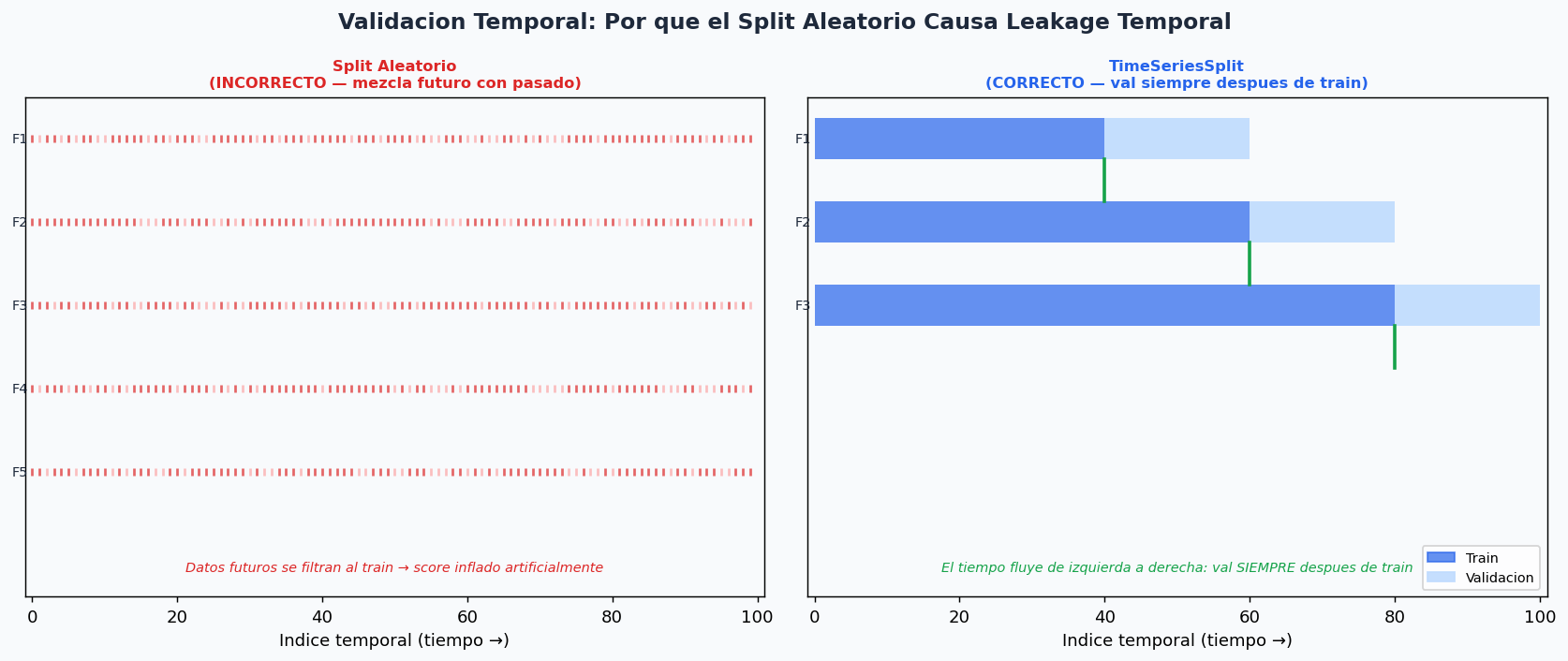
from sklearn.model_selection import TimeSeriesSplit, cross_val_score
import numpy as np
# ── TimeSeriesSplit: la forma correcta ───────────────────────────────────────
# Cada fold: train = todos los datos hasta el punto de corte
# val = los siguientes n_steps pasos
tscv = TimeSeriesSplit(n_splits=5)
# Verificar que los folds son correctos (train antes de val)
for fold, (train_idx, val_idx) in enumerate(tscv.split(X_train)):
print(f"Fold {fold+1}: train[{train_idx[0]}:{train_idx[-1]}] "
f"val[{val_idx[0]}:{val_idx[-1]}]")
assert train_idx[-1] < val_idx[0], "Error: val solapado con train"
# Uso con sklearn
from lightgbm import LGBMRegressor
modelo = LGBMRegressor(n_estimators=300, learning_rate=0.05, verbose=-1)
scores = cross_val_score(modelo, X_train, y_train[:, 0],
cv=tscv, scoring="neg_mean_absolute_error")
print(f"CV MAE: {-scores.mean():.4f} ± {scores.std():.4f}")
# ── Walk-Forward Validation (mas realista para produccion) ───────────────────
# Simula el uso real: re-entrena en cada ventana de tiempo
def walk_forward_validation(X, y, modelo_factory, test_size=30, min_train=100):
"""
Walk-forward validation: re-entrena el modelo en cada paso.
modelo_factory: funcion que retorna un modelo nuevo (sin estado previo)
test_size: numero de pasos por ventana de validacion
min_train: numero minimo de muestras para empezar a entrenar
"""
n = len(X)
predicciones = []
reales = []
for start in range(min_train, n - test_size + 1, test_size):
X_tr = X[:start]
y_tr = y[:start, 0]
X_val = X[start: start + test_size]
y_val = y[start: start + test_size, 0]
modelo = modelo_factory()
modelo.fit(X_tr, y_tr)
preds = modelo.predict(X_val)
predicciones.extend(preds)
reales.extend(y_val)
preds_arr = np.array(predicciones)
reales_arr = np.array(reales)
mae = np.mean(np.abs(preds_arr - reales_arr))
rmse = np.sqrt(np.mean((preds_arr - reales_arr)**2))
print(f"Walk-forward: MAE={mae:.4f} RMSE={rmse:.4f} n={len(preds_arr)}")
return preds_arr, reales_arr
# Uso
from lightgbm import LGBMRegressor
resultados = walk_forward_validation(
X, y,
modelo_factory=lambda: LGBMRegressor(n_estimators=200, learning_rate=0.05, verbose=-1),
test_size=20, min_train=80,
)
4. ACF y PACF: diagnosticar la estructura temporal
Antes de elegir el modelo, analiza la autocorrelacion: cuantos pasos atras tiene dependencia significativa la serie?
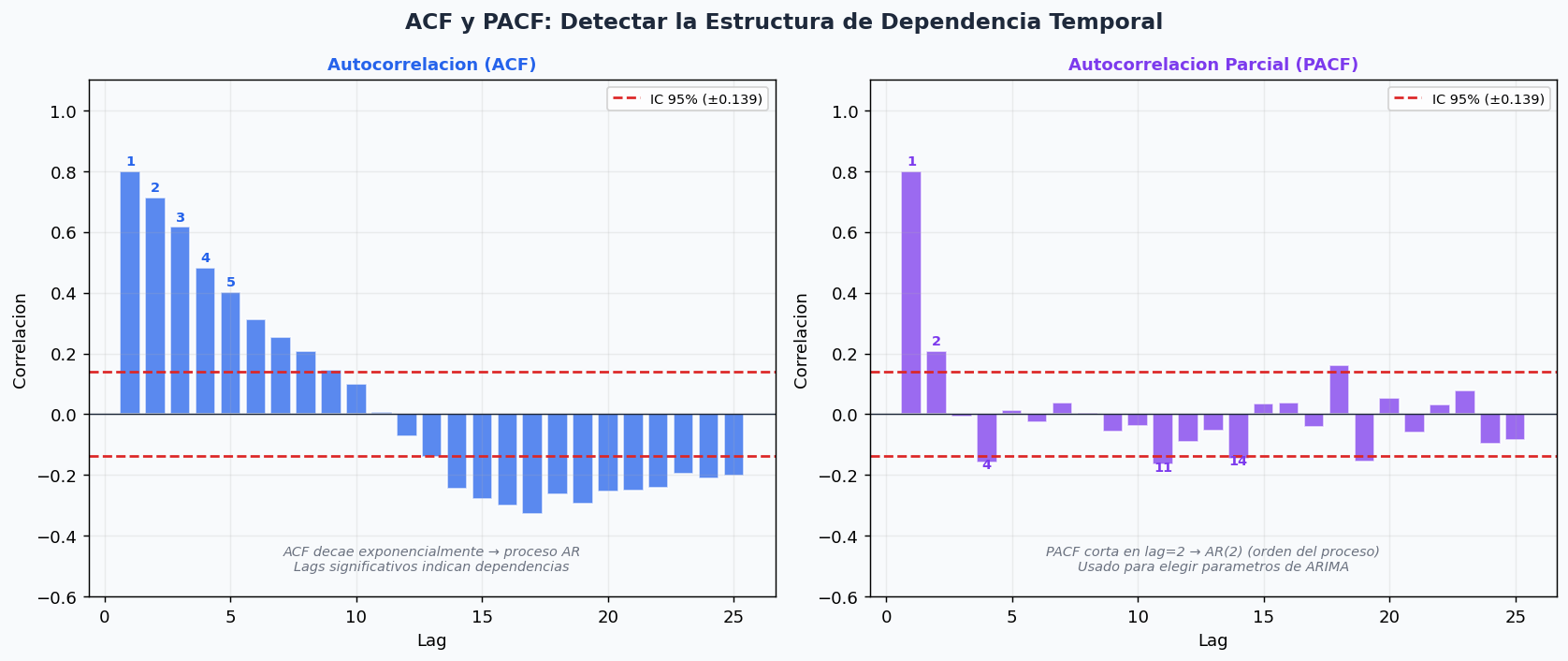
- ACF (Autocorrelation Function): correlacion entre yt y y{t-k} para cada lag k. Si la ACF decae exponencialmente → proceso AR. Si corta abruptamente → proceso MA.
- PACF (Partial ACF): correlacion entre yt y y{t-k} eliminando el efecto de los lags intermedios. Si la PACF corta en k=p, el orden del proceso AR es p.
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.stattools import acf, pacf
def diagnostico_autocorrelacion(serie, max_lags=40, alpha=0.05):
"""
Genera graficos ACF y PACF y sugiere el orden del modelo ARIMA.
"""
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
plot_acf(serie.dropna(), lags=max_lags, alpha=alpha, ax=axes[0])
plot_pacf(serie.dropna(), lags=max_lags, alpha=alpha, ax=axes[1])
axes[0].set_title("ACF"); axes[1].set_title("PACF")
plt.tight_layout()
# Identificar lags significativos
acf_vals, acf_ci = acf(serie.dropna(), nlags=max_lags, alpha=alpha)
pacf_vals, pacf_ci = pacf(serie.dropna(), nlags=max_lags, alpha=alpha)
conf_int = 1.96 / np.sqrt(len(serie.dropna()))
lags_acf_sig = [k for k in range(1, max_lags+1) if abs(acf_vals[k]) > conf_int]
lags_pacf_sig = [k for k in range(1, max_lags+1) if abs(pacf_vals[k]) > conf_int]
print(f"Lags ACF significativos: {lags_acf_sig[:10]}")
print(f"Lags PACF significativos: {lags_pacf_sig[:10]}")
# Heuristica de orden ARIMA
if len(lags_pacf_sig) <= 3:
p = lags_pacf_sig[-1] if lags_pacf_sig else 1
q = 0
print(f"Heuristica: AR({p}) → ARIMA({p}, 0, {q})")
else:
print("PACF no corta limpio → considera diferenciar o usar SARIMA")
return lags_acf_sig, lags_pacf_sig
5. Modelos estadisticos: ARIMA y Prophet
ARIMA para series univariadas
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.tsa.statespace.sarimax import SARIMAX
import warnings
warnings.filterwarnings("ignore")
def ajustar_arima(serie_train, serie_test, p=1, d=1, q=0,
P=1, D=1, Q=1, m=12):
"""
Ajusta SARIMA(p,d,q)(P,D,Q)[m] y evalua en test.
SARIMA agrega componentes estacionales:
p,d,q: parametros no estacionales (AR, diferenciacion, MA)
P,D,Q: parametros estacionales
m: periodo de la estacionalidad (12=mensual, 52=semanal, 365=diario)
"""
modelo = SARIMAX(serie_train, order=(p, d, q),
seasonal_order=(P, D, Q, m),
enforce_stationarity=False,
enforce_invertibility=False)
resultado = modelo.fit(disp=False)
# Forecast sobre el periodo de test
n_steps = len(serie_test)
pred_obj = resultado.get_forecast(steps=n_steps)
predicciones = pred_obj.predicted_mean
ic = pred_obj.conf_int(alpha=0.05)
mae = np.mean(np.abs(predicciones.values - serie_test.values))
rmse = np.sqrt(np.mean((predicciones.values - serie_test.values)**2))
print(f"SARIMA({p},{d},{q})({P},{D},{Q})[{m}]:")
print(f" MAE={mae:.4f} RMSE={rmse:.4f} AIC={resultado.aic:.2f}")
return resultado, predicciones, ic
# Auto-ARIMA: buscar automaticamente el mejor orden
# pip install pmdarima
from pmdarima import auto_arima
def auto_ajustar_arima(serie_train, m=12):
"""auto_arima busca p, d, q, P, D, Q por criterio de informacion (AIC)."""
modelo = auto_arima(
serie_train,
seasonal=True, m=m,
stepwise=True, # busqueda eficiente (no grid completo)
information_criterion="aic",
trace=True, # imprime el proceso de busqueda
error_action="ignore",
suppress_warnings=True,
)
print(f"Mejor modelo: {modelo.order}, estacional: {modelo.seasonal_order}")
return modelo
Prophet: tendencia + estacionalidad + feriados
# pip install prophet
from prophet import Prophet
import pandas as pd
def forecast_prophet(df_train, df_test, freq="D",
estacionalidad_anual=True,
estacionalidad_semanal=True,
feriados_pais="BO"):
"""
Forecasting con Prophet.
df_train/df_test deben tener columnas 'ds' (fecha) y 'y' (valor).
"""
modelo = Prophet(
yearly_seasonality=estacionalidad_anual,
weekly_seasonality=estacionalidad_semanal,
daily_seasonality=False,
seasonality_mode="additive", # o "multiplicative" si la amplitud crece
)
# Agregar feriados de Bolivia
if feriados_pais:
modelo.add_country_holidays(country_name=feriados_pais)
# Estacionalidad mensual custom (no incluida por defecto)
modelo.add_seasonality(name="mensual", period=30.5, fourier_order=5)
modelo.fit(df_train)
# Crear dataframe de fechas futuras
future = modelo.make_future_dataframe(periods=len(df_test), freq=freq)
forecast = modelo.predict(future)
# Evaluacion
pred_test = forecast.tail(len(df_test))["yhat"].values
real_test = df_test["y"].values
mae = np.mean(np.abs(pred_test - real_test))
rmse = np.sqrt(np.mean((pred_test - real_test)**2))
print(f"Prophet: MAE={mae:.4f} RMSE={rmse:.4f}")
# Visualizacion
fig1 = modelo.plot(forecast)
fig2 = modelo.plot_components(forecast) # tendencia + estacionalidades
return modelo, forecast
# Preparar datos para Prophet (columnas ds y y obligatorias)
# df_prophet = pd.DataFrame({"ds": serie.index, "y": serie.values})
# train_p = df_prophet.iloc[:-30]
# test_p = df_prophet.iloc[-30:]
# modelo, forecast = forecast_prophet(train_p, test_p)
6. Modelos ML con features de lag: el enfoque mas competitivo
La estrategia que gana la mayoria de competencias de series temporales no es LSTM ni ARIMA — es LightGBM o XGBoost con buenos features de lag. La ventaja: puede capturar relaciones no lineales entre lags, features de calendario, y variables exogenas, sin requerir supuestos de linealidad.
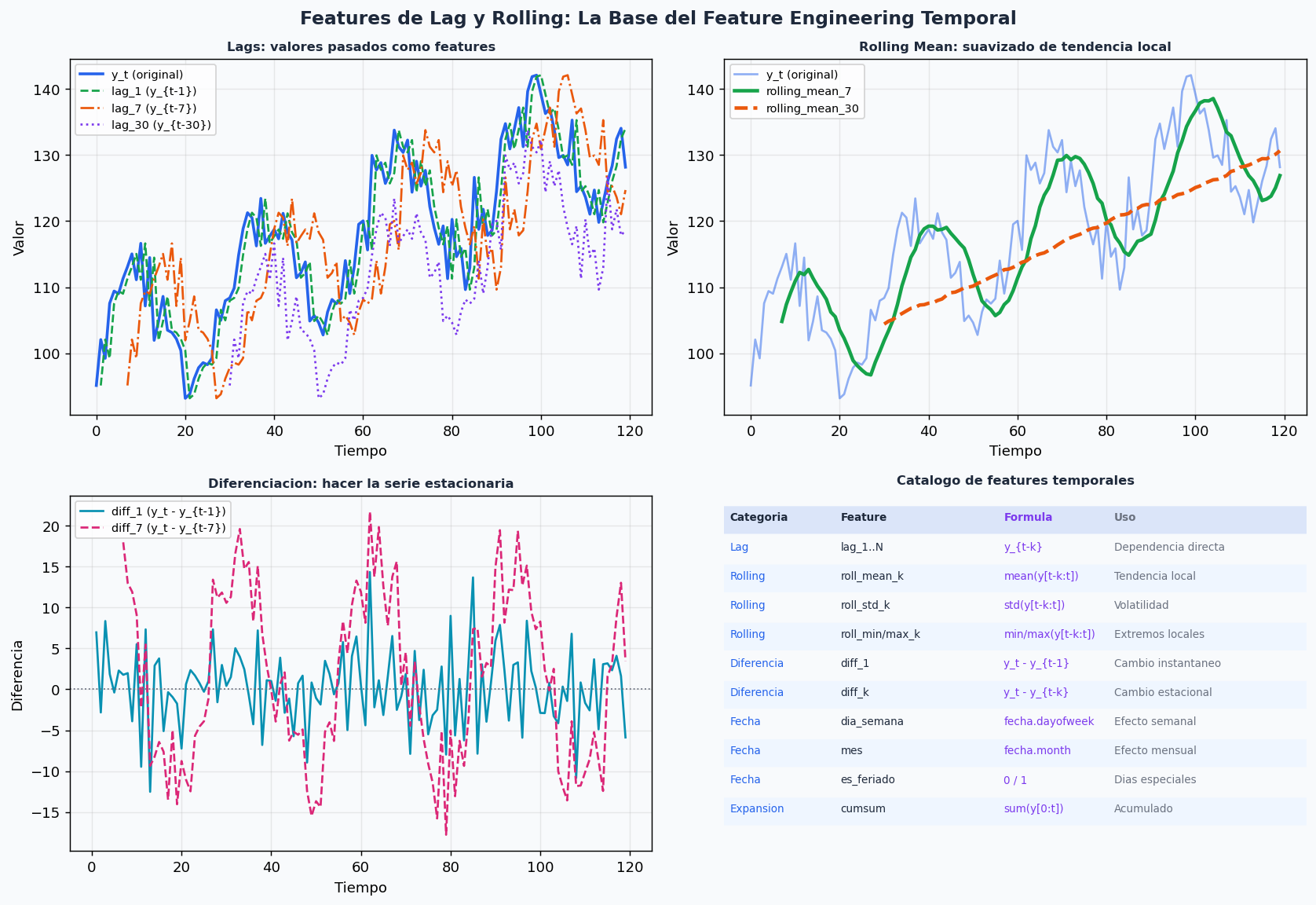
import pandas as pd
import numpy as np
from lightgbm import LGBMRegressor
from sklearn.metrics import mean_absolute_error
def crear_features_temporales(df: pd.DataFrame, target_col: str,
lags: list, rolling_windows: list) -> pd.DataFrame:
"""
Crea features de lag, rolling y calendario para un DataFrame con DatetimeIndex.
Params:
df: DataFrame con DatetimeIndex
target_col: nombre de la columna objetivo
lags: lista de lags a crear [1, 7, 14, 28, ...]
rolling_windows: lista de ventanas para rolling stats [7, 30, 90]
IMPORTANTE: siempre crear features hacia ATRAS en el tiempo.
Nunca usar valores de t+k para predecir t.
"""
df = df.copy()
y = df[target_col]
# ── Features de Lag ──────────────────────────────────────────────────────
for lag in lags:
df[f"lag_{lag}"] = y.shift(lag)
df[f"diff_lag_{lag}"] = y.diff(lag) # y_t - y_{t-lag}
# ── Features de Rolling ──────────────────────────────────────────────────
for window in rolling_windows:
# Usar shift(1) para evitar look-ahead: la ventana no incluye el dia actual
rol = y.shift(1).rolling(window, min_periods=1)
df[f"roll_mean_{window}"] = rol.mean()
df[f"roll_std_{window}"] = rol.std()
df[f"roll_min_{window}"] = rol.min()
df[f"roll_max_{window}"] = rol.max()
df[f"roll_median_{window}"] = rol.median()
df[f"roll_skew_{window}"] = rol.skew()
# ── Features de Fecha ────────────────────────────────────────────────────
idx = df.index
df["dia_semana"] = idx.dayofweek # 0=Lunes, 6=Domingo
df["mes"] = idx.month
df["dia_mes"] = idx.day
df["semana_anio"] = idx.isocalendar().week.astype(int)
df["trimestre"] = idx.quarter
df["es_fin_semana"] = (idx.dayofweek >= 5).astype(int)
df["dia_anio"] = idx.dayofyear
# Codificacion ciclica (para que enero y diciembre sean "vecinos")
df["mes_sin"] = np.sin(2 * np.pi * df["mes"] / 12)
df["mes_cos"] = np.cos(2 * np.pi * df["mes"] / 12)
df["dia_sem_sin"] = np.sin(2 * np.pi * df["dia_semana"] / 7)
df["dia_sem_cos"] = np.cos(2 * np.pi * df["dia_semana"] / 7)
# ── Features de Tendencia local ──────────────────────────────────────────
for window in rolling_windows:
# Pendiente de la tendencia local (regresion lineal sobre la ventana)
df[f"trend_{window}"] = (
y.shift(1).rolling(window).apply(
lambda x: np.polyfit(np.arange(len(x)), x, 1)[0]
if len(x) == window else np.nan,
raw=True
)
)
return df
def pipeline_forecast_ml(df_train: pd.DataFrame, df_test: pd.DataFrame,
target_col: str,
lags=None, rolling_windows=None):
"""
Pipeline completo: features temporales + LGBM + evaluacion.
Respeta la separacion temporal: features se calculan SOLO sobre train.
"""
if lags is None:
lags = [1, 2, 3, 7, 14, 21, 28]
if rolling_windows is None:
rolling_windows = [7, 14, 30, 90]
# Concatenar para calcular features correctamente en el limite train/test
# (los primeros 'max_lag' dias del test necesitan valores del train para sus lags)
df_total = pd.concat([df_train, df_test])
df_total = crear_features_temporales(df_total, target_col, lags, rolling_windows)
df_total.dropna(inplace=True) # eliminar filas con NaN por los lags iniciales
n_train = len(df_train)
X_tr = df_total.iloc[:n_train].drop(columns=[target_col])
y_tr = df_total.iloc[:n_train][target_col]
X_te = df_total.iloc[n_train:].drop(columns=[target_col])
y_te = df_total.iloc[n_train:][target_col]
# Asegurar que los splits son temporales (no hay solapamiento)
assert X_tr.index[-1] < X_te.index[0], "Error: datos de test antes de train"
modelo = LGBMRegressor(
n_estimators=500,
learning_rate=0.05,
num_leaves=31,
min_child_samples=20,
subsample=0.8,
colsample_bytree=0.8,
random_state=42,
verbose=-1,
)
modelo.fit(X_tr, y_tr,
eval_set=[(X_te, y_te)],
callbacks=[])
pred = modelo.predict(X_te)
mae = mean_absolute_error(y_te, pred)
rmse = np.sqrt(np.mean((pred - y_te.values)**2))
mape = np.mean(np.abs((pred - y_te.values) / (y_te.values + 1e-8))) * 100
print(f"LGBM con features temporales:")
print(f" MAE={mae:.4f} RMSE={rmse:.4f} MAPE={mape:.2f}%")
print(f" n_features={X_tr.shape[1]}")
# Importancia de features
feat_imp = pd.Series(
modelo.feature_importances_,
index=X_tr.columns
).sort_values(ascending=False)
print(f"\nTop 10 features:\n{feat_imp.head(10)}")
return modelo, pred, y_te, feat_imp
7. Comparacion de modelos y estrategias
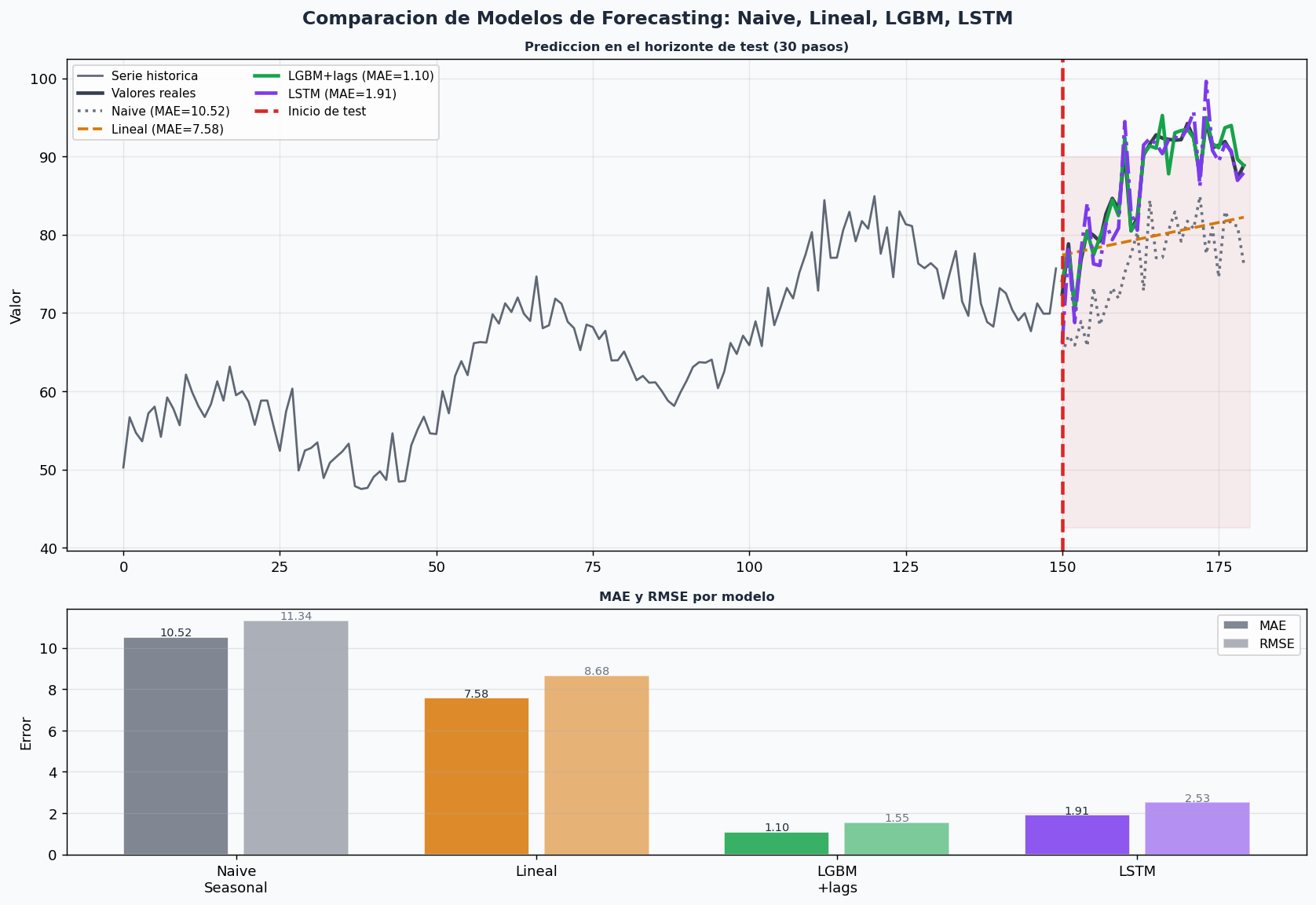
Baselines que nunca debes omitir
import numpy as np
from sklearn.metrics import mean_absolute_error
class BaselinesForecast:
"""
Coleccion de baselines para series temporales.
Siempre calcula estos antes de construir modelos complejos.
"""
@staticmethod
def naive_ultimo(y_train, n_steps):
"""Repite el ultimo valor de train."""
return np.full(n_steps, y_train[-1])
@staticmethod
def naive_seasonal(y_train, n_steps, periodo=7):
"""Repite el ultimo ciclo completo."""
preds = []
for i in range(n_steps):
idx = len(y_train) - periodo + (i % periodo)
if idx >= 0:
preds.append(y_train[idx])
else:
preds.append(y_train[-1])
return np.array(preds)
@staticmethod
def media_movil(y_train, n_steps, ventana=30):
"""Prediccion fija = media de los ultimos 'ventana' valores."""
return np.full(n_steps, np.mean(y_train[-ventana:]))
@staticmethod
def tendencia_lineal(y_train, n_steps):
"""Extrapolacion lineal."""
x = np.arange(len(y_train))
coef = np.polyfit(x, y_train, 1)
x_fut = np.arange(len(y_train), len(y_train) + n_steps)
return np.polyval(coef, x_fut)
@classmethod
def comparar(cls, y_train, y_test, periodo_estacional=7):
"""Evalua todos los baselines y retorna el mejor."""
n_steps = len(y_test)
baselines = {
"Naive ultimo": cls.naive_ultimo(y_train, n_steps),
"Naive seasonal": cls.naive_seasonal(y_train, n_steps, periodo_estacional),
"Media movil": cls.media_movil(y_train, n_steps),
"Tendencia lineal":cls.tendencia_lineal(y_train, n_steps),
}
resultados = {}
for nombre, pred in baselines.items():
mae = mean_absolute_error(y_test, pred)
rmse = np.sqrt(np.mean((pred - y_test)**2))
resultados[nombre] = {"MAE": mae, "RMSE": rmse}
print(f" {nombre:20s}: MAE={mae:.4f} RMSE={rmse:.4f}")
mejor = min(resultados, key=lambda k: resultados[k]["MAE"])
print(f"\n Mejor baseline: {mejor} (MAE={resultados[mejor]['MAE']:.4f})")
return resultados, mejor
# MASE: metrica relativa al naive (< 1.0 = mejor que naive)
def mase(y_true, y_pred, y_train, periodo=1):
"""
Mean Absolute Scaled Error.
Divide el MAE del modelo por el MAE del naive seasonal.
Valor < 1.0 significa que el modelo es mejor que el naive.
"""
mae_model = np.mean(np.abs(y_pred - y_true))
mae_naive = np.mean(np.abs(np.diff(y_train, n=periodo)))
return mae_model / mae_naive
8. RNN y LSTM con PyTorch
Los modelos recurrentes son la opcion cuando los patrones temporales son demasiado complejos para features manuales, o cuando la secuencia completa importa (no solo los ultimos k valores).
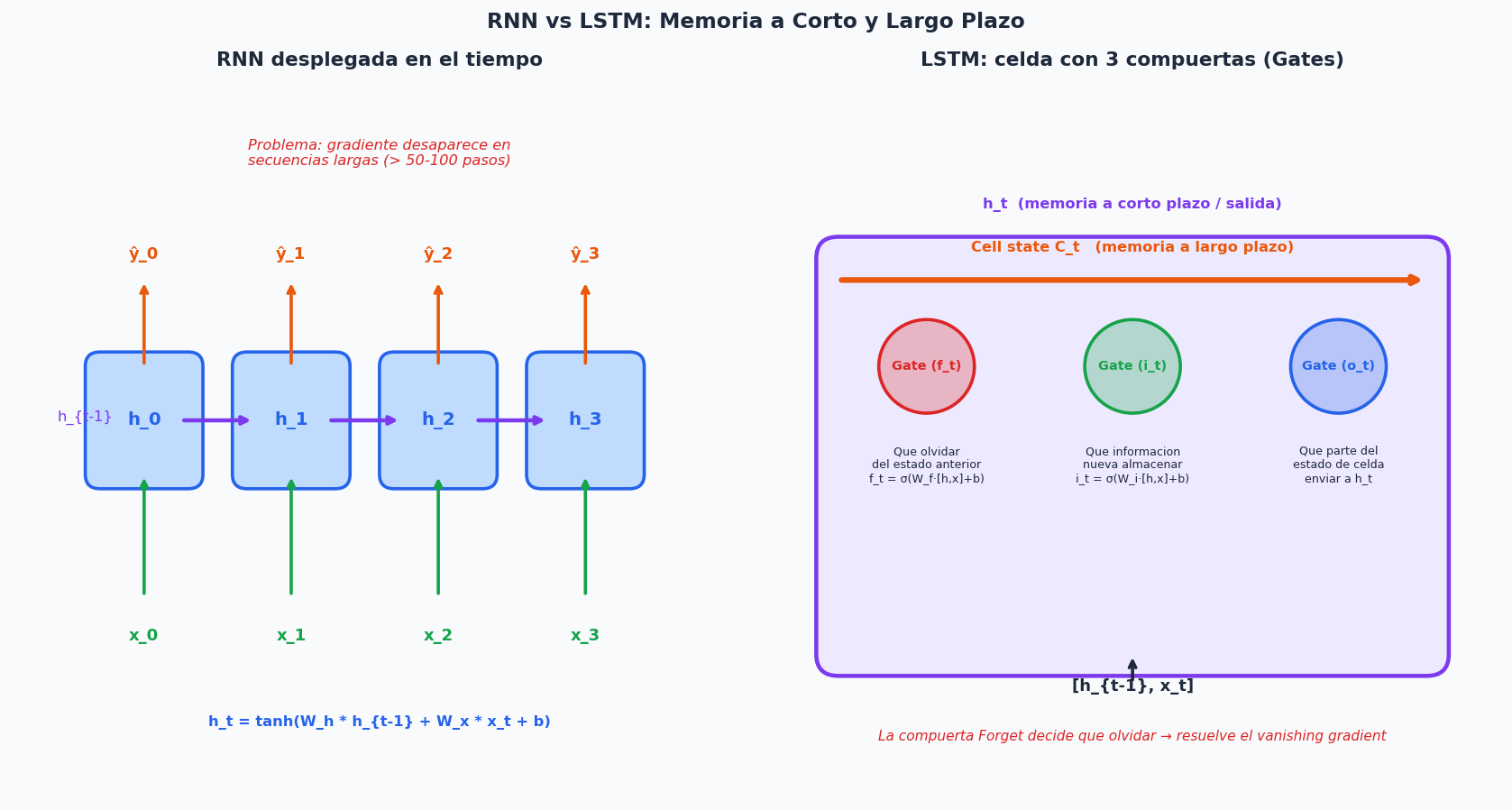
La clave del LSTM sobre la RNN simple: las compuertas controlan que informacion se recuerda y que se olvida, resolviendo el problema del gradiente que desaparece en secuencias largas.
donde f_t es la compuerta de olvido (forget gate): valores cercanos a 0 olvidan, cercanos a 1 recuerdan.
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import numpy as np
# ── Dataset temporal ─────────────────────────────────────────────────────────
class TimeSeriesDataset(Dataset):
def __init__(self, X: np.ndarray, y: np.ndarray):
"""
X: [n_muestras, window, n_features] — puede ser 2D si es univariado
y: [n_muestras] o [n_muestras, horizonte]
"""
if X.ndim == 2:
X = X[:, :, np.newaxis] # [n, window, 1]
self.X = torch.tensor(X, dtype=torch.float32)
self.y = torch.tensor(y, dtype=torch.float32)
def __len__(self):
return len(self.y)
def __getitem__(self, idx):
return self.X[idx], self.y[idx]
# ── Modelo LSTM ───────────────────────────────────────────────────────────────
class LSTMForecast(nn.Module):
"""
LSTM para forecasting de series temporales.
Arquitectura: LSTM → Dropout → Linear
"""
def __init__(self, input_size=1, hidden_size=64, num_layers=2,
horizonte=1, dropout=0.2):
super().__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(
input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True, # input: [batch, seq, features]
dropout=dropout if num_layers > 1 else 0.0,
)
self.dropout = nn.Dropout(dropout)
self.fc = nn.Linear(hidden_size, horizonte)
def forward(self, x):
"""
x: [batch, seq_len, input_size]
salida: [batch, horizonte]
"""
# Inicializar hidden state en ceros
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
# LSTM forward
out, (hn, cn) = self.lstm(x, (h0, c0))
# Usar solo el ultimo output de la secuencia
out = self.dropout(out[:, -1, :]) # [batch, hidden_size]
return self.fc(out) # [batch, horizonte]
# ── Modelo GRU (alternativa mas simple al LSTM) ───────────────────────────────
class GRUForecast(nn.Module):
"""GRU: similar a LSTM pero con menos parametros (sin cell state)."""
def __init__(self, input_size=1, hidden_size=64, num_layers=2,
horizonte=1, dropout=0.2):
super().__init__()
self.gru = nn.GRU(input_size, hidden_size, num_layers,
batch_first=True,
dropout=dropout if num_layers > 1 else 0.0)
self.dropout = nn.Dropout(dropout)
self.fc = nn.Linear(hidden_size, horizonte)
def forward(self, x):
out, _ = self.gru(x)
return self.fc(self.dropout(out[:, -1, :]))
# ── Loop de entrenamiento ─────────────────────────────────────────────────────
def entrenar_lstm(X_train, y_train, X_val, y_val,
hidden_size=64, num_layers=2, horizonte=1,
epochs=50, batch_size=64, lr=1e-3, patience=10):
"""
Entrena un modelo LSTM con early stopping.
X_train/X_val: arrays numpy [n, window] o [n, window, features]
y_train/y_val: arrays numpy [n] o [n, horizonte]
"""
device = "cuda" if torch.cuda.is_available() else "cpu"
# Preprocesamiento: normalizar la serie (LSTM es sensible a la escala)
from sklearn.preprocessing import StandardScaler
if X_train.ndim == 2:
n_samples_tr, window = X_train.shape
scaler = StandardScaler()
X_tr_2d = scaler.fit_transform(X_train) # fit SOLO en train
X_vl_2d = scaler.transform(X_val)
X_tr = X_tr_2d[:, :, np.newaxis]
X_vl = X_vl_2d[:, :, np.newaxis]
input_size = 1
else:
scaler = StandardScaler()
shape = X_train.shape
X_tr_r = scaler.fit_transform(X_train.reshape(-1, shape[-1]))
X_tr = X_tr_r.reshape(shape)
X_vl_r = scaler.transform(X_val.reshape(-1, shape[-1]))
X_vl = X_vl_r.reshape(X_val.shape)
input_size = shape[-1]
# Normalizar target
y_scaler = StandardScaler()
if y_train.ndim == 1:
y_tr = y_scaler.fit_transform(y_train.reshape(-1, 1)).flatten()
y_vl = y_scaler.transform(y_val.reshape(-1, 1)).flatten()
else:
y_tr = y_scaler.fit_transform(y_train)
y_vl = y_scaler.transform(y_val)
train_ds = TimeSeriesDataset(X_tr, y_tr)
val_ds = TimeSeriesDataset(X_vl, y_vl)
train_dl = DataLoader(train_ds, batch_size=batch_size, shuffle=True)
val_dl = DataLoader(val_ds, batch_size=batch_size, shuffle=False)
modelo = LSTMForecast(input_size=input_size, hidden_size=hidden_size,
num_layers=num_layers, horizonte=horizonte).to(device)
optimizer = torch.optim.Adam(modelo.parameters(), lr=lr)
criterion = nn.MSELoss()
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer, patience=5, factor=0.5, verbose=True)
mejor_val_loss = float("inf")
sin_mejora = 0
mejor_estado = None
for epoch in range(epochs):
# Train
modelo.train()
train_loss = 0
for xb, yb in train_dl:
xb, yb = xb.to(device), yb.to(device)
pred = modelo(xb)
if pred.dim() > 1 and yb.dim() == 1:
pred = pred.squeeze(-1)
loss = criterion(pred, yb)
optimizer.zero_grad(); loss.backward(); optimizer.step()
train_loss += loss.item() * len(xb)
train_loss /= len(train_ds)
# Validation
modelo.eval()
val_loss = 0
with torch.no_grad():
for xb, yb in val_dl:
xb, yb = xb.to(device), yb.to(device)
pred = modelo(xb)
if pred.dim() > 1 and yb.dim() == 1:
pred = pred.squeeze(-1)
val_loss += criterion(pred, yb).item() * len(xb)
val_loss /= len(val_ds)
scheduler.step(val_loss)
if epoch % 10 == 0:
print(f"Epoch {epoch:3d}/{epochs} | train={train_loss:.4f} val={val_loss:.4f}")
if val_loss < mejor_val_loss:
mejor_val_loss = val_loss
sin_mejora = 0
mejor_estado = {k: v.cpu().clone() for k, v in modelo.state_dict().items()}
else:
sin_mejora += 1
if sin_mejora >= patience:
print(f"Early stopping en epoch {epoch}")
break
modelo.load_state_dict(mejor_estado)
return modelo, scaler, y_scaler
# ── Inferencia ────────────────────────────────────────────────────────────────
@torch.no_grad()
def predecir_lstm(modelo, X_test, scaler, y_scaler):
"""Predice con el modelo LSTM entrenado y desnormaliza."""
device = next(modelo.parameters()).device
if X_test.ndim == 2:
X_sc = scaler.transform(X_test)[:, :, np.newaxis]
else:
shape = X_test.shape
X_sc = scaler.transform(X_test.reshape(-1, shape[-1])).reshape(shape)
x_t = torch.tensor(X_sc, dtype=torch.float32).to(device)
modelo.eval()
pred_norm = modelo(x_t).cpu().numpy()
if pred_norm.ndim == 1:
pred_norm = pred_norm.reshape(-1, 1)
return y_scaler.inverse_transform(pred_norm).flatten()
9. Multi-step forecasting: estrategias y error por horizonte
El forecasting de un solo paso (h=1) es mas sencillo que predecir multiples pasos adelante. A mayor horizonte, mayor incertidumbre.
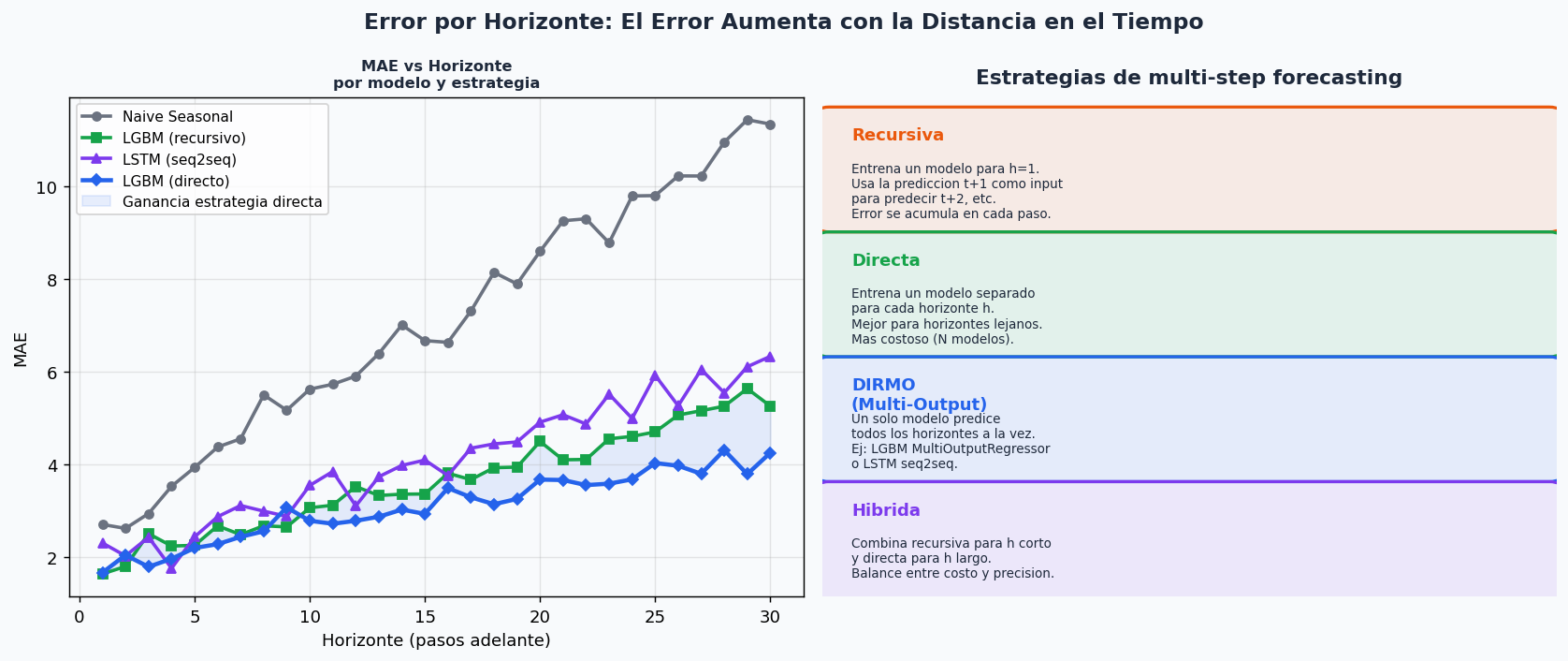
import numpy as np
from sklearn.multioutput import MultiOutputRegressor
from lightgbm import LGBMRegressor
def forecast_recursivo(modelo_h1, X_last_window, n_steps):
"""
Estrategia recursiva: el modelo predice h=1, la prediccion
se agrega al final de la ventana para predecir el siguiente paso.
Ventaja: un solo modelo.
Desventaja: el error se acumula en cada paso.
"""
ventana = list(X_last_window.flatten())
preds = []
for _ in range(n_steps):
x_input = np.array(ventana[-len(X_last_window[0]):]).reshape(1, -1)
pred = float(modelo_h1.predict(x_input)[0])
preds.append(pred)
ventana.append(pred)
return np.array(preds)
def forecast_directo(X_train, y_train_multi, X_test, n_horizontes):
"""
Estrategia directa: entrena un modelo separado para cada horizonte.
y_train_multi: [n_muestras, n_horizontes]
"""
modelos = []
predicciones = []
for h in range(n_horizontes):
m = LGBMRegressor(n_estimators=200, learning_rate=0.05, verbose=-1)
m.fit(X_train, y_train_multi[:, h])
modelos.append(m)
predicciones.append(m.predict(X_test))
return np.column_stack(predicciones), modelos # [n_test, n_horizontes]
def forecast_multioutput(X_train, y_train_multi, X_test):
"""
Estrategia DIRMO (Direct Multi-Output): un modelo con multiples salidas.
MultiOutputRegressor entrena un LGBM por cada horizonte internamente.
"""
base = LGBMRegressor(n_estimators=200, learning_rate=0.05, verbose=-1)
modelo = MultiOutputRegressor(base, n_jobs=-1)
modelo.fit(X_train, y_train_multi)
return modelo.predict(X_test) # [n_test, n_horizontes]
def evaluar_por_horizonte(y_true, y_pred, etiqueta="modelo"):
"""
Calcula MAE por cada horizonte de prediccion.
Util para visualizar como sube el error con la distancia.
"""
n_horizontes = y_true.shape[1] if y_true.ndim > 1 else 1
if y_true.ndim == 1:
y_true = y_true.reshape(-1, 1)
y_pred = y_pred.reshape(-1, 1)
maes = [np.mean(np.abs(y_true[:, h] - y_pred[:, h])) for h in range(n_horizontes)]
print(f"\n{etiqueta} — MAE por horizonte:")
for h, mae in enumerate(maes, 1):
barra = "█" * int(mae * 5)
print(f" h={h:2d}: {mae:.4f} {barra}")
return np.array(maes)
10. Pipeline completo para una competencia de forecasting
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
def pipeline_forecasting_competencia(
csv_path: str,
fecha_col: str,
target_col: str,
n_test: int = 30,
usar_lstm: bool = False,
):
"""
Pipeline reproducible para una competencia de forecasting.
Pasos:
1. Cargar y visualizar
2. Test de estacionariedad
3. ACF/PACF
4. Baselines
5. Features temporales + LGBM
6. (Opcional) LSTM
7. Evaluacion y comparacion
"""
# 1. Cargar
df = pd.read_csv(csv_path, parse_dates=[fecha_col], index_col=fecha_col)
df = df.sort_index()
print(f"Dataset: {len(df)} filas | {df.index.min()} → {df.index.max()}")
print(f"Nulos: {df[target_col].isnull().sum()}")
print(f"Freq inferida: {pd.infer_freq(df.index)}")
# 2. Split temporal (nunca aleatorio)
serie_train = df[target_col].iloc[:-n_test]
serie_test = df[target_col].iloc[-n_test:]
print(f"Train: {len(serie_train)} | Test: {len(serie_test)}")
# 3. Baselines
print("\n── Baselines ──")
y_train_arr = serie_train.values
y_test_arr = serie_test.values
resultados_base, mejor_baseline = BaselinesForecast.comparar(
y_train_arr, y_test_arr, periodo_estacional=7
)
# 4. LGBM con features temporales
print("\n── LGBM con features temporales ──")
lags = [1, 2, 3, 7, 14, 21, 28, 90]
rolling = [7, 14, 30]
modelo_lgbm, pred_lgbm, y_te, feat_imp = pipeline_forecast_ml(
df.iloc[:-n_test].copy(),
df.iloc[-n_test:].copy(),
target_col, lags, rolling,
)
# 5. LSTM si se solicita (requiere suficientes datos)
if usar_lstm and len(serie_train) > 500:
print("\n── LSTM ──")
W = 30
X, y = crear_dataset_ventana(df[target_col].values, window=W, horizonte=1)
split = len(X) - n_test
X_tr, X_te = X[:split], X[split:]
y_tr, y_te_lstm = y[:split, 0], y[split:, 0]
modelo_lstm, scaler, y_scaler = entrenar_lstm(
X_tr, y_tr, X_te, y_te_lstm,
hidden_size=64, num_layers=2, epochs=100, patience=15,
)
pred_lstm = predecir_lstm(modelo_lstm, X_te, scaler, y_scaler)
mae_lstm = np.mean(np.abs(pred_lstm - y_te_lstm))
print(f"LSTM MAE: {mae_lstm:.4f}")
print("\n── Resumen ──")
mae_lgbm = np.mean(np.abs(pred_lgbm - y_test_arr[:len(pred_lgbm)]))
mae_base = resultados_base[mejor_baseline]["MAE"]
ganancia = (1 - mae_lgbm / mae_base) * 100
print(f"Mejor baseline: {mejor_baseline} | MAE={mae_base:.4f}")
print(f"LGBM+features: MAE={mae_lgbm:.4f} ({ganancia:+.1f}% vs baseline)")
return modelo_lgbm, feat_imp
# Ejemplo de uso:
# modelo, imp = pipeline_forecasting_competencia(
# "ventas_diarias.csv",
# fecha_col="fecha",
# target_col="ventas",
# n_test=30,
# )
Dashboard resumen
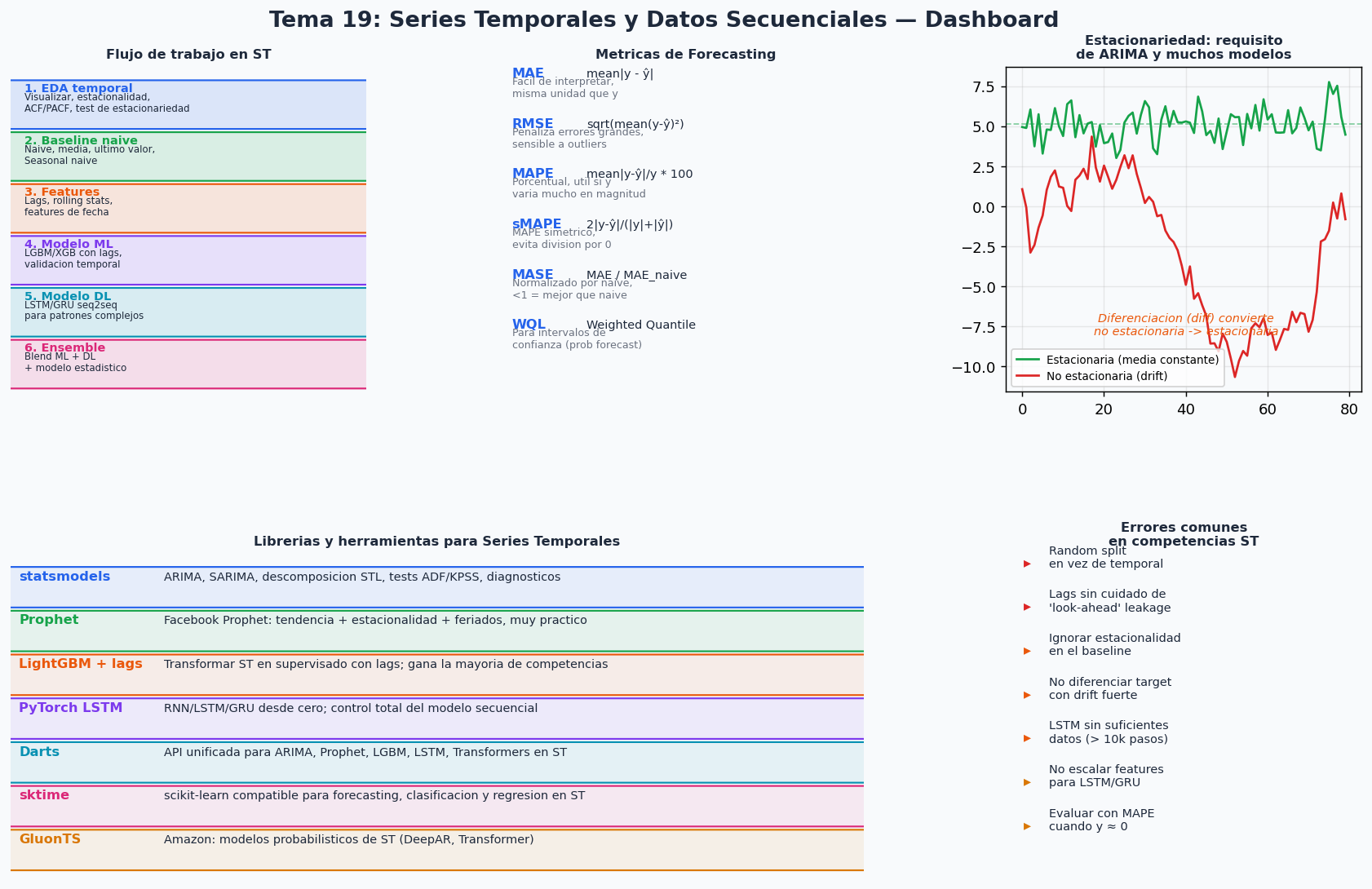
Recursos recomendados
- Kaggle Learn — Time Series: forecasting con features de lag y modelos gradient boosting, completamente practico
- statsmodels — TSA: ARIMA, SARIMA, descomposicion STL, tests ADF/KPSS, diagnosticos completos
- Tutorial de LSTM en PyTorch: implementacion paso a paso de redes recurrentes con PyTorch
- Darts — libreria de forecasting: API unificada para ARIMA, Prophet, LGBM, LSTM y Transformers en series temporales
- Forecasting: Principles and Practice (Hyndman): libro gratuito online, el texto de referencia de forecasting moderno
Navegacion
← 17. Etica y IA Responsable | Fin de la Ruta de Aprendizaje